
本シリーズGoogleColab 上でファイルを操作コツのPart1では、ColabからGoogleドライブへのアクセス法、ファイルの新規作成、アップロード、ダウンロードなどの基本的なやりとりをお伝えしました。
前回:https://gri.jp/media/entry/2292
このPart2では、その続きとして、ドライブ上に置かれている表形式データや画像データをGoogleColabのコードに読み込む演習をしましょう。
GoogleColabから見た、ドライブ上のファイルディレクトリー
基本的に Jupyter Notebook では、Linuxコマンドを冒頭に「!」をつけることで使用することができます。
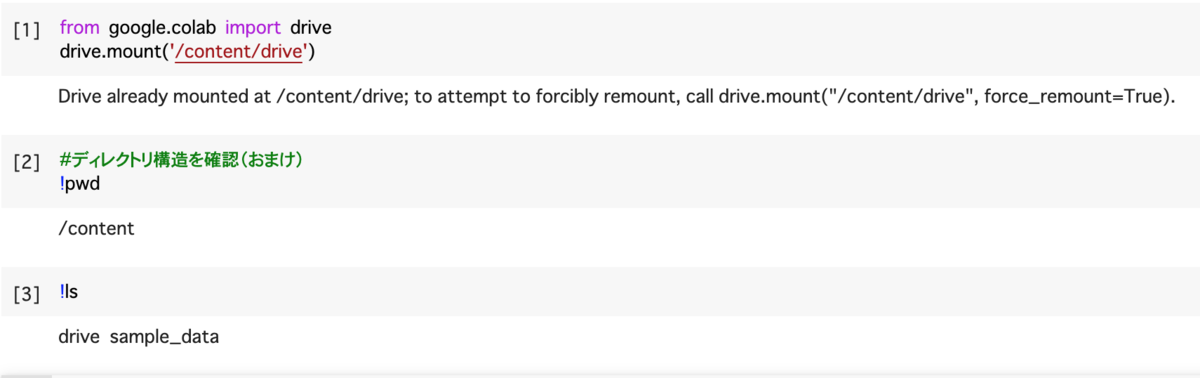
ディレクトリ構造を確認するために、「!pwd」で「今自分がどこにいるか」を確認できます。今はホーム直下の /content にいます。
次に、「!ls」でこの「content」というフォルダにはどういうもの(ファイルやサブフォルダ)が入っているかを見ることができます。その結果として、「drive」と「sample_data」というサブフォルダがあることが見えますね。
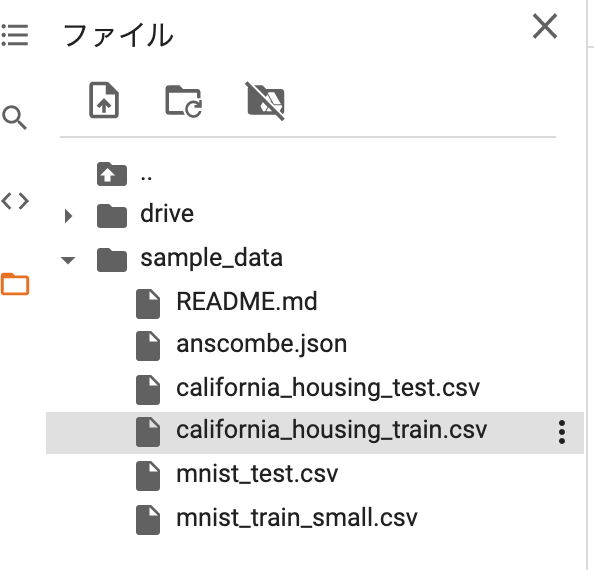
実は最近できた機能で、画面左にあるパネルのフォルダーマークから、ファイル名やディレクトリー構造が見えるようになりました。これを利用するメリットは:
- ドライブ上のファイル構造を、コードを書きながら可視化できる
- ドライブ上のパスを楽にコピーできて、楽になる
です。
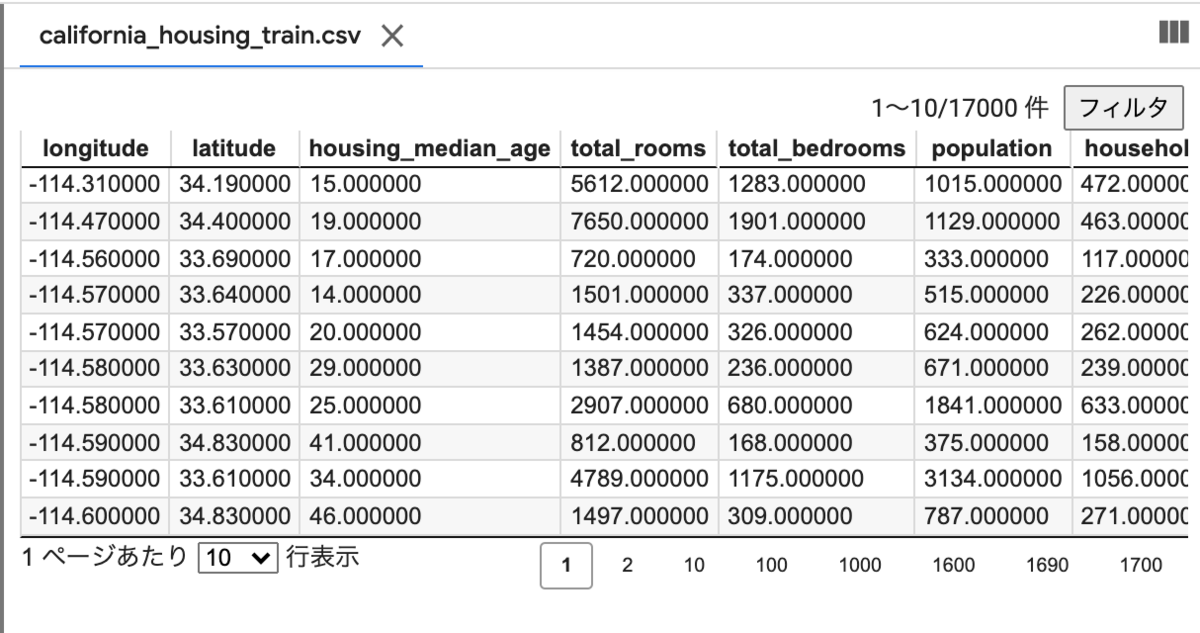
データの中身も見やすくなります。例えば、ここでsample_dataフォルダをワンクリックで開いて、california_housing_train.csv をダブルクリックすると、画面の右側にデータそのものを綺麗に閲覧することができますね。このデータにはどういう列があって、それぞれの列にはどんな数値が入っているのかなど、これからこのコードで行おうとしている分析のためになる情報が見つかるかもしれません。
表形式データを読み込む
先ほどの「california_housing_train.csv」は表形式のデータです。それをpandasのDataFrameに格納し見てみましょう。
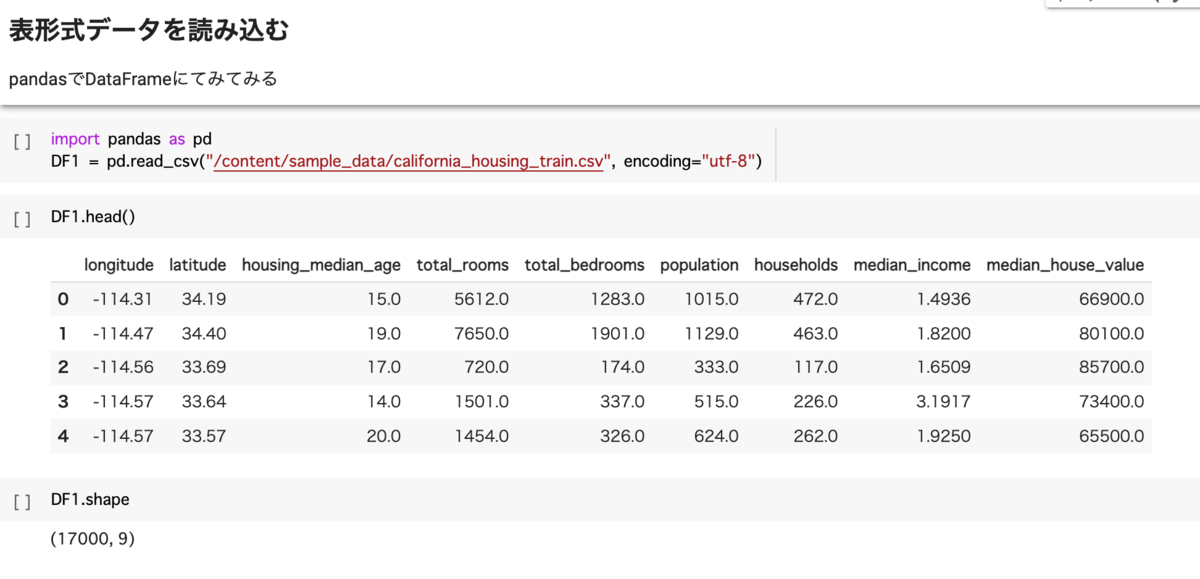
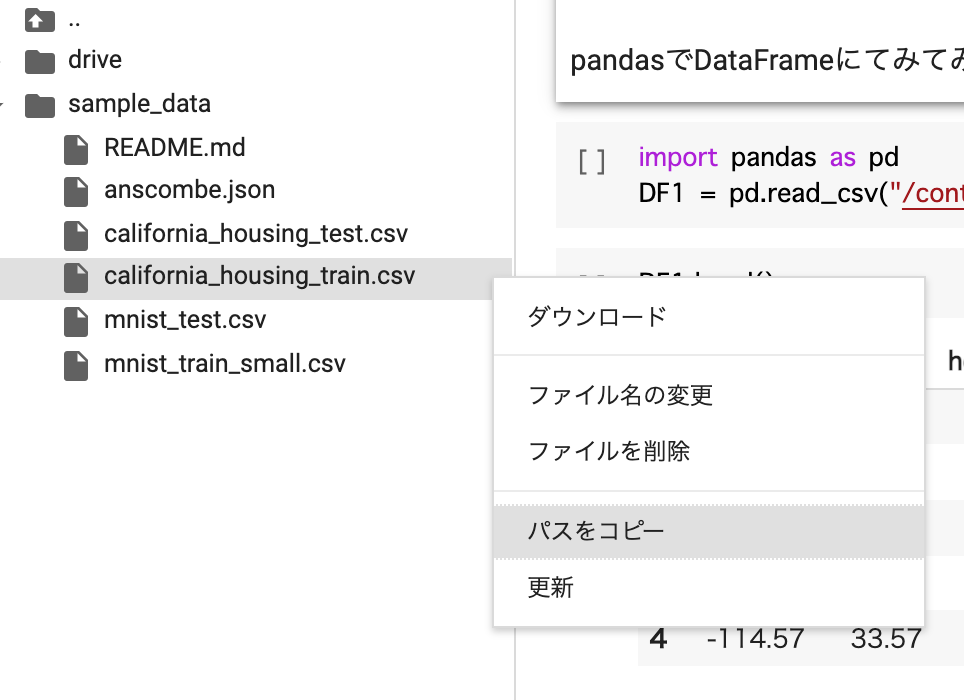
この時、pd_read() の中に記述するファイルパスは下図のように、左パネルで見えているデータ名を右クリックして、プールダウンから「パスをコピー」をし、次にコードの中の該当場所にペーストし、これで楽にデータパスを反映できますね。
画像データを読み込む
今度は、’/content/drive/’ の中の My Drive にある子猫三匹が写っているサンプル画像データを読み込んでみます。画像データの処理によく使うcv2モジュールをimportします。

一般的にAnacondaなどの環境でcv2を使用する場合は、画像を表示する際によくcv.imshow() が使われます。
しかし、cv.imshow() はcolabで使えません。代わりにColab側がサポートパッチを提供しています。
それがcv2_imshow(image)です。
ここで、image は cv2.imread() で画像ファイルパスを介してコード内に読み込んだデータです。
最後に、image はNumpyの配列として保持されているので、コードで単に image と打てば、配列の数値を見ることができます。

後続の記事では、Part1とPart2で学んだテクニックを生かして、GooglePhotoの画像へのアクセスや動画ファイルの自動的なダウンロードなど、発展的な「演習」をしていけたらと思います。
ここまで読んでいただきありがとうございます。また次回お会いしましょう。
担当者:ヤン ジャクリン (分析官・講師)
















