
こちらの記事の続きです。


TL; DR
- 自動機械学習ツールForecastFlowを使って、SUUMOからいい感じのお得物件を探すプロセスを考えてみたよ
- 機械学習モデルを作成したよ
- 予測家賃と実際の家賃を比較することでコスパが良い物件を探したよ
- アップデート案とか応用例を考えてみたよ
物件探索のプロセス概要
全記事でも書いてたことの再掲ですが、以下のような手順で進めてました。
本記事ではいよいよメイントピックである(4)(5)の機械学習による予測とその比較によるコスパ良物件の探索について説明します。
(1)探索条件の整理
(2)SUUMO物件データのクローリング・スクレイピング
(3)データ前処理・可視化
(4)機械学習(ForecastFlow)で予測モデル作成
(5)予測モデルによるコスパ良物件の発見
ところで、(4)(5)のプロセスはデータの生成過程の説明に重きを置く統計学であれば、重回帰モデルなどに代表されるように、至極当然のアプローチなのですが、予測に重きを置く機械学習ではあまり馴染みがないアプローチかもしれません。
とはいえ、重回帰であろうが機械学習であろうが、本質的には無秩序なデータの羅列から何かしらの法則性を見出すこと。故に、適切に汎化性能を持たせてあげさえすれば、両者は本質的に同様のアプローチとなるはずです。
両者とも適切なデータ処理をすれば、本質的に同質の表現が可能であるとするのであれば、あとはその「適切なデータ処理」にかかる手間を見比べて手法を選定することになります。
ここでは以下の理由から機械学習、特に決定木系アルゴリズムを採用している児童機械学習ツールForecastFlowを利用して分析を進めていきます。
- 適切なスケーリングや、カテゴリカル変数をダミー変数化したりする手間が必要ない
- 特徴量と予測対象の間の非線形な法則性も見出せる
- データ整形さえしておけば、訓練から精度確認、推論までノーコードで高速に実行可能
ごちゃごちゃ言ってますが要はForecastFlow使おうぜってことです。
今なら90日間の無料トライアルもできます。↓こちらから。
「(4)機械学習(ForecastFlow)で予測モデル作成」の概要
以下のような順番で進めます。
- 作成済みデータセットの復習
- ForecastFlowへのデータ投入・データ確認
- ForecastFlowでの機械学習モデル作成
作成済みデータセットの復習
では早速ForecastFlowに作成済みのデータセットを連携しましょう。前回の記事で前処理をしたんですがその時の結果を再掲しておきます(詳細は前回記事をご参照ください)。
準備したデータセットはこのようなイメージ、
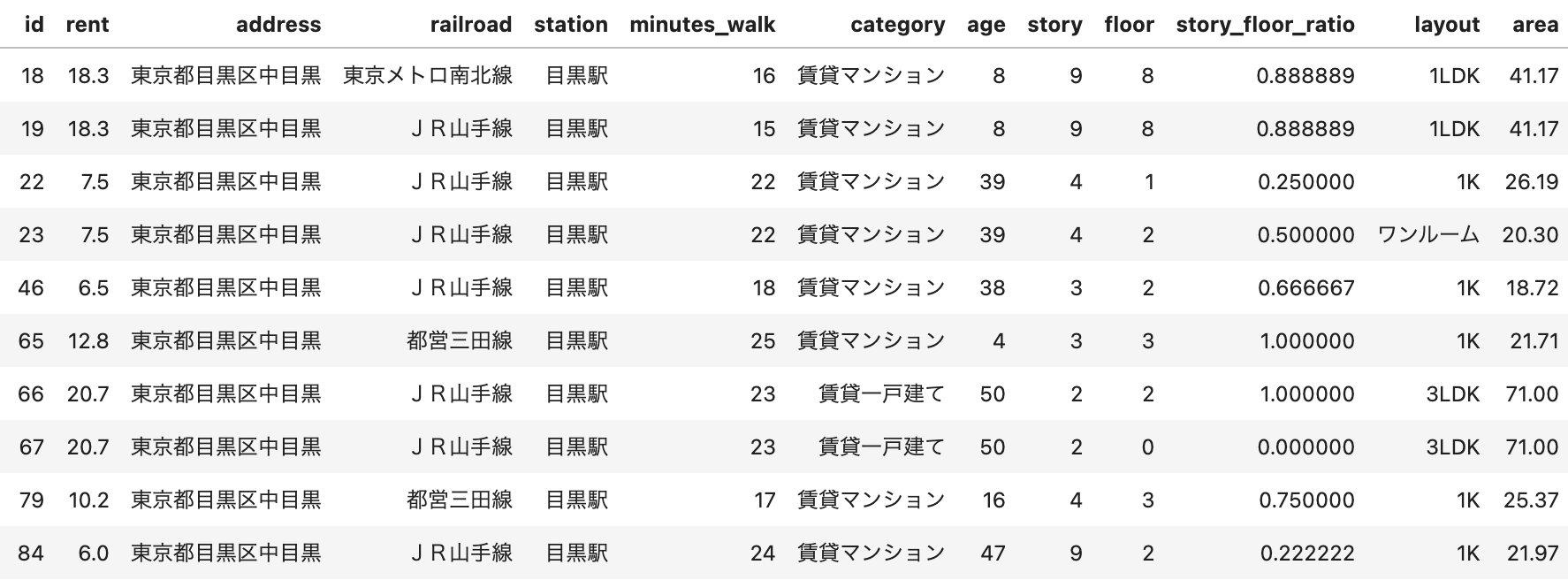
それぞれのカラムの説明は以下の通りです。
| id | 【ID】予測粒度である物件×部屋ごとに一意になるように付与したID |
|---|---|
| 家賃(rent) | 【予測対象】家賃。今回は40万円以下が対象 |
| 住所(address) | 【特徴量】町までの住所(丁目や番地は分からない) |
| 最寄駅の路線(railroad) | 【特徴量】最寄駅の路線 |
| 最寄り駅(station) | 【特徴量】最寄駅名 |
| 最寄駅までの徒歩分数 (minutes_walk) |
【特徴量】最寄り駅まで徒歩何分か(30分以上は30分にまとめている) |
| カテゴリ(category) | 【特徴量】マンションかアパートかといった物件のカテゴリ |
| 築年数(age) | 【特徴量】築年数(50年以上は50年にまとめている) |
| 物件の階建(story) | 【特徴量】物件が何階建てか(15階以上は15階にまとめている) |
| 部屋の階数(floor) | 【特徴量】部屋は何階にあるか(15階以上は15階にまとめている) |
| 物件における部屋の位置 (story_floor_ratio) |
【特徴量】floor/story(0以下は0に1以上は1にしている) |
| 間取り(layout) | 【特徴量】部屋の間取り(4K以上は4Kにまとめている) |
| 専有面積(area) | 【特徴量】部屋面積(参考)(100m2以上は100m2にまとめている) |
【特徴量】とある列の情報を基にして、家賃を予測するような機械学習モデルを作成します。この辺りの機械学習モデル作成に必要なデータセットの詳細は紙面の都合上割愛させていただきますが、気になる方は以下の動画をご覧ください。(11:44 「電話会社のデータを用いた解約予測のデモ」を見ていただくと雰囲気が掴めるかと思います。)
ForecastFlowへのデータ投入・データ確認
以下の動画を参考にして、データをForecastFlowにアップロードします。
(実際に動かしてみている方、動画内の画面は2020年10月時点のものですので、現在の画面とは異なることに注意してください。もしご不明点があればお気軽にこちらからお問い合わせいただけますと幸いです。)
ForecastFlowにデータをアップロードしたら、まずはいくつかカラムをピックアップして、その分布を確認してみましょう。ForecastFlowはヒストグラムの書き方にこだわっていて、全てのカラムに対し、いい感じのビン数設定や外れ値の除外処理を自動で行なってくれます。実はこれだけでも結構便利です。
家賃
9万円付近にピークを持つようなロングテールな分布です。前記事で書いた通り中央値は11.6万円なので、中央値ですらピークから少しズレてます。
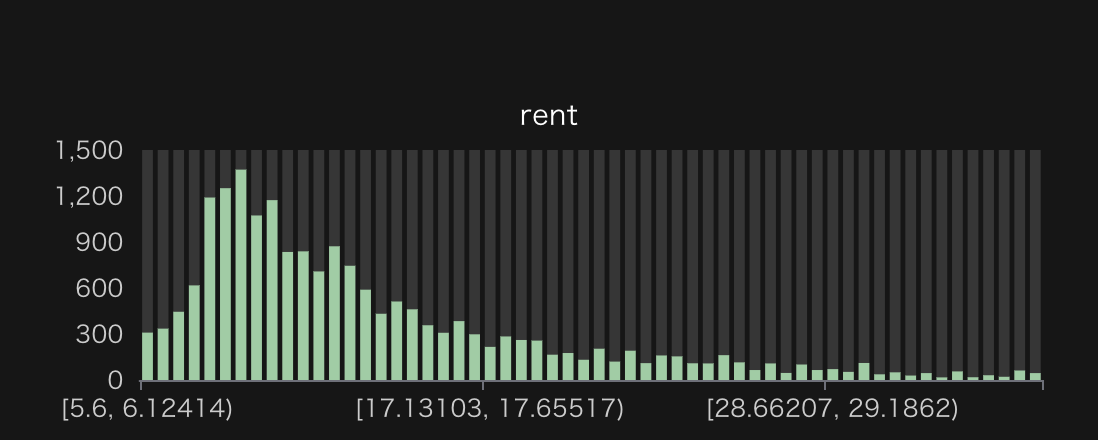 家賃(万円)のヒストグラム。視認性を重視して、371件の外れ値を除外。除外前の最小値は3.7万円、最大値は40万円
家賃(万円)のヒストグラム。視認性を重視して、371件の外れ値を除外。除外前の最小値は3.7万円、最大値は40万円
築年数
会社から5駅以内にある築年数の分布と参考に23区内の物件の分布を載せました。どちらも一番左のビン(新築+築2年)が最も多いことがわかります。これは新築の物件を多く紹介しているSUUMOの特徴と言えるでしょう。
50年のピークは単純にそれ以上の築年数を50年にまとめていることに起因しています。
また、築20年付近に特徴的なピークがありますが、参考に書いた23区内の物件では若干ズレたところにピークがある、かつ波打ったような形をしているので、この辺りはエリアごとの都市開発の周期を反映しているのかもしれません。
一点、この分布は「部屋ごとの」ヒストグラムであって、「建物ごとの」ヒストグラムではないことに注意してください。例えば、築年数10年の1件の建物に対して、SUUMOで20部屋掲載されていたとすると、10年のビンに10件カウントされます。
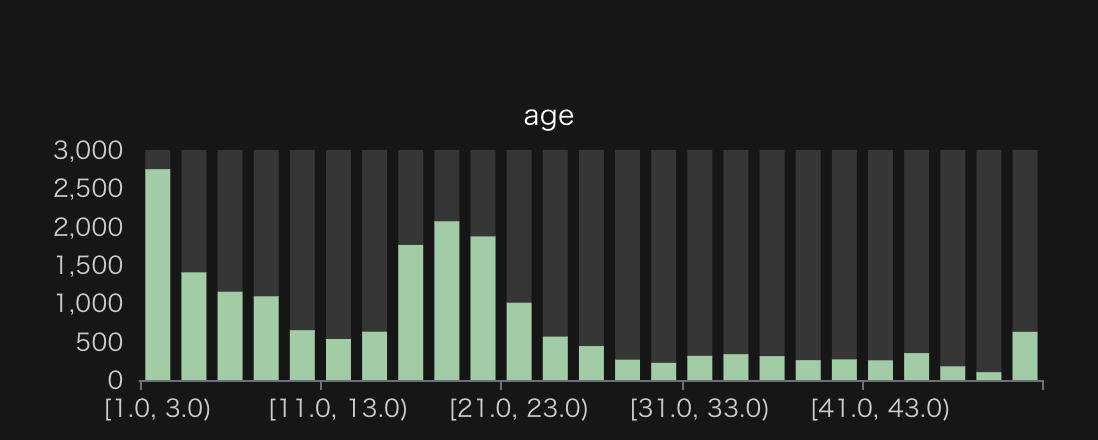 会社から5駅以内にある物件(部屋)の築年数の分布。1から51まで2年刻みでプロット
会社から5駅以内にある物件(部屋)の築年数の分布。1から51まで2年刻みでプロット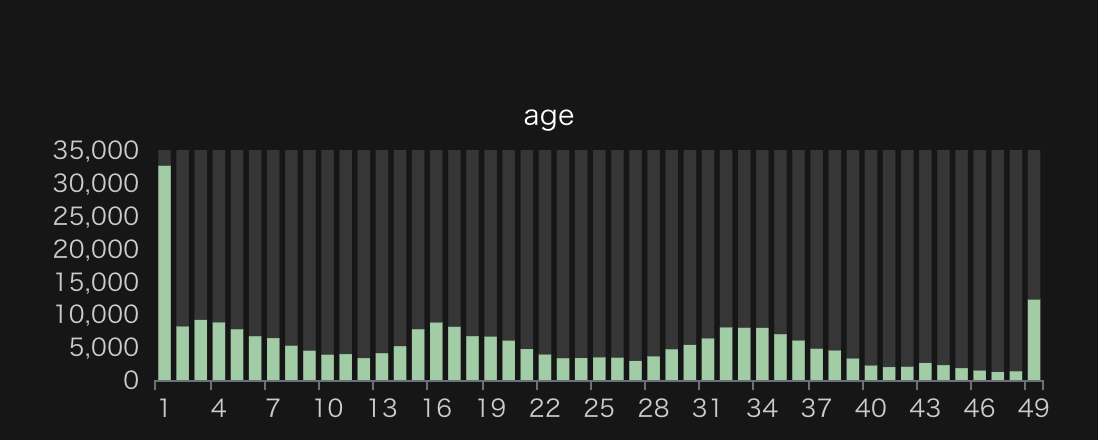 23区内にある物件(部屋)の築年数の分布。1年から49年まで1年刻みでプロット。49年のビンのみ50年の物件も入っている。
23区内にある物件(部屋)の築年数の分布。1年から49年まで1年刻みでプロット。49年のビンのみ50年の物件も入っている。
レイアウト
横軸のラベルが潰れてしまってますが、WebUIの画面であればマウスオーバーして確認可能です。ここでは図のキャプションに記述しておきました。
1Kが圧倒的に多く、続いて1LDK、ワンルーム、2LDK、1DKと続くようです。これ以外は割合としてマイナーであることもわかります。
ちなみに1Kとワンルームの違いはこちらの記事*1が詳しいです。
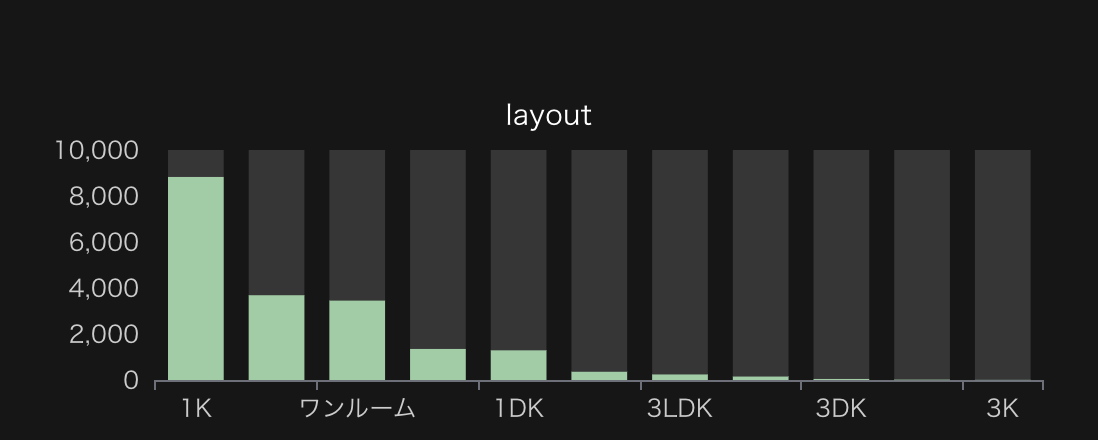 レイアウトのヒストグラム。左から1K、1LDK、ワンルーム、2LDK、1DK、2DK、3LDK、2K、3DK、4K以上、3K。
レイアウトのヒストグラム。左から1K、1LDK、ワンルーム、2LDK、1DK、2DK、3LDK、2K、3DK、4K以上、3K。
専有面積
20m2から物件が一気に多くなり、25m2あたりに特徴的なピークがあります。
こちらの記事*1にもある通り、25m2というのは国土交通省の水準で「一人暮らしに最低限必要な居住面積(最低居住面積水準)」と定められており、典型的には以下の間取りが該当するようです。
- 8畳の1K
- 11畳のワンルーム
、、、いや、贅沢じゃないですか??笑
これを「最低限必要」とするのはなかなか要求水準厳しい気もするんですが違います??
僕の基準がお金のない大学生時代からアップデートされてないだけ、、、??
確かにこちらの記事*2にもある「お金を家賃に使わず飲食に使う男性」像に自分はピッタリ当てはまる気もする。
とまあ、余談はこのくらいにしておいて、25m2のピークはレイアウトで1Kが多いこととも対応してそうです。
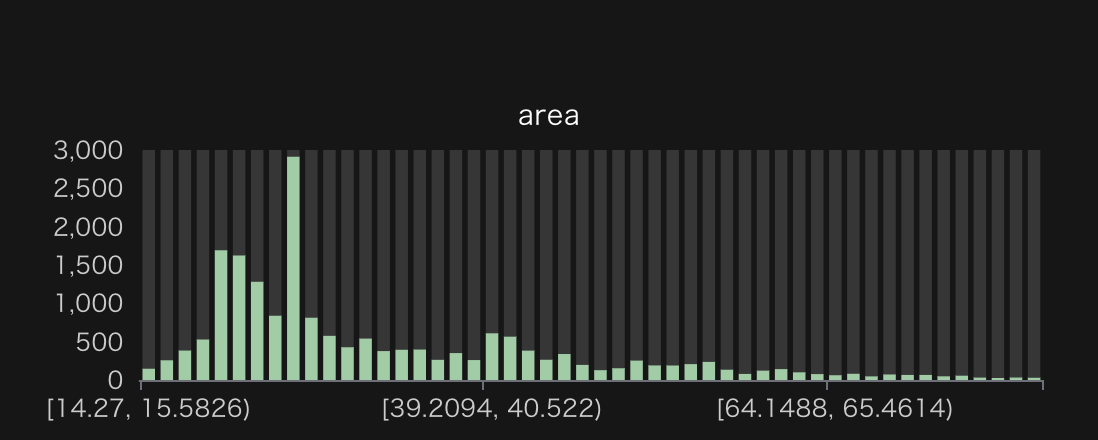 専有面積(m2)のヒストグラム。視認性を重視して、388件の外れ値を除外している。除外前の最小値は5.79m2、最大値は100m2。
専有面積(m2)のヒストグラム。視認性を重視して、388件の外れ値を除外している。除外前の最小値は5.79m2、最大値は100m2。
階数
建物自体の階数(story)と部屋の階数(floor)を比較すると意外と面白いです。建物自体は比較的一様に近い感じで、どの階数も同じ程度存在している一方で、部屋の階数は2階をピークとして単調に減少してます(15階には15階以上の部屋も含まれることに注意)。
つまり、そこそこ高層な建物も含まれるが、部屋は低層階にあるものが大半、と言うことがわかります。
高層階の住人はなかなか引っ越さないので流動性が悪いのか、そもそも部屋が広くて部屋数が少ないのか、はたまた単に低層階を代表させて掲載しているだけなのかは不明ですが、これもまたSUUMO掲載物件の特徴でしょう。
また、建物全体に比する部屋の相対高さ(story_floor_ratio)を見ると1のピーク、つまり最上階が多いことがわかります。この辺りは、部屋の階数で色分けして見るなどもう少し深掘りしてみると面白いかもしれません。
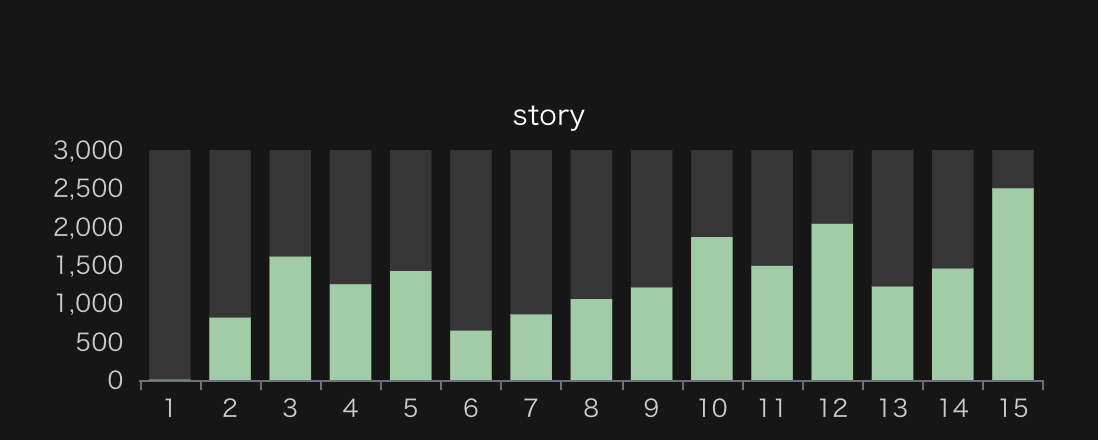 建物の階数のヒストグラム。15のビンは15階以上の建物を含む。
建物の階数のヒストグラム。15のビンは15階以上の建物を含む。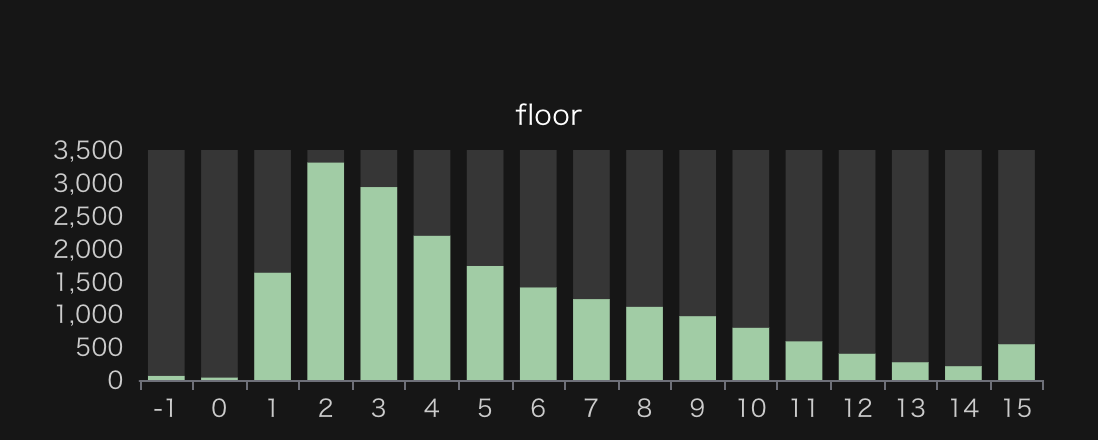 部屋の階数のヒストグラム。15のビンは15階以上の建物を含む。-1は地下の部屋を、0はNULLをそれぞれ表す。
部屋の階数のヒストグラム。15のビンは15階以上の建物を含む。-1は地下の部屋を、0はNULLをそれぞれ表す。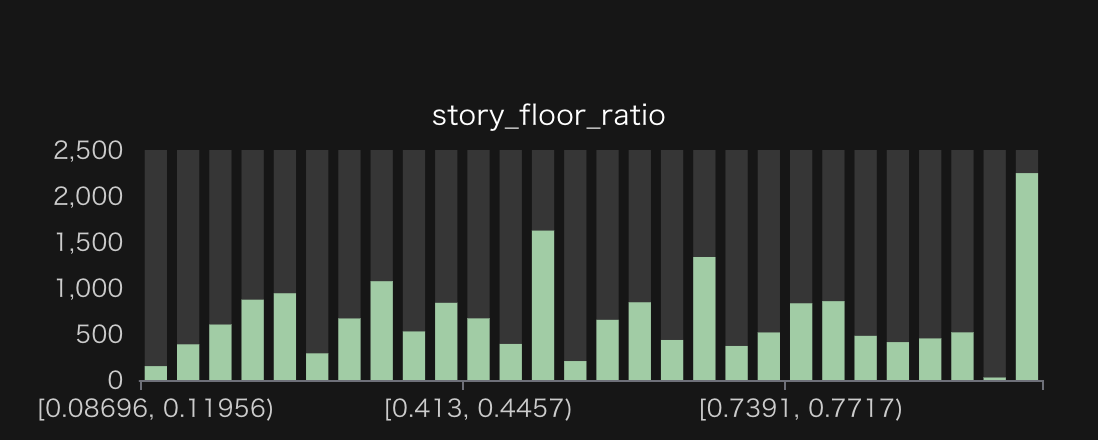 建物全体に比する部屋の相対高さのヒストグラム。0以下は0に1以上は1とした。視認性を重視して194件の外れ値(=0)を除外している。
建物全体に比する部屋の相対高さのヒストグラム。0以下は0に1以上は1とした。視認性を重視して194件の外れ値(=0)を除外している。
最寄駅からの徒歩時間
これは面白いです。
まず5分以内の超駅近物件はほとんど存在しません。7分以上で見ていくと一気に選択肢が広がるようです。同時に20分を超える物件もほとんど存在しないことも分かります。都心の交通網がいかに優れてるか分かりますね。
また、10分、15分にピークがあります。これは本当にそこに物件が集中しているのかもしれませんが、微妙な位置の物件がキリがいいこれらの数字にまとめられている可能性も考えられます。11分などは12分に比べても凹んでいるので、特に10分の方はその可能性が高い気もします。逆に16-18分の物件数がほぼ同じことから15分の方はそこまで人為的ではないかもしれません。20分と21-23分の間でも同じことが言えそうです。
10分と11分なんて実際は大して変わらないんですが、物件を探す時って「徒歩10分以内」みたいにフィルタをかけるので、掲載の観点から言うと両者の間には超え難い壁が存在するんですよね。少しくらいなら10分に寄せたい気持ちはとても理解できます。
実はこのような融通の効かないフィルタ条件に替えて、「予測家賃」という柔軟な指標で物件を探そうというのがこの記事のモチベーションだったりもします。
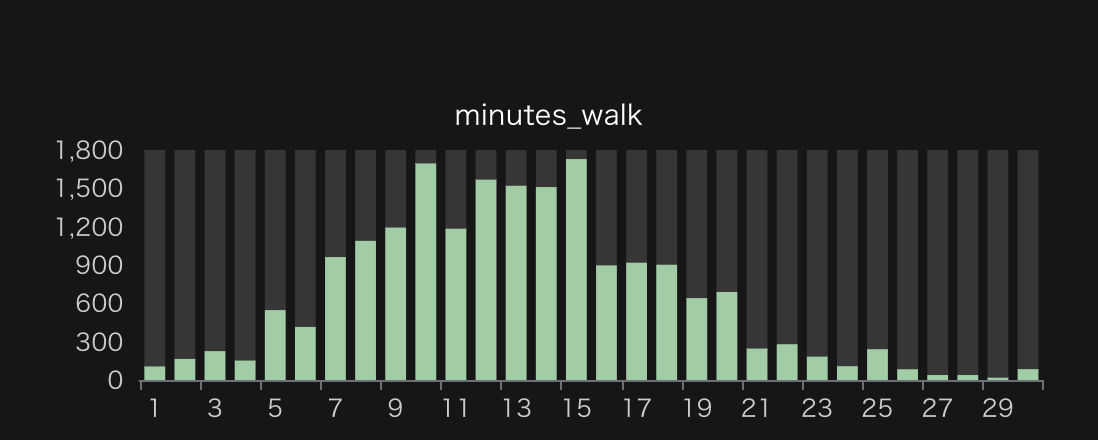 最寄駅からの徒歩時間(分)。1分から30分まで1分刻み。30分以上は30分とした。
最寄駅からの徒歩時間(分)。1分から30分まで1分刻み。30分以上は30分とした。*1 一人暮らしにちょうどいい広さはどのくらい? 専有面積25平米は狭い?:https://www.homes.co.jp/cont/rent/rent_00307/
*2 独身男女の高くて厚い壁…「港区女子と足立区男子」は永遠に出会えない:https://president.jp/articles/-/42602
ForecastFlowでの機械学習モデル作成
以下の動画を参考にして、機械学習モデルを作成していきます。
(繰り返しになりますが、実際に動かしてみている方、動画内の画面は2020年10月時点のものですので、現在の画面とは異なることに注意してください。もしご不明点があればお気軽にこちらからお問い合わせいただけますと幸いです。)
本記事では設定の詳細説明は割愛させていただきますが、以下の設定でモデル作成を行いました。
- 回帰モデル
- 検証データは訓練データをそのまま利用(「他のデータセットを検証のデータセットにする」から訓練作成に利用したデータセットを選びます)
- 最適化指標はmean absolute error(MAE)
- その他ハイパーパラメータはデフォルト
精度
細かい説明は省きますが、R2が98.9%と非常にいい精度となっています。これは当たり前で、訓練に使用したデータセットを用いてそのまま検証用データとしているからです。言わば、「テスト問題と解答を事前に教えてもらって、全く同じテストを受けた時の点数」のようなもので、「未知の予測」を主眼とする機械学習の文脈で言うと普通はNGな検証方法になります。
ですが、予測というのは結局「過去のデータから規則性を見出す」ことであって、その規則がある程度汎用的なものであれば、特段問題になるわけではありません。
例えば、「東京都港区芝公園2-3-6の7階にある25m2の物件は20万円」のような、あまりにも個別な規則を学習したところで、そのような規則を当てはめる対象がなければ意味がないわけです。一方で、「1m2増えるごとに家賃は3,000円高くなる」とか「駅に徒歩1分近くなるごとに家賃は5,000円高くなる」のような規則であれば、未知の物件に対しても当てはめることができます。
そして、この個別過ぎる規則(過学習)を防ぐことは機械学習でもハイパーパラメータを調整すれば可能です。詳しい設定は大人の事情でお伝えできないのですが、ForecastFlowは弊社の経験を基にして「よしなに」ハイパーパラメータを調整してくれます。ということで一旦はこのForecastFlowがおすすめするハイパーパラメータを用いましょう。
 作成した予測モデルの精度
作成した予測モデルの精度特徴量重要度
こちらも細かい説明は省きますが、要は特徴量のうちどれが予測モデル作成に寄与度が大きのか?を表すものです。今回の例でいえばこの値が大きい特徴量ほど、家賃を予測するために重要ということになります。
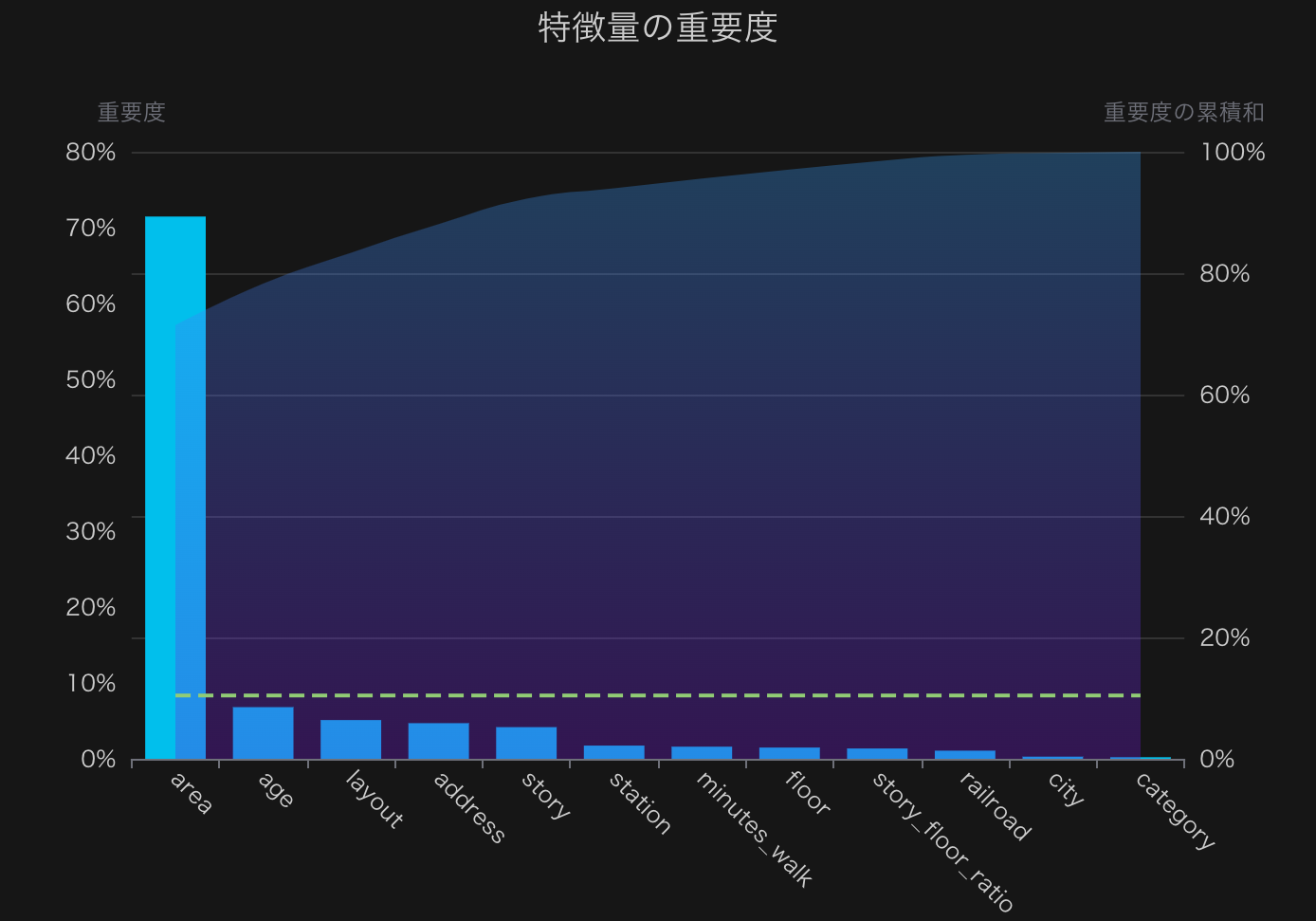 作成した予測モデルにおける特徴量ごとの重要度。全特徴量の和を1としてそれに対する割合で表示。薄い青色のエリアは累積割合を示す。
作成した予測モデルにおける特徴量ごとの重要度。全特徴量の和を1としてそれに対する割合で表示。薄い青色のエリアは累積割合を示す。グラフを見ると「専有面積(area)」が圧倒的に重要で、全特徴量の重要度の和を100%とした時、全体の72%を占めています。
これはある意味当然で、「広ければ広い部屋ほど家賃が高い」ということを表しているに他なりません。(実は特徴量重要度だけでは「広いほど家賃が高くなること」までは分からないんですが、後ほどPDPでそのことを確認します。)
今回は「トイレバス別」とか「独立洗面台あり」とかその辺の皆さんが当然気になる条件を(怠惰のため)特徴量として入れてはいません。が、この結果を見るにそれらの条件は専有面積に込み込みで含まれているのでしょう。同じ1Kでもトイレバス別で独立洗面台があればその分専有面積も広くなるし、家賃も高くなるということです。
実際レイアウトは3位にランクインしているものの、より直接部屋の広さを表す専有面積に比べると重要度は10分の1程度になってます。
専有面積の次には、築年数やレイアウト、地区名、建物の階数、最寄駅名、最寄駅までの徒歩分数などが続いてます。
この結果は例えば、類似の分析をしているこちらの記事*3なんかと整合的ではありそうです。この方は僕より真面目にスクレイピングや特徴量設計をしてるので、専有面積の一強ではなく、そこそこ重要度がバラついてることが分かります。「高さ×広さ」とか「一部屋あたりの面積」とか面白い特徴量ですよね。
先ほどもちらっと言いましたが、特徴量重要度でわかるのはその特徴量が「重要である」ことだけで、「予測にどのように寄与するか」は分かりません。要は「部屋が広いほど家賃は高い」のか「部屋が狭いほど家賃は高い」のかが分からないわけです。
というわけでそれを確認するためにPDPと呼ばれる量を確認します。
*3【超初心者向け】コピペで動かして楽しむPython環境構築&スクレイピング&機械学習&実用化【SUUMOでお得賃貸物件を探そう!】https://qiita.com/haraso_1130/items/8ea9ba66f9d5f0fc2157
PDP(Partial Dependence Plot)
こちらも細かい解説は省略しますが、例えば「部屋が広くなるにつれてどのように予測家賃が変化するか」を表すものです。
ちなみに上述の特徴量重要度やこのPDPなどは従来ブラックボックスであった機械学習を、統計学で用いられるデータ生成プロセスの知見に基づく数理モデルのように解釈できるように考案されたものです。最近はXAI(Explainable AI; 説明可能なAI)などとも称されます。ForecastFlowは機械学習を解釈可能にするこれらのプロットをモデル作成時の数クリックで同時に作成してくれるので、分析官のコーディング時間を削減し施策考案などより本質的なところに時間を使えるようになるのです。(宣伝)
詳しく知りたい方は以下の書籍を参考にしてください。必要な知識が全て詰まってる上に超分かりやすいです。(宣伝ではない)
とりあえずめぼしい上位特徴量について確認していきましょう。
専有面積(area)
ほぼ線形ですね。こんなにはっきりしてるなら、(レイアウトやエリアで)適切に層化を行なった線形回帰モデルでもかなり精度が出そうです。
値を読んでいくと(80m2を超えたあたりで頭打ちになりますが)、「2.6m2広くなるごとに家賃が1万円高くなる」ことが分かります。
「2.6m2増えるごとに1万円」試験に出るので覚えておいてください。
エリアや築年数ごとに当然切片は異なるんですが、専有面積の影響が最も大きいことを勘案すると、ベースとしてこの傾向値は一つの目安になるでしょう。
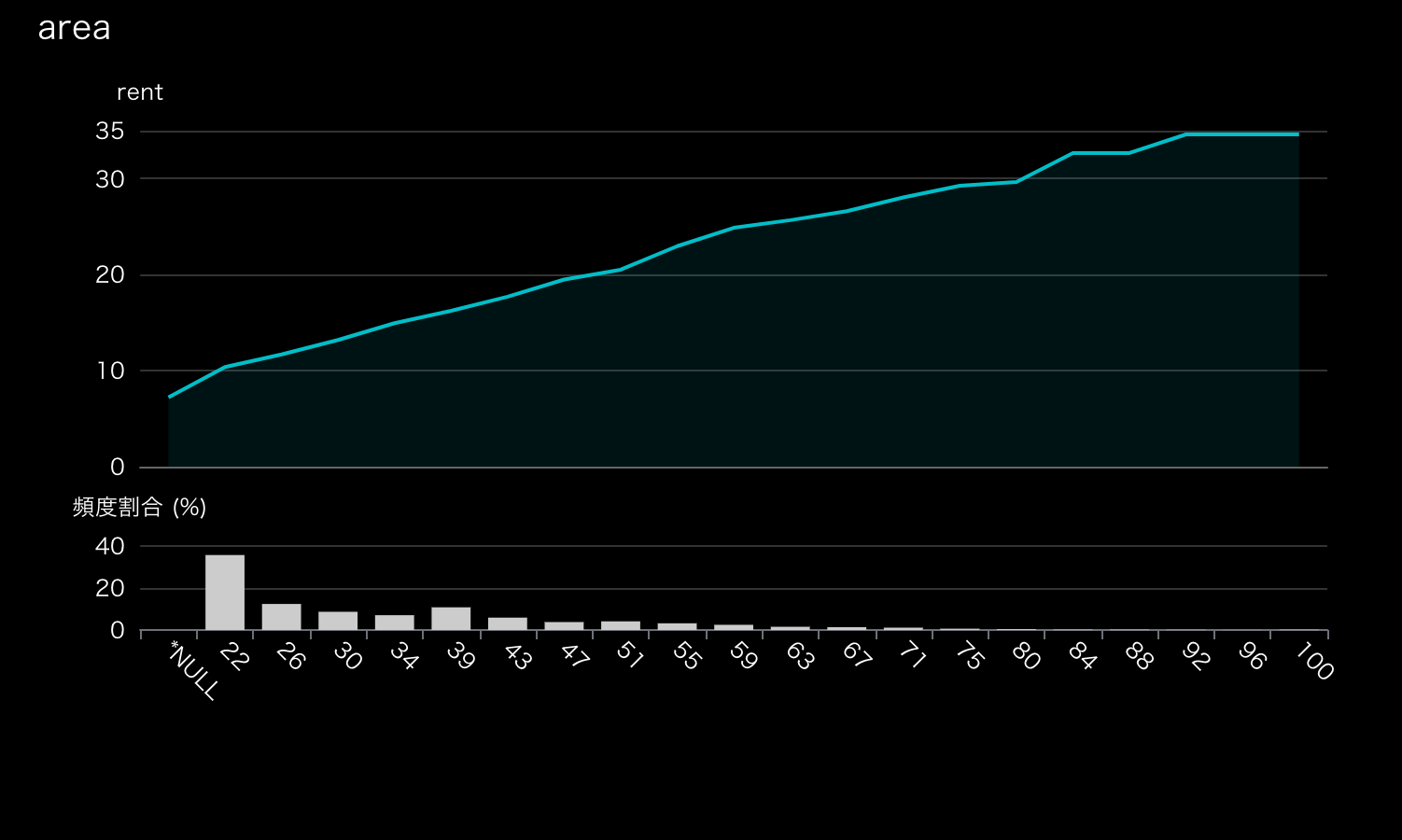 専有面積のPDP。横軸の単位や外れ値の丸め方はヒストグラムのプロットと同様。
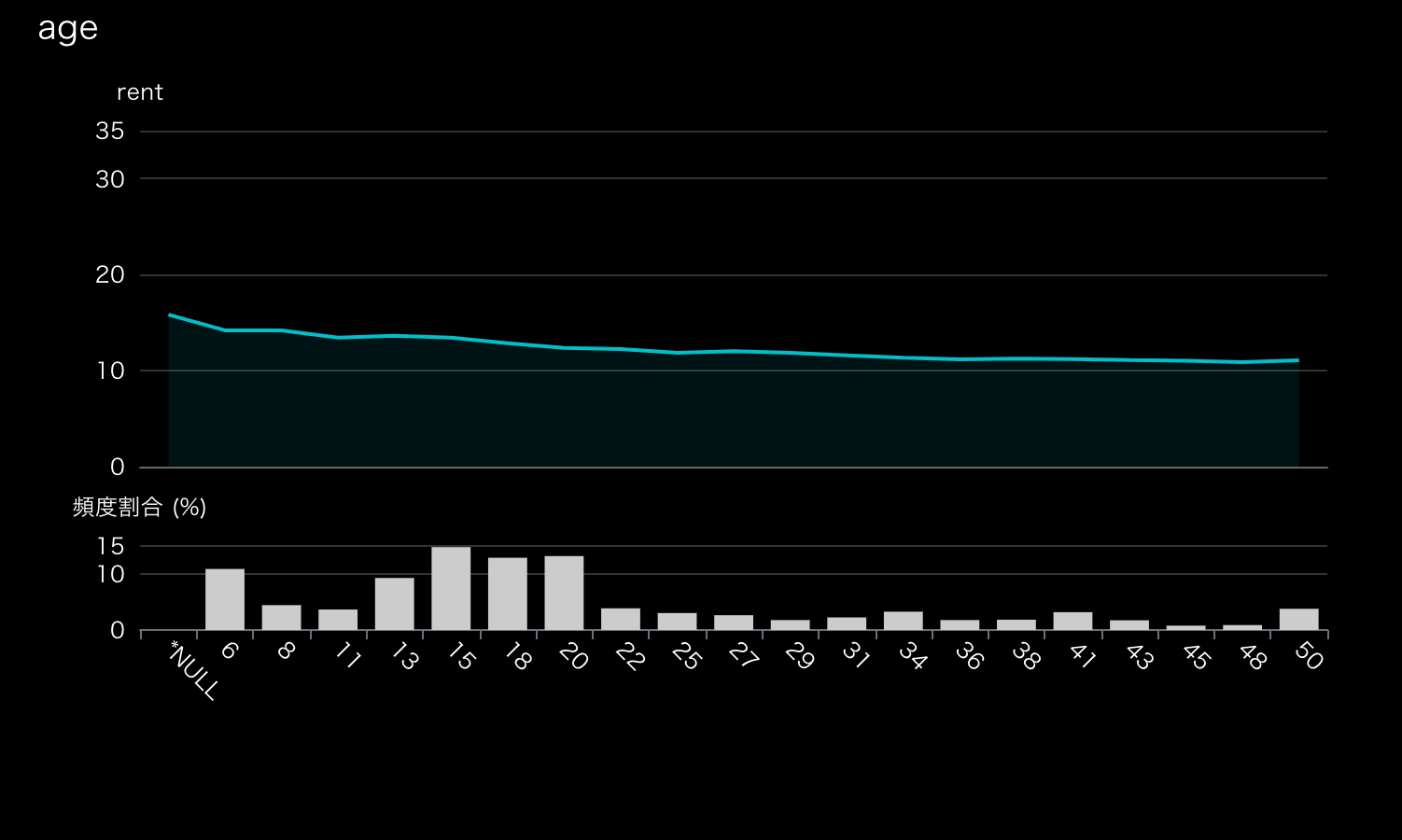
専有面積のPDP。横軸の単位や外れ値の丸め方はヒストグラムのプロットと同様。築年数(age)
新しい物件ほど家賃は高く、古くなるにつれ安くなる傾向で、これも感覚と合致してます。 6年目の(ビンの)物件と20年目の(ビンの)物件を比較すると、約2万円異なっているので結構差異は大きそう。特に築浅にこだわらない人は築年数20年くらいの物件が数も多く狙い目かもしれません。
逆に、どうしても10年以内の物件がいい!という方は、データ処理の段階で古い物件をまとめてあげることで、築1-10年目の家賃推移を確認するのがいいでしょう。
 築年数のPDP。横軸の単位や外れ値の丸め方はヒストグラムのプロットと同様。
築年数のPDP。横軸の単位や外れ値の丸め方はヒストグラムのプロットと同様。レイアウト(layout)
差がほとんどないので感覚と合わないと思うかもしれません。しかしこれは「専有面積がもし同じだとした時のレイアウトごとの家賃差異」(厳密ではないですが)を表しているもので、実際にはレイアウトが異なると専有面積も当然異なるため、そこは注意が必要です。
例えば同じくらいの面積だとすると2LDK、1LDK、2DKの順で家賃が高いことが分かります。個人的な感覚ですが、2DKの物件に比べ1LDKの物件はオシャレなものが多く、家賃が高いイメージです。
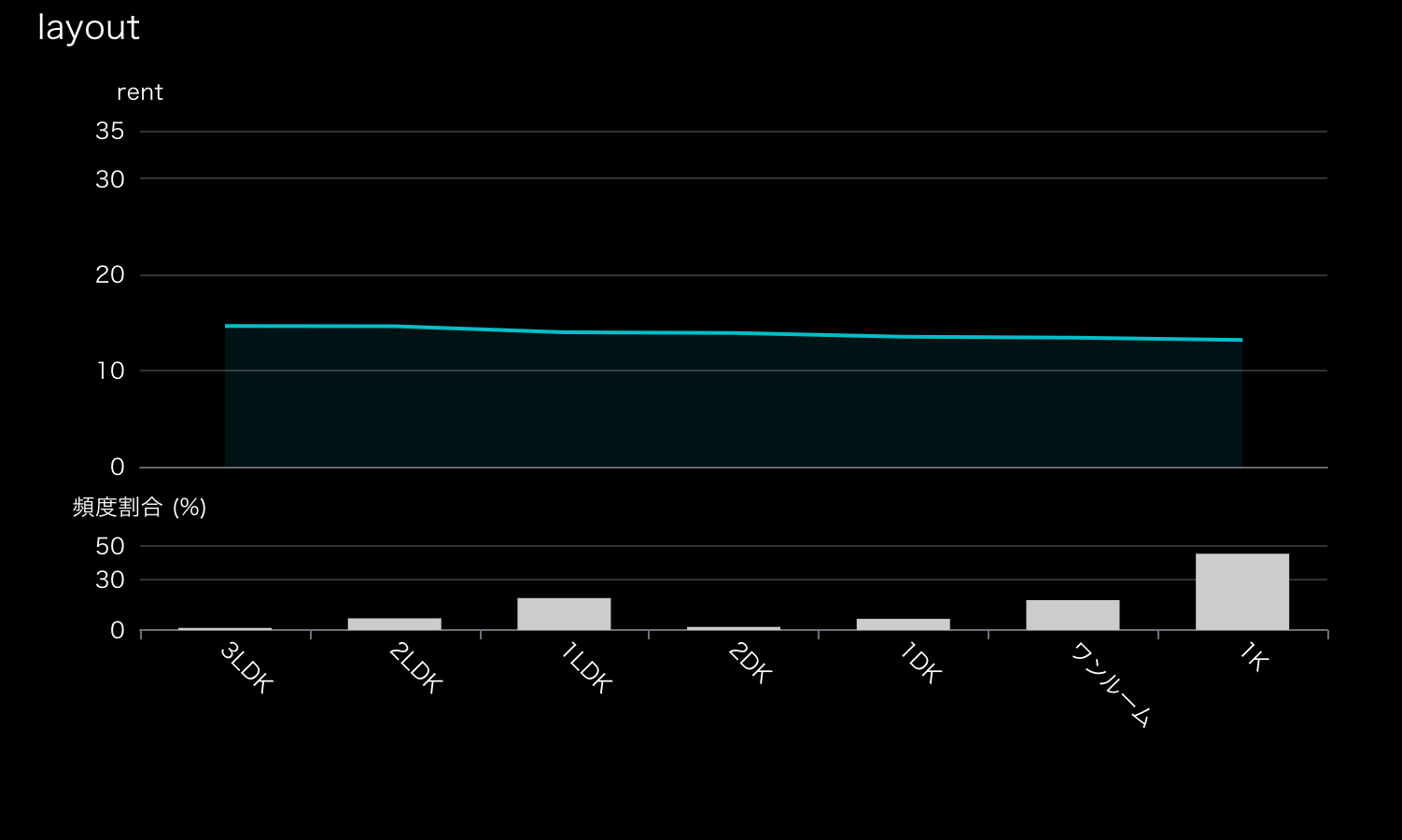 レイアウトのPDP。横軸の単位や外れ値の丸め方はヒストグラムのプロットと同様。頻度が少ない値に関しては表示から除外している。
レイアウトのPDP。横軸の単位や外れ値の丸め方はヒストグラムのプロットと同様。頻度が少ない値に関しては表示から除外している。住所(address)
要はどのエリアの家賃が高いのか?というもので、皆さん一番興味があるとこではないかなと思います。ただし、レイアウトのところでも言った通り「専有面積が同じだとした時の」エリアごとの差異ですのでそこはご注意ください。また、頻度が少ないエリア(頻度0.25%未満)は表示から除外しました。
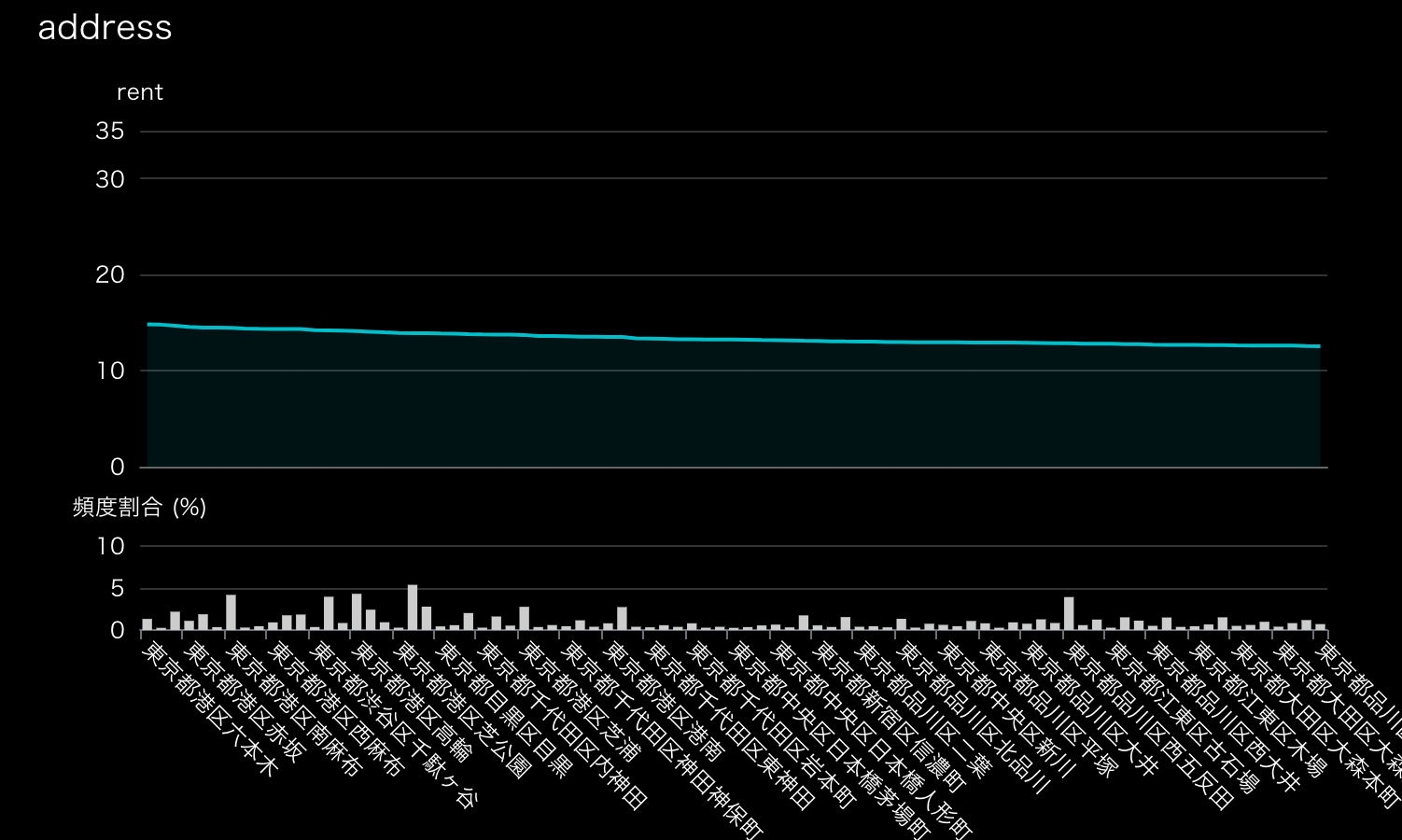
一部表示が潰れちゃってるのでランキング表で確認しましょう。
家賃上位5エリア
| 住所名 | 家賃相場[万円](頻度割合) |
|---|---|
| 1位 港区六本木 | 14.82(1.32%) |
| 2位 港区南青山 | 14..79(0.25%) |
| 3位 港区麻布十番 | 14.69(2.18%) |
| 4位 港区赤坂 | 14.57(1.09%) |
| 5位 渋谷区恵比寿 | 14.49(1.87%) |
家賃下位5エリア
| 住所名 | 家賃相場[万円](頻度割合) |
|---|---|
| 1位 品川区東大井 | 12.55(0.70%) |
| 2位 品川区荏原 | 12.57(1.18%) |
| 3位 大田区大森北 | 12.61(0.82%) |
| 4位 大田区大森東 | 12.61(0.40%) |
| 5位 大田区南馬込 | 12.62(0.98%) |
上位エリアは六本木、南青山、麻布十番、赤坂と非常に納得感がありかつ地図でも確認した通りの結果で、作成モデルもこの地域性を表現できてそうなことが分かります。
逆に下位エリアは品川区と大田区に固まってそうで、現に6位以下を確認してもこの2区が大半を占めています。品川区が下位なのは意外かもしれません。品川駅といえばニュースにもよく出る東京を代表する駅でもあり、田舎者の僕でも上京前から知ってましたし、品川ナンバーと言えば勝ち組ナンバープレートNo.1(僕調べ)です。
しかしここで皆様に驚愕の事実をお教えします(知ってる人は知ってるだろうけど)。
実は品川駅は品川区ではなく港区なのです。
ゆえに品川駅のイメージは港区のそれに他ならず、品川区は戸越銀座や大井町に代表されるような昔ながらの住みやすい住宅街を多く含みます。
そして、北品川駅が品川駅の南にある謎もこれで氷解する(?)でしょう。北品川駅は品川区の北に位置しているから北品川駅なのです。北品川駅は悪くない。悪いのは港区にあるにもかかわらず品川を名乗る品川駅なんです。
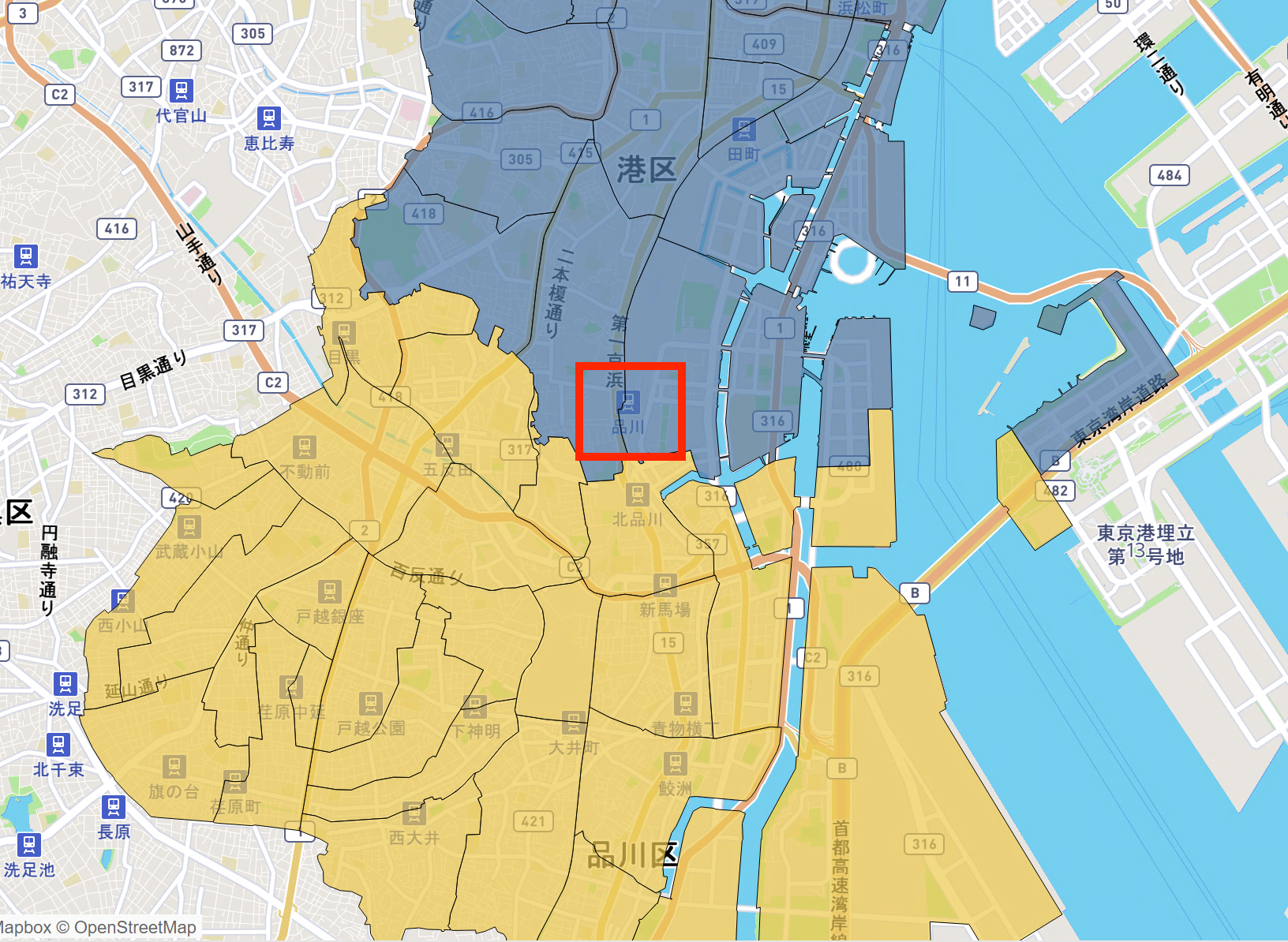 品川区と港区の境界付近のマップ。LLocoを利用(詳細は本シリーズ(2)を参照)。港区を青で、品川区を黄色で色分けし、品川駅を赤枠で囲っている。
品川区と港区の境界付近のマップ。LLocoを利用(詳細は本シリーズ(2)を参照)。港区を青で、品川区を黄色で色分けし、品川駅を赤枠で囲っている。
(5)予測モデルによるコスパ良物件の発見
以下の動画を参考にして、作成済みモデルから予測値を計算します。
(くどいようですが、実際に動かしてみている方、動画内の画面は2020年10月時点のものですので、現在の画面とは異なることに注意してください。もしご不明点があればお気軽にこちらからお問い合わせいただけますと幸いです。)
予測値が計算できたら、訓練に使用した特徴量の一枚表と結合しエニタイム・銭湯存在フラグを付与した上で、実際の家賃と予測値を比較していきましょう。探したいのは予測に比べて実際の家賃が安い「コスパ良物件」ですので、その観点から確認していきます。
まずは実際の家賃と予測家賃の散布図から。予測精度が良いことからほぼ1対1のライン状に物件が分布していることが分かりますが、一部そのラインから外れている物件もあるようです。これら予測と実際が乖離している物件が今着目したい物件になります。
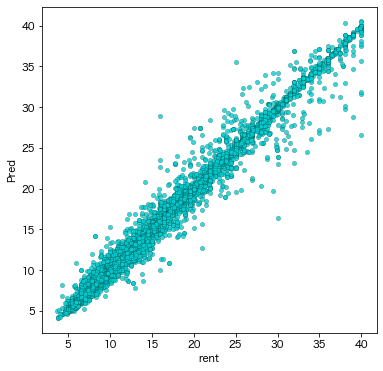 実際の家賃と予測家賃の散布図。横軸(rent)が実際の家賃[万円]を、縦軸(Pred)が予測家賃[万円]をそれぞれ表す。
実際の家賃と予測家賃の散布図。横軸(rent)が実際の家賃[万円]を、縦軸(Pred)が予測家賃[万円]をそれぞれ表す。コスパ良物件TOP10(家賃上限なし)
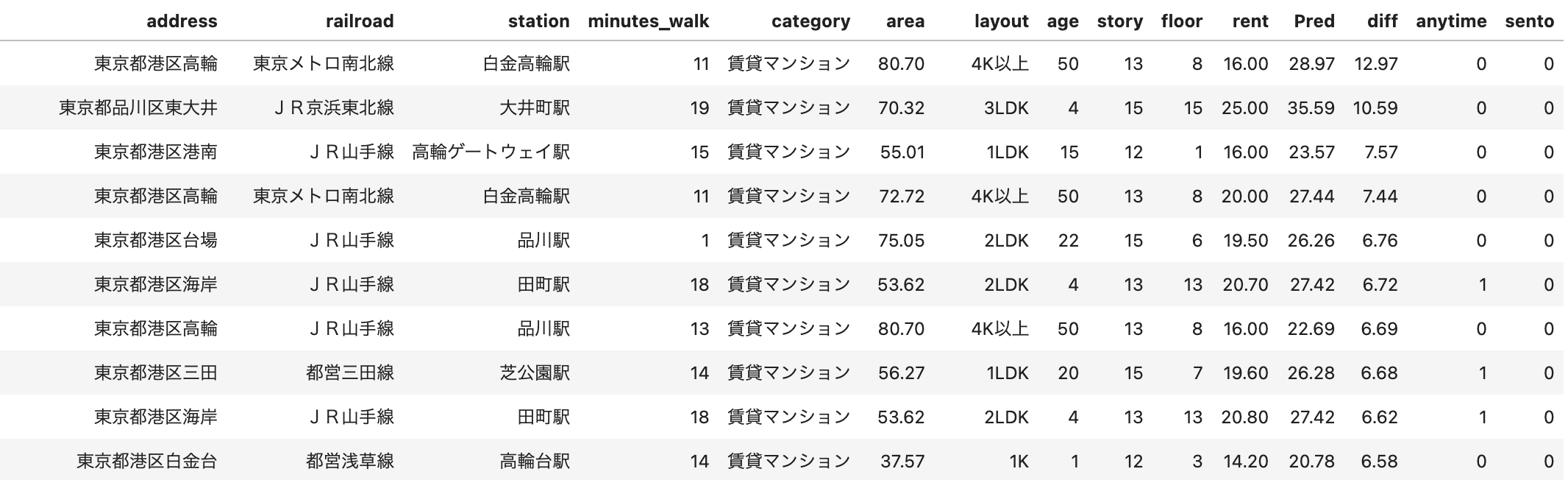 予測(Pred)に比べて実際(rent)の家賃が安い物件TOP10。diffが(予測)-(実際)を表す。anytime列は同一addressにAnytimeフィットネスジムがあることを、sento列は銭湯があることをそれぞれ表す。
予測(Pred)に比べて実際(rent)の家賃が安い物件TOP10。diffが(予測)-(実際)を表す。anytime列は同一addressにAnytimeフィットネスジムがあることを、sento列は銭湯があることをそれぞれ表す。ということでまずは何も考えず、(予測)-(実際)が大きい物件TOP10を見ていきましょう。例えば一番上の物件なんかは予測を信じると約29万円してもおかしくない物件に16万円で住めることができ、その差分約13万円と非常にコスパが良いことが分かります。
特徴量を見ても、築年数こそ50年以上と古いですが、高級エリア港区高輪にあり白金高輪駅から徒歩11分、80m2(!)で4K以上と申し分ない条件ではないでしょうか。(ゆえに事故物件である可能性は否定できないですが、、、)
しかし16万円では流石に高すぎます。ということで実際の家賃に上限を設けましょう。
(1)の記事で「8万円以下」を上限にしたのですが、まーこれは目安に過ぎません。8.1万円の物件を切る理由も特にないので、「実際の家賃が10万円以下」の物件に絞ります。
コスパ良物件TOP10(家賃上限10万円)
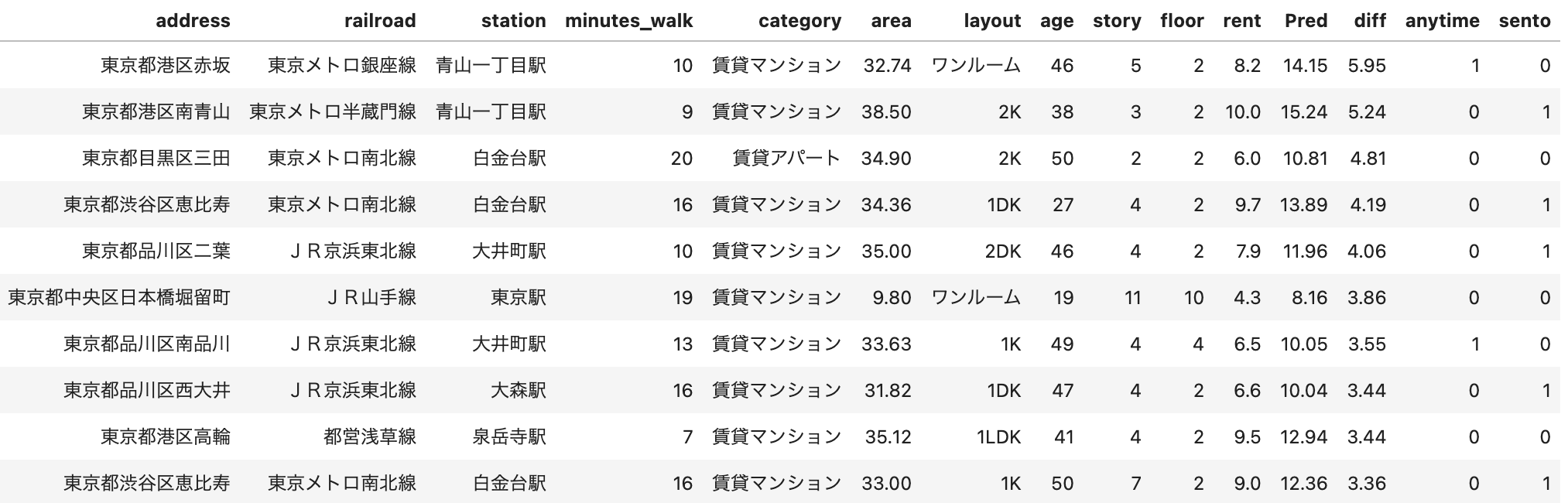 上の表と同様だが、実際の家賃(rent)が10万円以下の物件のみ表示。
上の表と同様だが、実際の家賃(rent)が10万円以下の物件のみ表示。一位は予測と比べて約6万円もお手頃な家賃8.2万円の赤坂のワンルームのお部屋です。
特徴量を確認すると、住所は港区赤坂でかつ青山一丁目から徒歩10分、32.74m2と申し分ない広さ、同一住所には銭湯こそないもののAnytimeはしっかりあることなどが分かります。
8.2万円でこの条件はとても良いですね〜
友達にも「お前今どこ住んどん?」「赤坂」ってドヤれるし。
他に気になった物件としては13位とランク外なんですが、
「大井町から徒歩11分、築39年、52.75m2の2LDK、5階建ての最上階で家賃8万(予測10.92万)」
みたいなのもありました。これもめちゃくちゃいい。目的と外れるけど広いから2人でシェアしても快適でかつ家賃4万(やっぱシェア強い)。
こうして気になる物件をいくつかリストアップしたら仲介業者さんの元に向かいましょう。すると「ああこいつはこういう感じの条件で探してるわけね」と察して、不動産関係の方しか見ることのできないデータベースからより良い物件を紹介してくれたりもします。
もちろんリスト内の物件も(埋まってなければ)そのまま内見可能です。事故物件じゃないかどうかは教えてもらっときましょう。
まとめとか今後の展望とか
ここまで分析を進めてきましたが、適当にやっちゃったところもあるので、まだまだアップデートはできそうです。例えば以下のところか。
- バストイレ別、独立洗面台、洗濯機設置場所、オートロック、宅配ボックスの有無、などなどこだわり条件追加
- 特徴量エンジニアリング(ただ今回の目的は予測ではなく説明なので、過剰な特徴量の追加はむしろマイナスであると考えてます)
- 最寄駅が複数あるときの処理(今は最寄の1駅しか考慮してないので)
- スーパーやコンビニ、体育館、図書館、本屋、公園、飲食店など周辺情報の追加
- 周辺情報を考慮するときの方法(半径◯m以内のような)
- 犯罪率や交通量などの治安・環境のエリア特性検討
- SHAPによる物件ごとの予測理由表示(これは今のデータですぐやりたいかも)
- 写真の利用(なんだかんだ人が選ぶときは「イケてる感」のようなイメージを重視すると思うんですが、これは単純に考えると画像を利用するしかなさそうです)
また、もうちょいシステム面を頑張れば応用例も色々あるかなと。
とりあえず僕が考えている案は以下の感じ。
- 毎日バッチ処理で新規物件を処理してお買い得物件をLINEかなんかでお知らせ
- 仲介業者さんに行って紹介された物件の特徴量を何らかのフォームに打ち込めば、その物件の予測家賃がその場で分かる
この辺、フロー図とか書きたかったんですが、力尽きました。
長くなっちゃいましたが、どなたかの参考になれば幸いです。














