
以前は、こちらの記事で説明可能AI(XAI)について解説しました。
今回解説するNeurIPSの論文は、以下です。
How does This Interaction Affect Me? Interpretable Attribution for Feature Interactions
和訳:特徴量の相関関係を考慮できるモデル非依存型解釈手法
論文リンク:How does This Interaction Affect Me? Interpretable Attribution for Feature Interactions
Part of Advances in Neural Information Processing Systems 33 (NeurIPS 2020)
著者:Michael Tsang, Sirisha Rambhatla, Yan Liu
論文の概要
機械学習において、ブラックボックス性との反対語である「透明性」(transparency)は、入力されたデータがどのような根拠を辿って予測出力に繋がるのか説明できることを指しています。各特徴量がどの程度予測結果に寄与するのかを説明することが1つの代表的な手段です。しかし、特徴量間で相関関係(相互作用)が絡んでくると、特徴量の重要度を正しく説明することが難しくなります。
これまでに、相関関係に着目したモデル解釈手法が開発されていますが、これらは肝心の解釈の精度が不足している、あるいは、モデル依存の手法であることが多いです。
そこで、本論文では、特徴量の相関関係を考慮しながらブラックボックス・モデルを説明する斬新な手法 Archipelagoを提案しています。特徴として、高い解釈性(interpretable)、モデル非依存(model-agnostic)、高い柔軟性(flexibility)、実社会の課題への適用可能性(scalability)が挙げられています。
Archipelagoの性能は、感情分析、画像分類、広告レコメンドなどのタスクを通じて検証され、従来方法よりも優れた解釈性を示されています。
また、解釈の結果をインタラクティブに可視化するフレームワークも開発されており、それを用いると、ニューラルネットワークに関する新たな発見に導きます。
解釈手法の特徴
この手法の名前にその強みと工夫が反映されています。Archipelago は特徴量間の相関を検出した上で切り離すことによって、従来よりも高性能のモデル解釈を提供することができます。” Archipelago”は特徴量の「島(island)」から由来します。
Archipelagoは相互補完する2つの部分から成り立ちます。
①ArchAttributeは、特徴量の寄与度を導き出すための部分です。モデル非依存であり、解釈性が高く、ランタイムが短いのが特徴的です。
②ArchDetectは、特徴量間の相関関係を検出する役割を果たします。特徴量のペアの相互作用にのみ着目し、逆に、解釈困難で混乱を招きやすい高次元の相互作用を除外します。
それぞれの部分は解釈もしくは相関関係を導き出すためには、ある程度の近似を課しているのにもかかわらず、実世界の教師ありデータに適用したときに、それまでの最先端の手法よりも高い解釈性を示しました。
一方で、画像分類モデルの解釈を行う際には、Archipelagoは類似ピクセルのグルーピングのみ行いますが、より精密なピクセル・レベルでの解釈を行う手法が他にあるのが現状です。
モデル非依存な解釈手法とは
「モデル固有の解釈手法」と「モデル非依存な解釈手法」がありますが、ここでは、Archipelagoの特徴の1つである「モデル非依存」はなぜ重要なのかを説明します。
モデル非依存とは、機械学習のモデルから説明性(解釈や可視化の結果)を分離させることです。その利点はなんと言っても柔軟性が高いことです。次のようにより細かくカテゴライズすることができます。
- モデルの柔軟性 (Model flexibility) :ニューラルネットワークや決定木のアンサンブル学習器など、あらゆる機械学習モデルの解釈に使えます。
- 説明の柔軟性 (Explanation flexibility) :モデルの説明が特定の形式に縛られることがない。特徴量の重要度を明らかにしたい時もあれば、線形の関係を持たせることが役に立つこともあります。
- 表現の柔軟性 (Representation flexibility) :解釈する対象の性質によって、表現を合わせることができる。例えばテキスト分類の説明には個々の単語やフレーズを矢印で結ぶような表現で説明することがある一方で、シンプルな売上予測に対してはわかりやすく、特徴量の重要度を定量的にプロットする。
以上により、解釈性を重視するユーザーはモデルの選択肢が限定されることがないです。また、データサイエンティストが課題を解決する際に、複数の機械学習モデルを試して、その予測精度だけではなく、解釈性を比較することがあります。
これに対して、モデル固有の解釈方法を使う欠点は、使用できるモデルが制限されてしまうこと、後から他のモデルに切り替えることが難しくなることです。モデル固有の解釈性だけを重視してモデルを選ぶと、他の機械学習モデル値と比較して予測性能が低い場合は困ってしまいます。
モデル固有の解釈手法の一例はランダムフォレストの”Feature Importance”です。ランダムフォレストを実装するライブラリScikit-learnには、モデルの学習と同時に特徴量の重要度を可視化する機能”Feature Importance”が含まれています。また、自然言語処理モデルのAttentionでは時刻ごとに情報の重みを設定しており、これもモデル固有の解釈手法です。
参考:https://hacarus.github.io/interpretable-ml-book-ja/agnostic.html#fn26
Archipelagoによる解釈例
Archipelagoから出力される解釈結果は、普段から機械学習を活用する者にも、初心者にも理解できるような分かりやすさです。以降、いくつかの具体例を示します。
■感情分析
下図では、感情分析で最もよく知られているデータセットの1つであるStanford Sentiment Treebank(SST)から無作為抽出された文について、BERTという難解な大規模言語モデルのポジネガ判定の結果を解釈しています。
フレーズ単位の相互作用と単語単位での相互作用を、2つの軸で、5段階の感情で評価をしています。図の矢印が相互作用を表し、色の濃さは特徴量の予測への寄与度を表します。この中には、強く相関している要素や長い単語列の相関関係もあります。例えば、”lousy” と “un” は両方濃い赤色(強くネガティブ)であると同時に、その距離はかなり離れています。
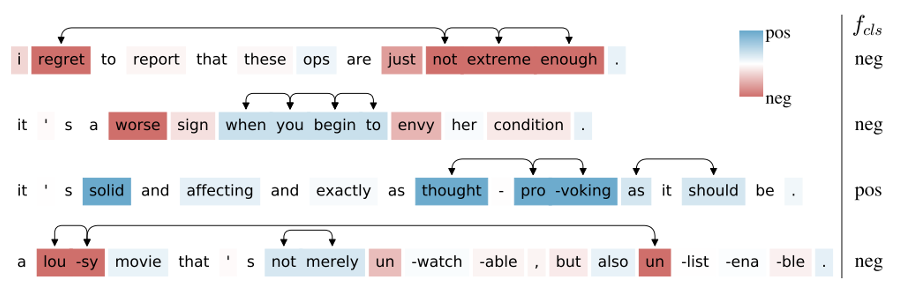 SSTから抽出されたテスト文にBERTを適用した結果をArchipelagoで解釈した結果。青はポジティブ、赤はネガティブです。Archipelagoへの入力はブラックボックス・モデル(関数fで表現)とデータ変数(特徴量)xです。(論文より抽出)
SSTから抽出されたテスト文にBERTを適用した結果をArchipelagoで解釈した結果。青はポジティブ、赤はネガティブです。Archipelagoへの入力はブラックボックス・モデル(関数fで表現)とデータ変数(特徴量)xです。(論文より抽出)
■画像分類
下図には、Archipelago による、COVID-19に特化した医療診断AI(COVID-NET)の解釈の例が示されています。ここでは、COVID-19陽性と診断された患者の胸部X線画像を無作為抽出し、COVIDによる肺炎と通常のX線画像を正確に区別することができます。色つきの枠は「寄与レベル」ごとに陽性に寄与する特徴量を表します。また、一番寄与の大きい緑の枠に着目して、特徴量の相関を検出しています。
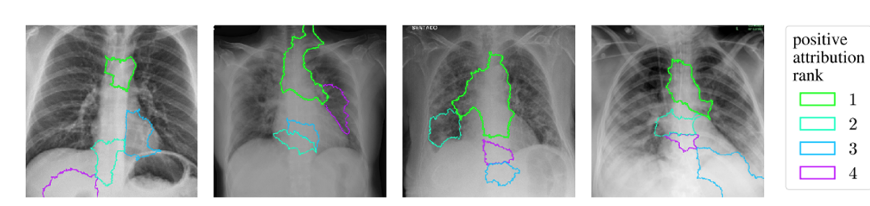 Archipelago による、COVID-19に特化した医療診断AI(COVID-NET)の解釈 (論文より抽出)
Archipelago による、COVID-19に特化した医療診断AI(COVID-NET)の解釈 (論文より抽出)
■ウェブ広告レコメンド・最適化
下図は、Archipelagoによるレコメンド・システムの解釈結果を示します。モデルには広告レコメンド分野で最先端のAutoInt モデルを用いています。
ここでは、”device_id” と“banner_pos”の間の正の相関を見つけ出しています。これは、バナー・ポジションをユーザー・デバイスIDに基づいて決定することを意味します。本タスクには正解がなかったので、新たな発見です。
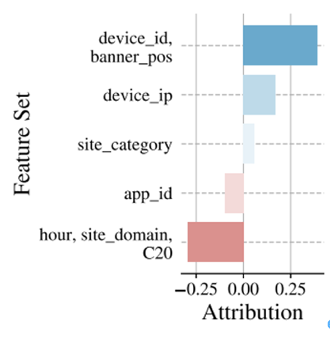 広告レコメンドのAvazu データセットにおいて、属性間の相関の強さや全体の寄与をArchipelagoが解明しています。(論文より抽出)
広告レコメンドのAvazu データセットにおいて、属性間の相関の強さや全体の寄与をArchipelagoが解明しています。(論文より抽出)
解釈結果の可視化
本研究では、Archipelagoの解釈をインタラクティブに可視化するフレームワークが開発されています。一般的に、解釈結果を可視化する際に、特徴量ペア同士の相互作用の「距離」に対して閾値が設定されています。Archipelagoでは、ユーザーが深堀しやすくなる工夫が取り入れられています。
下図に見えるように、UIにスライダーを設けており、スライダーを使って閾値を動かすことで、相互作用はどの時点で起きるのかを知ることができ、判断がしやすくなります。
この例では、スライダーを動かすことで、初期的に“predictable” と “but”がネガティブと解釈されていたのが、閾値を変えることで、ポジティブなフレーズ“jumps with style”と相互作用することによって今度はポジティブに転じています。
相互作用の検出は一度のみ走らせるので、インタラクティブな可視化も素早く機能します。
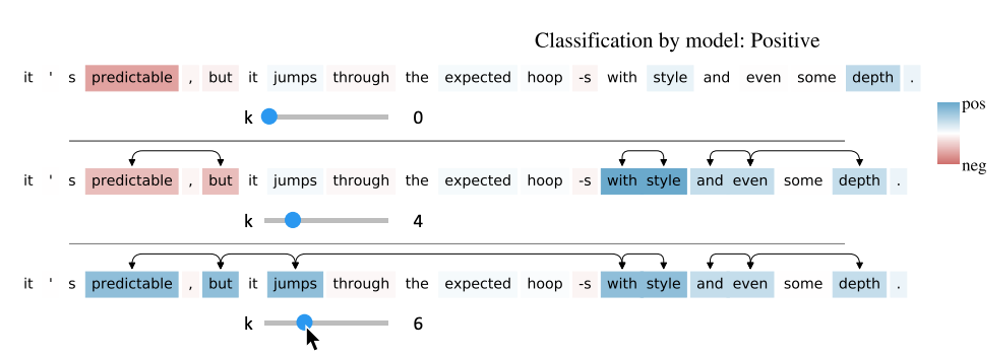 UI上でスライダーを動かすことで、相互作用の閾値によって解釈がどう変わるかを可視化することができます。
UI上でスライダーを動かすことで、相互作用の閾値によって解釈がどう変わるかを可視化することができます。













