
大規模自然言語モデル(Large Language Models、LLM)とは、膨大な数のパラメータから構成された汎用的な言語モデルです。「汎用的」というのは、大量のテキストデータを学習することにより、様々な自然言語処理のタスクを人間にある程度近い精度で行うことができます。

事前学習とファインチューニング
大規模な画像データセットを用いて学習した画像認識モデルを転移学習に使用することと同じ仕組みが自然言語処理にも応用されています。有名なBERTやGPT 系のモデルは、事前学習と転移学習に使いやすい言語モデルの代表です。
大規模自然言語モデルが実用化されるまでに、事前学習とファインチューニングの2つのプロセスがあります。
事前学習(Pre-Training)とは、インターネット上の大量なテキストデータ(コーパス)を学習し、自然言語処理に関する「一般的な知識や情報」を獲得することです。学習用コーパスの規模は数十億件のトークン(単語やフレーズ)にも及ぶことがあります。
事前学習には通常、教師なし学習が用いられます。すなわち、ラベル付けされたデータセットは必要としません、大量のテキストデータからモデルは自動的に自然言語のパターンを抽出し、それに基づいて新たなテキストを生成する能力を獲得します。事前学習を終えた学習済みモデルは既に、多くの文章に共通な汎用的な特徴量をあらかじめ隠れ層で「習得」してあるため、新しい言語タスクに対する転移学習に利用することができます。
従来は、翻訳や質問応答などの特定のタスクに特化した、小さ目のデータセットを利用してモデルを学習していました。ところが、2018 年以降、上記のような大規模自然言語モデルを転移学習に用いる手法が有力になっています。
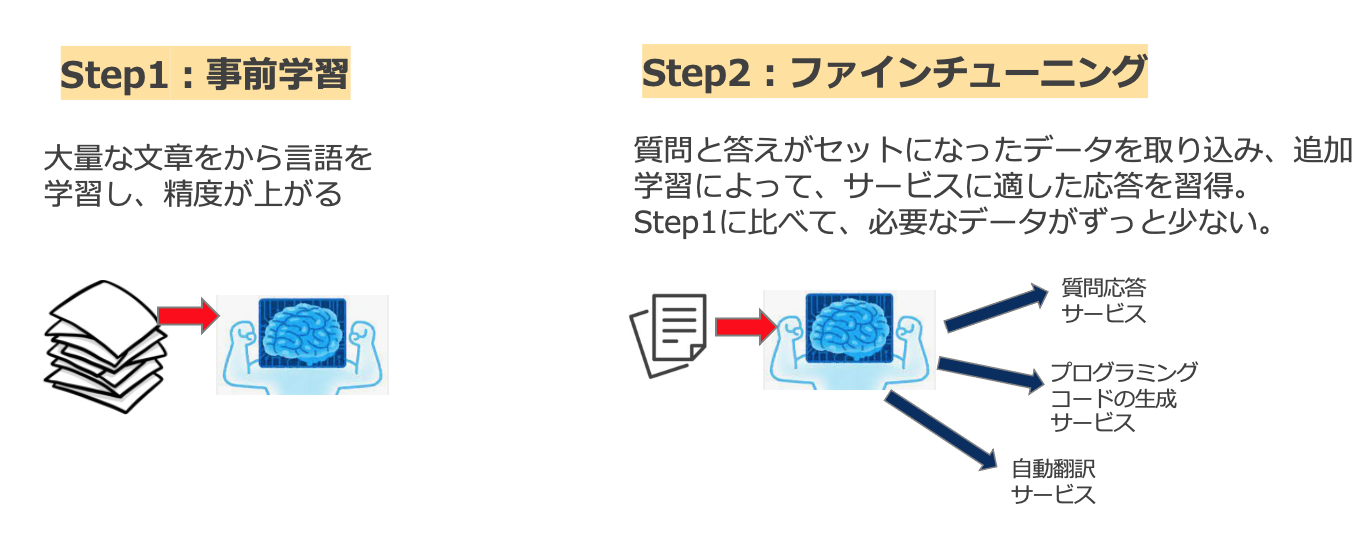
事前学習モデルを活用するためには、一般的にファインチューニングを行う必要があります。下図に、事前学習とファインチューニングの関係性が示されています。
ファインチューニングでは、特定のタスクに特化したデータセット(例:質問と答えのセット)をある程度用意し、それをもって、事前学習されたモデルの一部のパラメータのみ、追加学習と更新を行います。これにより、目的とする機能やサービスに適した応答が得られるようになります。
事前学習に比べて、ファインチューニングで必要なデータが数百〜数千間と、ずっと少ないです。そうすると、リソースが比較的確保しにくい一般企業でもLLMの活用が可能になり、手元にある学習データが小規模でも高精度な認識性能を達成することができます。
スケール則
スケール則(Scaling Laws)とは、モデルのパラメータ数とそれに伴う訓練データ、計算量などが増加するにつれて、モデルの性能もほぼ同じ割合で向上するという経験則です。言い換えると、より大きなモデルを、より多くのデータで訓練すると、様々なタスクにおけるモデルの性能が向上するというものです。自然言語処理の分野に限らず、例えば、画像に使われる最先端のディープラーニングモデルの多くは、このスケール則という原動力に従ってモデルを訓練してきたことで達成されています。
確かに、パラメータ数の多い巨大な「汎用的自然言語モデル」ほど、幅広いタスクにおいて驚異的な性能を発揮します。しかしデメリットはそのコストです。
近年開発された有名な言語モデルのパラメータ数が驚くほど膨らんでいきます。例えば、2018 年に提案された「BERT」のパラメータ数は3 億程度であったのに対して、2020 年の「GPT-3」では1750 億程度まで巨大化し、2023年3月に公開されたGPT-4は1兆を超えています。
このような高度な深層ニューラルネットワークを利用しているため、それに応じて、学習データの量と計算資源をますます増やす必要があります。実際、近年のLLMの学習には数百~数千個のGPU やTPU が使われています。パラメータ1000 個に対しておよそ1ドル使用すると見積もられています。例えば、GPT-3(パラメータ1750 億個)の学習費用は日本円にすると10 億円を超えます!(参考:The Cost of Training NLP Models: A Concise Overview)
だからこそ言語モデルの研究開発はどうしても計算のリソースや予算を使えるIT 大手企業を中心に競い合われることになります。
しかし、最終的には次元の呪いや計算コスト、エネルギーコストなどの問題に直面してしまうため、スケールアップできる実用的な限界が存在します。近年、同程度な性能でモデルのサイズダウンに関する研究も盛んに行われています。
【生成AIに関する記事を読みたい方はこちらから『ChatGPTビジネスレポート』に無料登録してください】
執筆担当:ヤン ジャクリン (GRIデータ分析官・講師)












