
iii.分析手法の選定
機械学習の手法には、大きく分けて3つのグループがあります。それは、「教師あり学習」と「教師なし学習」、「半教師あり学習」です。
教師あり学習とは、有用な正解ラベルとデータから抽出した特徴量の両方を学習させ、ラベルの付いていない未知のデータに対して、そのラベルを推測する手法です。この手法には、大量の正解付きデータが必要という大きな制約がありますが、人間の期待する分類に近い結果が得られやすいというメリットがあります。
二つ目の教師なし学習とは、正解ラベルなしのデータから何らかの規則性を見出し、類似度の高い(データ間の距離の近い)データ同志でクラスタをつくる手法を指します。いわゆるデータマイニングの意味合いが強い手法です。正解ラベルを必要としないため、教師あり学習よりもスタート時点での敷居が非常に低いことがメリットとしてあります。ただし、教師あり学習にも同じことが言えますが、データ分類には客観的・絶対的な区分はつくれないという、「醜いアヒルの子の定理(Ugly Duck Theorem)」を常に意識する必要があります。データ分類分析は、どこに着目して行われたのかという文脈が最も大切です。
三番目の半教師あり学習には、二つのグループがあります。一つ目は、一部にラベルが付与されているデータセットに対して、教師あり学習と教師なし学習を組み合わせる手法です。ラベルデータからパターンを学習し、ラベルなしデータに対しても同様なロジックでラベルを付与する手法です。ラベルなしデータを効果的に用いることで、教師あり学習はラベル生成コストが高いという欠点を補いつつ、高精度にラベルを付与可能なモデルを作ることを目的としています。
半教師あり学習のもう一つが深層学習(Deep Learning)と呼ばれる領域の手法です。深層学習とは、パーセプトロンと呼ばれるニューロンを模倣した数学モデルを多層に積み重ねたモデルです。層は入力層、中間層、出力層に分類され、ラベルは出力層でのみ参照されるため、半教師あり学習に分類されます。(教師あり学習に分類する場合もあります。)このモデルの大きな特徴は、モデルが自動的に特徴量をデータから抽出してくれる点にあります。これにより、分析者の経験や勘といった曖昧なものを排除できるというメリットがあります。
以上が分析手法の簡単な紹介になります。各手法のメリットとデメリットを把握し、データに合わせた分析を行うように心がけましょう。
iv.アルゴリズムの選定
大枠の分析手法を選定した後には、具体的なモデルをつくるためのアルゴリズムを選定する作業に移ります。この作業で意識するべきことは、「ノーフリーランチ(No-Free-Lunch)定理」です。これは簡単に言うと、「あらゆる問題において性能の良い汎用モデルをつくることは不可能である」ことを数学的に証明した定理です。したがって、分析内容ごとにアルゴリズムの選定やパラメータを最適化させる作業が必要であることを示唆しています。
問題に適したアルゴリズムの選定は、原則的には実際の分析業務を通しての経験から学ぶところが非常に大きいですが、機械学習分野で良く使われる言語のpython言語の中の機械学習モジュールの一つであるscikit-learnは一つの指標として以下のようなフローチャートを示しています。
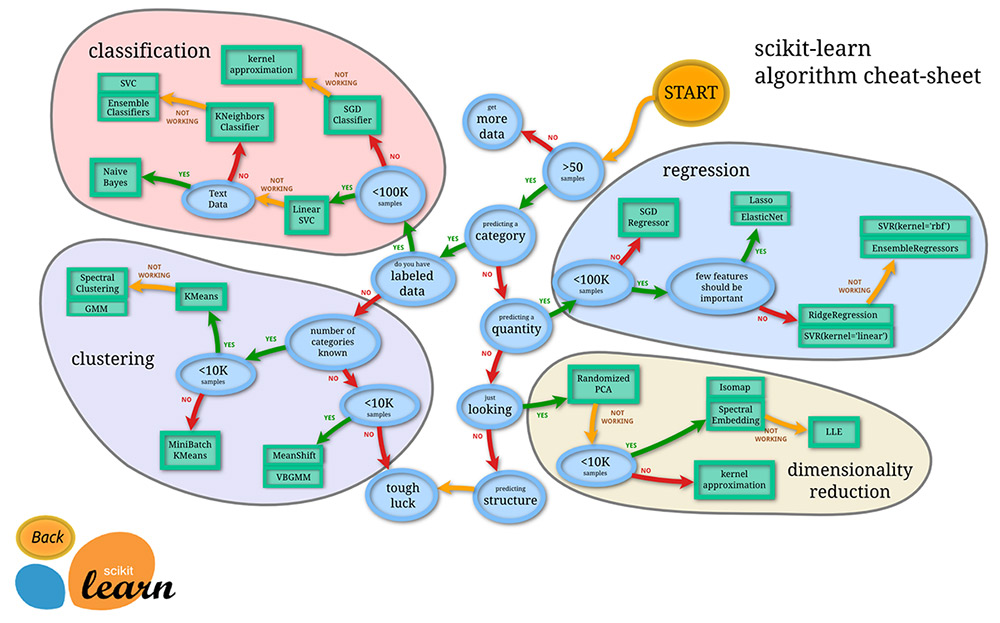
このチャートで全ての問題に対して適切なアルゴリズムを見つけられる訳ではありませんが、何か新しい分析業務を始める際には大変参考になる資料かと思います。


















