こちらの記事の続きです

TL; DR
- 自動機械学習ツールForecastFlowを使って、SUUMOからいい感じのお得物件を探すプロセスを考えてみたよ
- 本記事は機械学習モデルを作成するためのデータ準備をしたよ
- 加えて、地理空間ポリゴンデータLLocoを使ってエリアごとの家賃相場をプロットしたよ
物件探索のプロセス概要
全記事でも書いてたことの再掲ですが、以下のような手順で進めてました。
本記事では(3)のデータ前処理・可視化を説明します。
(1)探索条件の整理
(2)SUUMO物件データのクローリング・スクレイピング
(3)データ前処理・可視化
(4)機械学習(ForecastFlow)で予測モデル作成
(5)予測モデルによるコスパ良物件の発見
(3)データ前処理・可視化
データ前処理
機械学習モデル作成のためにはまず、適切にデータを整形しなければいけません。一般には特徴量エンジニアリングと呼ばれる、機械学習モデルで最重要とされるパートなのですが、ここでは詳細は割愛させていただきます。
↓こちらのセミナー動画で詳しく説明しているので気になった方は是非。
前記事では、SUUMOから物件データをスクレイピングして以下のような表に格納するところまでを説明しました。
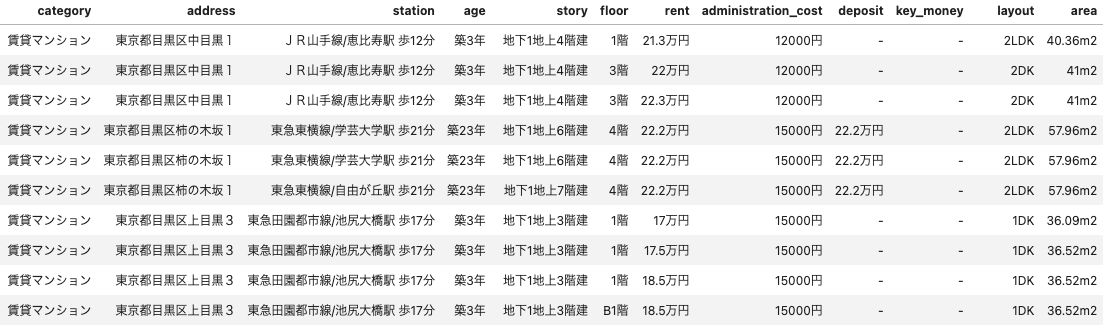
今回はこのテーブルをもとに以下のような前処理を行います。簡単な処理ばかりなので、コードの記載は割愛させてください。
- addressの末尾の数字を消す
- rentの「万円」を消してfloat型に変換
- layoutから「S」の文字を削除(参考)
- storyから地下部分を削除し、地上〇階建の◯の部分を抽出しint型に変換(要は最上階の階数、平屋は1階建とした)
- floor○階の◯の部分を抽出しint型に変換(要はその部屋の階数で、地下は負)
- floorとstoryがNULLの場合、0で置換
- floor/storyを計算しstory_floor_ratioとして格納(5階建ての5階の部屋なら1、10階建ての5階の部屋なら0.5になる)
- ageから築◯年の○の部分を抽出しint型に変換(新築は築1年とした)
- areaから「m2」を削除し、float型に変換
- stationから以下をそれぞれ抽出
- 最寄り駅を改めてstationとした
- 最寄り駅の路線をrailroadとした
- 徒歩○分の◯部分をint型に変換しminutes_walkとした(車の場合は1分を徒歩5分として計算)
さらに分布を確認し以下のグルーピング処理をします。
- rentが40以下の物件のみに着目(お手頃価格な物件における精度を重視するため)
- ageが50年以上の物件は築50年にまとめる
- floorとstoryは15階以上を15にまとめる
- story_floor_ratioは0以下を0に1以上を1に(なぜか3階建ての4階にある部屋とかがあったため)
- layoutは4K以上の部屋を「4K以上」としてまとめる
- areは100m2以上は100m2にまとめる
- minutes_walkは30分以上を30分にまとめる
実は特徴量のグルーピング処理は、ForecastFlowが採用している決定木系のアルゴリズムでは精度向上に寄与しないことが知られています。
なのですが、高カーディナリティの特徴量は正しい結果解釈の妨げになりうるため、このようにしました。とはいえ全体に比する割合は小さいため、大勢に影響は与えないでしょう。
結果的に以下のような表が出来上がりました。
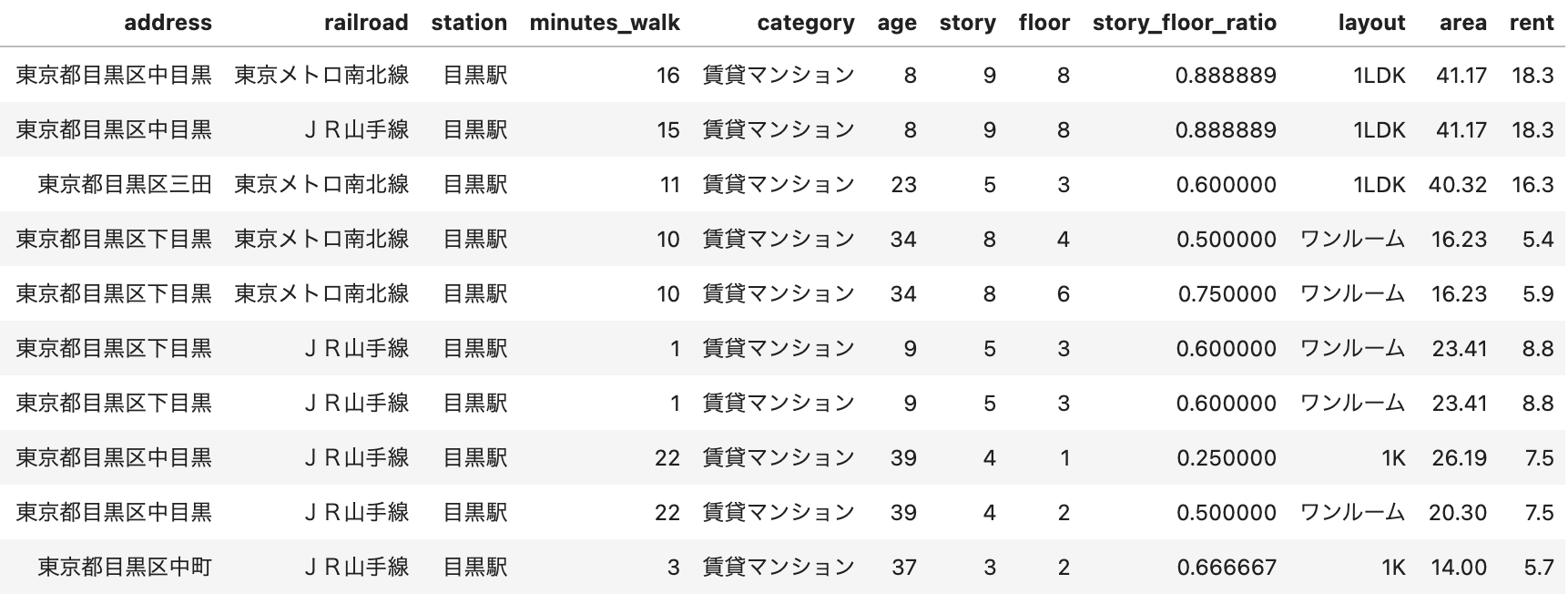
さらにここで前記事で説明した「最寄り駅が会社から5駅以内」のルールで物件にフィルタをかけます。ルール詳細は前記事を参考にしていただくとして、駅のリストだけ再掲しておきましょう(下の表)。要はstation列がこの表にある物件だけを抽出するイメージです。
| JR山手線 | 秋葉原、神田、東京、有楽町、新橋、浜松町、田町、高輪ゲートウェイ、品川、大崎、五反田 |
|---|---|
| JR京浜東北線 | 秋葉原、神田、東京、有楽町、新橋、浜松町、田町、高輪ゲートウェイ、品川、大井町、大森 |
| 都営浅草線 | 戸越、高輪台、泉岳寺、三田、大門、新橋、東銀座、宝町、日本橋、人形町 |
| 都営三田線 | 目黒、白金台、白金高輪、三田、芝公園、御成門、内幸町、日比谷、大手町、神保町、水道橋 |
| 都営大江戸線 | 国立競技場前、青山一丁目、六本木、麻布十番、赤羽橋、大門、汐留、築地市場、勝どき、月島、門前仲町 |
この条件によって残った物件×部屋数は19,861件、家賃の中央値は.11.6万円でした。
23区の中央値が8.5万円であることを考慮すると、若干お高め物件が多いようです。
そもそも会社が23区家賃最高エリアの港区であること、逆に家賃安エリアの葛飾区、江戸川区、足立区、練馬区、杉並区、板橋区がごっそり抜けてしまうことが原因でしょう。(会社から5駅では辿り着けないため)
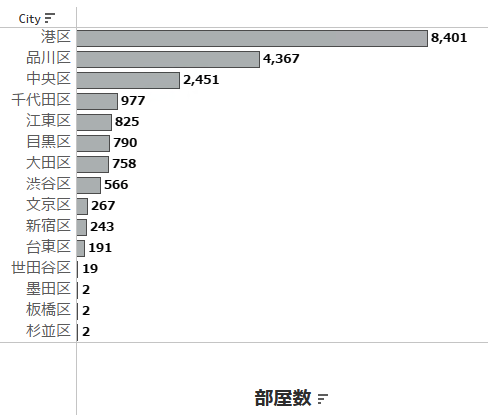
一応区ごとに部屋数を確認しておくと以下のような分布になってます。当然ですが港区が多く、その次に品川区、中央区が続いており、この辺りがボリュームゾーンなようです。
ちなみに墨田区や板橋区、杉並区は「東京駅からバスで30分、のちバス停から徒歩10分」みたいな物件が含まれていることが発覚しました。バスか、、、それは想定外だった、、、ただこれらは一旦そのままにしておいて分析します。ボリューム的に問題にならないレベルでしょうから。もちろん理想を言えば前処理に戻るのがベターなんですが。
データ可視化
さて、ここまで準備ができたのですが、このままではあまりイメージが湧きませんね。無機質な情報を羅列されても、イマイチピンとこないのが正直なところです。「会社から5駅」って言われてもどのあたりに物件が存在するのかとか、よく分かんないですよね。
ということで、少しでもイメージを膨らませるために、地図上で物件状況を可視化してみましょう。エリアごとに家賃相場が色付けされたものをイメージしてください。
ただ実は、このエリア可視化の時に地味に問題となるのがその粒度です。
というのも、区のレベルだと表でみたレベルで十分だしもう少し細かく見たい、でも政府統計情報として無料で使える町丁目レベルだと細かすぎる、、、
この辺りのお悩みポイントとソリューションに関しては、以下のブログで詳しく紹介してますので詳細は割愛しますが、要点だけを抜き出すと、ちょうどいい粒度として「7桁郵便番号」を使うのがベストプラクティスです。

でも町丁目粒度を郵便番号粒度にするのって明らかにめんどくさそう、、、だって町丁目は結局行政上の都合がいい区分だけど、郵便番号は郵便物の配達上都合がいい区分であって、両者は魔の多対多対応となりそうです。
そんな皆様のために、我々が準備しました。郵便番号粒度のポリゴンデータ。
それが「LLoco」です。詳細は下のURLから確認してください。
では早速このLLocoを使ってエリアごとの物件状況を確認してみましょう。
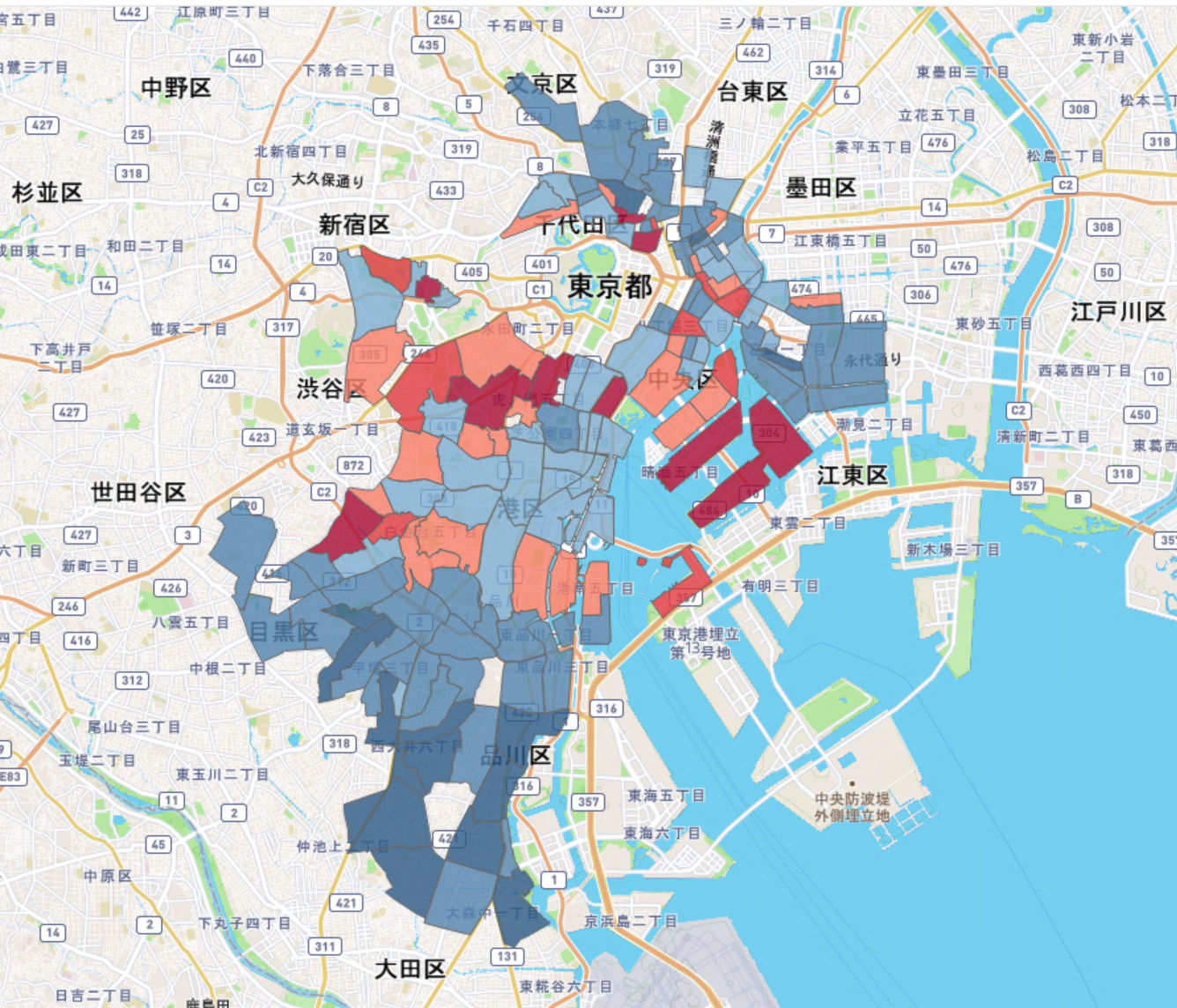 郵便番号ごとにそのエリア内に存在する物件の家賃中央値で色付け。 濃い赤に行くほど家賃が高いエリア、濃い青に行くほど家賃が安いエリアを表す。
郵便番号ごとにそのエリア内に存在する物件の家賃中央値で色付け。 濃い赤に行くほど家賃が高いエリア、濃い青に行くほど家賃が安いエリアを表す。
郵便番号ごとに家賃中央値で色付けしたマップです。要はエリアごとの家賃相場だと思ってください。一点注意としては、物件があまりにも少ないと中央値であっても容易に外れ値になるため、物件が10件以上存在する郵便番号エリアのポリゴンのみ表示しています。
どうでしょう、こうして地図上に可視化してあげると一気により生々しくデータの意味を読み取れる気がしませんか?これがロケーションインテリジェンスの威力ですね。
また、この粒度であれば、同じ港区でも家賃が高いエリアと比較的低いエリアが混在していることがハッキリ分かります。当然この違いは市区町村の粒度で見ていると分かりません。
逆に、これよりも粒度が細かいと存在する物件があまりにも少なくなったり、意味のある地域性を反映しなくなったりします。
我々が推す「7桁郵便番号粒度がベストプラクティス」という意味がなんとなくお分かりいただけたでしょうか。
さてマップを少し眺めてみると、品川区〜大田区あたりが狙い目に見えます(青が濃い=家賃が安いエリア)。
逆に家賃が高いエリアは以下のようなところです。(下図参照)
- 台場・豊洲・晴海・勝どきといったタワマンが並び立つ臨海エリア
- 青山・六本木・赤坂などもはや勝者の称号と言っても過言ではない勝ち組エリア
- 落ち着いた高級住宅街の白金台やオシャレ女子・業界人の巣窟(個人の偏見)中目黒が続くエリア
そりゃそうだろな、という感じで納得感がありますね。
ちなみに、会社のある位置は★印の港区芝公園で、ちょうどその3つのエリアに挟まれるような位置に存在しています。オフィス街であることもあってか、家賃自体はそこまで高いわけではないようです。実は狙い目なのかもしれません。
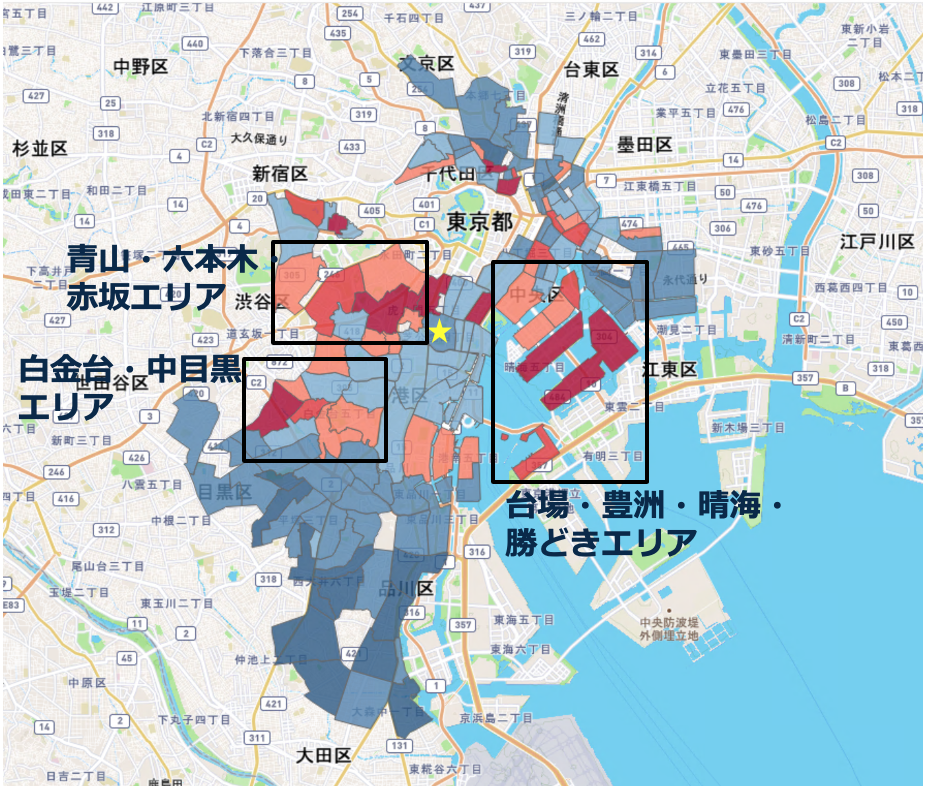 上の図と同様。
上の図と同様。家賃が高いエリアの説明を追加し、会社の位置を★印で表している。
さて、データ前処理・可視化とすることでだいぶデータの雰囲気が掴めてきました。
本記事はこの辺にしておいて、いよいよメインである機械学習モデルの作成とその予測結果によるコスパ良物件の探索を後続記事で書いていきます。