
2019年に、OpenAIからGPT(Generative Pre-trained Transformer)が公開されました。事前学習を取り入れた大規模自然言語モデルで、文章の内容や背景を学習し、自然言語の生成と理解を行う驚異的な能力を発揮します。

■GPTの概要
GPTには、Transformerのデコーダの部分が使用されています。事前学習では、インターネットから取得された大量のテキストデータを使用して、モデルが次にどの単語が来るべきかを予測するように訓練するという方法で行われます。入力された単語系列をTransformerのデコーダーに送り、各時刻テップで次の単語を予測します。一度予測された単語が次の時刻ステップの入力の一部となります。過去の単語列から次の単語を予測するのを繰り返すことで、文章を生成できるようになります。
事前学習(基礎訓練)には膨大データ量と計算量が必要でしたが、学習済みのGPT-を転移学習に使用すると、モデル再構築やアルゴリズムの最適化のプロセスを省くことができます。ネットワーク下流のパラメータの微調整を通じて、GPTは文章生成、質問応答、文章要約、調査、ソースコード生成など幅広い言語タスクで人間に匹敵する精度を達成することができます。
GPT、GPT-2、GPT-3、GPT-4 と相次いでバージョンアップしました。それに伴い、モデルのサイズ、つまりパラメータの数が以下のように上昇しています。
GPT-1:1億1700万 → GPT-2:15億 → GPT-3:1750億 → GPT-4:1兆以上(非公開)
そして、スケール則のとおり、モデルの学習にはますます大規模なデータと計算能力を必要とします。例えば、GPT-3モデルを学習するために約45TB にもなる大規模なテキストデータ(コーパス)を事前学習します。その多くがウェブからスクレイピングしたデータ、電子書籍、ウィキペディア、ウェブページ、ブログ記事、コードなどから来ています。このような巨大データセットには何千億もの単語や語句が含まれています。
出典:https://arxiv.org/abs/2005.14165
■GPTの学習の仕組み
どのバージョンも基本的な考え方が類似していますが、以下で解説する学習と文章の自動生成の仕組みは基本的にGPT-3以降に関する内容とします。
GPTの事前学習は膨大な量のデータを用いて、教師なし学習(自己教師学習)を行います。データをそのまま丸暗記するわけではなく、いったん最小単位(形態素、単語)に分割した後に、「ある単語列の後に来る単語を予測し、自動的に文章を完成」できるように学習をします。
正確にいうと、あらゆる文脈において、「ある単語列の後にある単語が現れる確率」を学習します。
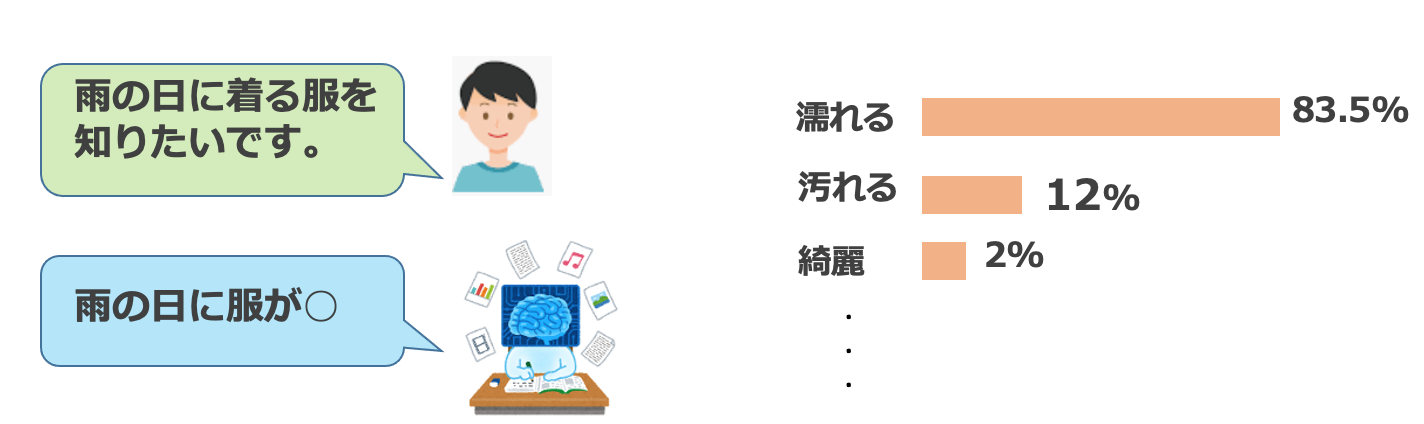
例えば、“I”、“need”、“ice”、“because”、“my”、“drink” において、“is” という単語系列の次に来る単語を予測するケースを考えましょう。出力値は「その単語が次に来る確率」であり、今回の場合、“hot”:50%、“warm”:30%、“good”:15%、“cold”:5% になったと仮定します。そうすると、“I need ice because mydrink is” の後に続く単語は“hot” が尤もらしい候補で、“warm” はまあまあ可能性がある、“good” や“cold” は確率が低いと推測できます。
あるいは、単語系列 ”After”, ”running”, ”I”, ”am” に続く単語の確率が”tired”:40%,”hot”:30%,”thirsty”:20%, ”angry”:5%,”empty”:5% になったと仮定すると、”tired”、”hot” は可能性が高い、 ”angry”、”empty” は可能性が低いということを学習しようとします。
大量の文章を読み込んで、上記のような「次の単語を統計的に予測する」という「穴埋め問題」をひたすら繰り返すと、AIは単語間の出現確率の組み合わせを学習できるようになります。
下図では、ランダムな位置で文章の後半を隠し(マスキング)、前半部分を頼りに後半の単語を当てる「穴埋め問題」を示しています。教師なし学習なので、穴埋めの問題と回答からなるデータセットを自ら自動的に生成しています。
学習前のGPTのパラメータはランダムな初期値に設定されています。一般的なニューラルネットワークと同様に、学習の結果に基づいて正確な予測につながる値に更新されます。新しいデータに対しては更新後のパラメータ値を使って予測を行います。学習の途中で誤予測をしてしまった場合、出力と正解の間の誤差を計算し、その誤差を小さくするように学習することを繰り返していく中で精度を改善していきます。
■GPTによる文章生成
学習済みのGPTは数少ない「事例」(書き出しの部分)を与えられるだけで、次に来るべき単語を逐次的に予測しながら、文を自動的に完成できることが特徴的です。そうすると、あたかも人間が書いたような自然な文章を生成できます。
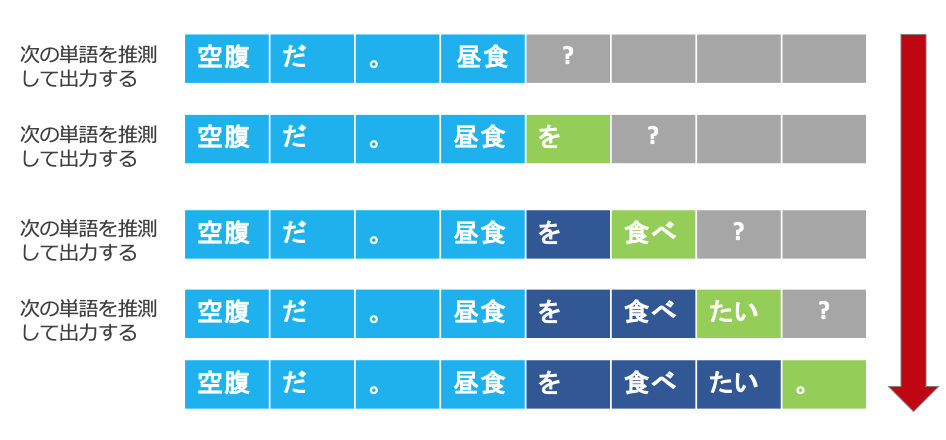
実際の出力値は「単語が次に来る確率」であり、確率の最も高い単語を採用し文を生成(確率的生成)します。下図に一例が示されています。
このように、「いくつかの事例」(= few shot)で学習できるAI を「Few Shot Learning」と呼びます。(参考論文)「Language Models are Few-Shot Learners」https://arxiv.org/abs/2005.14165
GPTは、文章の書き出しだけではなく、翻訳、質疑応答、文章の校正、文章の穴埋め、ブレインストーミング、など、自然言語からソースコードを生成する、楽譜を創作する、など様々な言語タスクに使用することはできます。例えば、プログラミングコードの最初のたった数行を与えるだけで、指定した用途に合わせてコードの続きを自動生成できます。
実際、一般のユーザーがこれらのタスクにGPTを使うのは、GPTそのものというよりもGPTを用いた対話型の文章生成AIのChatGPTです。GPTそのものを使用した際に起きる機能上の問題や不適切な出力を減らすようにファインチューニングしたモデルです。
作家がたくさんの小説(大量なテキストデータ)を読んで書き方を学び(特徴の学習)、それに基づいて新しい物語を作る(文章生成)するというイメージです。
上記のように、GPTは驚異的な文章能力を示しますが、その使用に関しては、出力の正確さ、AI倫理上問題のある内容の出力、悪用のリスクなどいくつかの問題が発表されています。これらに関しては、また、別の記事で話したいと思います。
【生成AIに関する記事を読みたい方はこちらから『ChatGPTビジネスレポート』に無料登録してください】
執筆担当者:ヤン ジャクリン (GRI データ分析官・講師)












