
こんにちは!突然ですが、皆さんは下のような二種類の時系列データを判別できるような特徴量を抜き出したいときに何を考えますか?そしてどうやって特徴量を抽出しますか?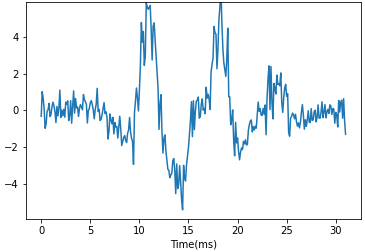
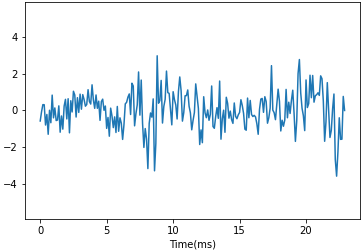
私はパッと見て次の手法を使えば特性が取り出せると思いました。
- ピークの数 → k近傍法
- ノイズの大きさ → 分散統計量
- 時系列方向で周期成分の大きさ → Wavelet変換
しかし、当然これだけでは十分な数の特性を網羅できていないでしょうし、適切な特性を抜き出すためにパラメータチューニングを行う必要があります(例えば、Wavelet変換であれば適切な基底関数を選ぶ必要があります)。
このように時系列データの特徴量エンジニアリングは調べることが無限にあり、どの特徴量を算出するかを考えているだけで日が暮れてしまいます。また、抜き出す特徴量が決まったとしてもモノによっては計算が複雑で実装に時間がかかってしまう場合もあります。
そんなときに有力な選択肢になるのが Pythonのパッケージである tsfreshです。これはたった数行のコードで時系列データから大量の特徴量計算を行ってくれるパッケージです。
前置きが長くなりましたが、今回はこの tsfreshの使い方について書いていきたいと思います。
tsfreshができること・できないこと一覧
tsfreshができることは次の通りです(全てではなく、一部分を抜粋しています)
- 時系列データからユニークな番号ごとに約800個程度の特徴量を生成
- 時系列データが複数種類あればその数分の特徴量を生成
- 無限大や欠損値を一行で処理
- ターゲットとの相関性を有意差検定によって判別し、相関性がない特徴量を削除
- 生成する特徴量を選別
- 移動窓ごとにユニーク番号を振り直す
逆に tsfreshができないことは次の通りです
- 様々なデータフレームの特徴量変換(入れるデータは特定の型でないといけない)
- 生成された特徴量の意味を理解(数学の知識が必要)
- 生成された特徴量同士の相関性を調査(多重共線性の誘発)
それでは説明していきます。
環境構築
tsfreshパッケージはpip installでダウンロードできます
pip install tsfreshtsfreshに入れるデータの準備
tsfreshが変換可能なデータの型は pandas.DataFrameか Dict型、またはこれらのデータが格納できないような大規模なデータの場合は dask.dataframeまたは pysparkのいずれかです。ここでは、pandas.DataFrameに絞って説明します。
tsfreshで特徴量生成をするために必ず必要なカラムは次の三つです。プライマリーキーはid×time である必要があります。
- 一つ一つの時系列データを識別するユニークな番号:id
- 時系列データの時間(過去と未来を表現する軸):time
- 時系列データの値(複数列あっても可):value
pandas.Dataframe風に書くと次のようになります。
| id | time | value |
| A | 1 | 0.2 |
| A | 2 | -1.0 |
| A | 3 | 1.3 |
| B | 1 | 2.1 |
| B | 2 | 0.3 |
| B | 3 | 1.8 |
また、次のような pandas.DataFrameも tsfreshで簡単に特徴量生成を行うことができます。
A)プライマリーキーがユニーク番号×時間軸であるデータで複数の時系列データを持つ pandas.DataFrame(例えば、3軸加速度センサーのそれぞれの加速度変化量X, X, Z)
| id | time | X | Y | Z |
| A | 1 | 0.1 | 0.5 | 0.2 |
| A | 2 | -0.3 | 0.7 | -0.3 |
| A | 3 | 0.5 | 0.5 | -0.3 |
| B | 1 | 0.2 | 0.6 | 0.0 |
| B | 2 | 0.3 | 0.7 | 0.1 |
| B | 3 | -0.4 | 0.4 | -0.4 |
B)プライマリーキーがユニーク番号×時間軸×時系列データの種類のカラムである pandas.DataFrame(上表の X, Y, Zを縦持ち化したもの)
| id | time | key | value |
| A | 1 | X | 0.1 |
| A | 2 | X | -0.3 |
| A | 3 | X | 0.5 |
| A | 1 | Y | 0.5 |
| A | 2 | Y | 0.7 |
| A | 3 | Y | 0.5 |
| A | 1 | Z | 0.2 |
| A | 2 | Z | -0.3 |
| A | 3 | Z | -0.3 |
| B | 1 | X | 0.2 |
| B | 2 | X | 0.3 |
| B | 3 | X | -0.4 |
| B | 1 | Y | 0.6 |
| B | 2 | Y | 0.7 |
| B | 3 | Y | 0.4 |
| B | 1 | Z | 0.0 |
| B | 2 | Z | 0.1 |
| B | 3 | Z | -0.4 |
C)pandas.DataFrameを時系列データの種類ごとに辞書として格納した Dict
{ “X”:
| id | time | value |
| A | 1 | 0.1 |
| A | 2 | -0.3 |
| A | 3 | 0.5 |
| B | 1 | 0.2 |
| B | 2 | 0.3 |
| B | 3 | -0.4 |
,”Y”:
| id | time | value |
| A | 1 | 0.5 |
| A | 2 | 0.7 |
| A | 3 | 0.5 |
| B | 1 | 0.6 |
| B | 2 | 0.7 |
| B | 3 | 0.4 |
,”Z”:
| id | time | value |
| A | 1 | 0.2 |
| A | 2 | -0.3 |
| A | 3 | -0.3 |
| B | 1 | 0.0 |
| B | 2 | 0.1 |
| B | 3 | -0.4 |
}
これらのデータを整形するのは Pythonである必要はありません。しかし、大量の時系列データを統合して縦持ち化するので Pythonの Pandasでやってしまうのがオススメです。Jupyter notebookや Jupyter Lab限定ですが Pandasをノーコーディングで使えるツールも開発されているのでプログラミングに自信がない人はそちらを併用するのが良いかと思います。
Pandas をノーコーディングで整形できるツール bamboolib
※こちらのツールはローカル環境でしか無料で使えないのでその点は注意してください。
特徴量生成
上記のデータが用意できたら特徴量生成を行いましょう。やることはPythonで tsfreshをインポートして tsfresh.feature_extraction.extract_features 関数を実行するだけです。 これを実行すると時系列データの種類×約800個の時系列データに関する特徴量が生成されます。
実行時間はデータ量によりますが、400個のIDに対して、各々が200~300程度の長さを持つ時系列データでは約40秒で生成できました。
ここで注意しないといけないのは用意したデータの構造で tsfresh.feature_extraction.extract_features内の変数指定が微妙に変わることです。
A)プライマリーキーがユニーク番号×時間軸であるデータで複数の時系列データを持つ pandas.DataFrameの場合
from tsfresh.feature_extraction import extract_features
features = extract_features(
timeseries_container=dataframe,
default_fc_parameters=None,
column_id='id',
column_sort='time',
column_kind=None,
column_value=None
)B)プライマリーキーがユニーク番号×時間軸×時系列データの種類のカラムである pandas.DataFrameの場合
column_kindに時系列データの種類のカラム名を、column_valueに時系列データの値のカラム名を指定する必要があります。
from tsfresh.feature_extraction import extract_features
features = extract_features(
timeseries_container=dataframe,
default_fc_parameters=None,
column_id='id',
column_sort='time',
column_kind='key',
column_value='value'
)C)pandas.DataFrameを時系列データの種類ごとに辞書として格納した Dictの場合
Bとは違ってcolumn_kindに時系列データの種類のカラム名指定する必要はありません。
from tsfresh.feature_extraction import extract_features
features = extract_features(
timeseries_container=dataframe,
default_fc_parameters=None,
column_id='id',
column_sort='time',
column_kind=None,
column_value='value'
)いずれのケースでも生成されるデータフレームは次のような、プライマリーキーがidで、カラムに特徴量を持つものになります。
| id | X_feature_1 | … | X_feature_n | Y_feature_1 | … | Y_feature_n | Z_feature_1 | … | Z_feature_n |
| A | … | … | … | … | … | … | … | … | … |
| B | … | … | … | … | … | … | … | … | … |
特徴量選択
生成した特徴量を使って機械学習を行う場合、機械学習モデルの精度を良くするために次の工夫が必要になります。
- 欠損値、異常値の処理
- 目的変数と相関性がある特徴量を選択
tsfreshにはこれを自動で処理できる関数があります。
- 欠損値、異常値(無限大)を処理する関数 tsfresh.utilities.dataframe_functions.impute
from tsfresh.utilities.dataframe_functions import impute
impute(features)- 目的変数と相関性のある特徴量を選択する関数 tsfresh.feature_selection.selection
目的変数は各IDごとに与えられた正解ラベルを関数内の変数yで指定します。正解ラベルが3種類以上あるようなマルチクラス分類では multiclassをTrueとし、n_significantに[クラス数-1]の整数を指定します
from tsfresh import select_features
features_filter = select_features(
X=features,
y=target,
multiclass=False,
n_significant=None
)これらを実行すると特徴量の数が大幅に減り、すなわち次元の呪いが緩和され、機械学習の評価スコアが良くなるケースが多いです。ただし、場合によっては特徴量が全て消えてしまうので一度実行してみてから実際に使うかどうかを判断するのが良いかと思います。
ちなみに、特徴量の生成から目的変数に対しての選別までを一つの関数で実行することも可能です。
from tsfresh import extract_relevant_features
features = extract_relevant_features(
timeseries_container=dataframe,
y=target,
default_fc_parameters=None,
column_id='id',
column_sort='time',
column_kind=None,
column_value=None
)生成する特徴量を選別
実際の運用で特徴量生成を行うときには毎回800個もの特徴量を生成するのではなく、機械学習モデルに必要なもののみを生成したくなると思います。tsfreshにはそのための機能も当然あります。
まず、特徴量生成→選別までを行った pandas.DateFrameに対して残っている特徴量カラムの辞書を生成します。(tsfresh.feature_extraction.settings.from_columns)
from tsfresh.feature_extraction.settings import from_columns
settings = from_columns(features)これで生成された辞書を特徴量生成の際に default_fc_parametersで指定すれば選別済の特徴量のみを生成できます。
from tsfresh.feature_extraction import extract_features
selected_features = extract_features(
timeseries_container=dataframe,
default_fc_parameters=setting,
column_id='id',
column_sort='time',
column_kind=None,
column_value=None
)移動窓ごとの特徴量生成
時系列を一定区間窓ごとに取り出して少し先の状態を予測するという手法が多くの時系列予測モデルで利用されています。これまで紹介してきたコードは、時系列データ全体を使って特徴量生成を行うものでしたが、これを個別のIDで移動窓ごとに行えるようにデータを整形する関数が tsfreshにあります(tsfresh.utilities.dataframe_functions.roll_time_series)。
変数の min_timeshiftと max_timeshiftでは移動窓幅の長さをどこから、どこまでを計算してよいかを指定します。
from tsfresh.utilities.dataframe_functions import roll_time_series
df_rolled = roll_time_series(
df_or_dict=dataframe,
column_id='id',
column_sort='time',
max_timeshift=None,
min_timeshift=0
)これで生成された pandas.DateFrameにはidのカラムにユニーク番号に加えてどの移動窓であるかの番号も付与されて、プライマリーキーがID×移動窓となります。なので、これを使って特徴量生成を行うことで、ユニーク番号かつ移動窓ごとの特徴量生成を行うことができます(ただし、行数が爆増するので実行時間には注意が必要です)。
ということで tsfreshでできる時系列データの特徴量エンジニアリングをまとめてみました。
本ブログではこの tsfreshと弊社の自動機械学習ツールである ForecastFlowを組み合わせてほぼノンコーディングで機械学習モデルを構築した例もご紹介していますので、併せてご覧ください。是非こちらも読んでいただき、tsfreshの威力を実感していただければと思います。

弊社開発の自動機械学習ツールForecastFlowはこちらから
今なら90日間の無料トライアル実施中です!
長くなりましたが、最後まで読んでいただきありがとうございました。













