
強化学習の目的を整理
強化学習は、ある特定な状態下で、最大限の「ご褒美(報酬)」をもらうために、どのような行動をとるべきかを学習するための機械学習の一分野です。
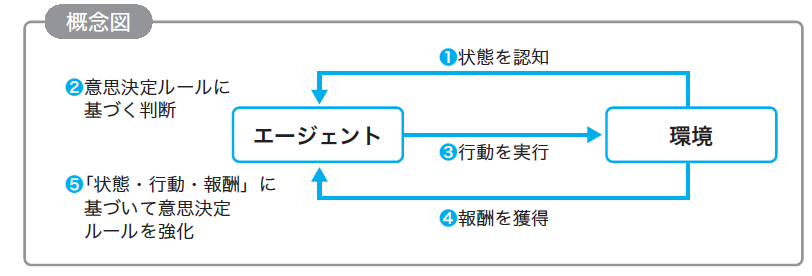
図の出典:『ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[明瞭解説+良質問題]』
強化学習において、報酬を最大にするために行動を求める際に、主に2つのためのアプローチがあります。
①最適な方策を直接的に見つける
② 行動価値関数を最大にするような行動を求める
この2つのアプローチの間には、最適化に使用する関数など共通の要素も多いため、体系的に理解することがなかなか難しいと感じます。したがって、以下では両者の違いを可能の限りわかりやすく説明したいと思います。
執筆者が研修コースや書籍を出している「G検定」という分野でも、強化学習の理論や応用例がたくさん出題されており、受験者にとってはもちろん、受験者を指導する講師としても難しい内容のように感じます。
① 最適な方策を直接的に見つける
最適な方策を直接的に導き出す手法として、方策勾配法(Policy Gradient Method)が代表的です。ここで、「方策」とは、「ある状態において行動を選択するための作戦」と言い換えることができます。方策をパラメータで表現可能な関数とし、累積報酬の期待値が最大となるように、関数のパラメータを勾配降下法を用いて逐次的に更新しながら、直接的に方策を最適化します。
方策勾配法は、ロボット制御など、特に行動の選択肢が多い場合に使われます。なぜならば、そのようなケースでは各行動の価値を1つひとつ計算するのは計算量が膨大になってしまい、代替案としてパラメータを最適化するアプローチをとった方が良いという判断になります。
しかし、方策を最適化することが難しい時もあり、その時は②のアプローチが使われます。
② 行動価値関数を最大にするような行動を求める
ある状態と行動から得られる将来の累積報酬の期待値を、その状態と行動の価値とします。その価値が最大となるような行動を導き出すことで、最適な行動を選択する能力が間接的に得られます。このタイプの手法として、Q学習が代表的であり、数多くの強化学習のアルゴリズムに使われています。
具体的に、価値を評価するために、価値関数(Value Function)を用います。状態価値関数(V関数)と行動価値関数(Q関数)の2種類があります。
状態価値関数V(s)は、特定の状態sから開始して方策πに従うときの累積報酬の期待値を表しています。一方、行動価値関数Q(s, a)は、特定の状態sにおいて行動aを取ったときに、将来もらえる割引された報酬の累計の期待値を表しています。Q学習では、ベルマン方程式に基づく動的計画法を使用して行動価値関数Qを更新します。
方策をπとして固定した場合に、ある状態s で、行動a をとった場合の行動価値関数を数式で表すと下式のようになります。
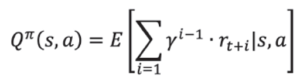
アルゴリズムや問題設定によって、V関数とQ関数、もしくは両方が使われますが、行動価値関数の方が比較的に多く用いられております。「価値関数」というと行動価値関数を指していることが多いです。また、価値関数は方策勾配法を中心とするアルゴリズムでも使用されます。
まとめ
①と②のそれぞれの代表である方策勾配法とQ学習の違いを以下のようにまとめます。
行動の最適化:方策勾配法は、方策自体(エージェントがどのように行動を選択するか)を直接的に最適化しようとします。一方、Q学習は、行動価値関数(Q関数)を最適化することで、最適な行動を選択する能力が間接的に得られます。
関数の更新:方策勾配法は勾配降下法を使用して方策を更新するのに対し、Q学習は、ベルマン方程式に基づく動的計画法を使用して行動価値関数Qを更新します。
安定性と収束性:理論的には、Q学習は最適な価値関数に収束することが常に可能です。一方、方策勾配法は報酬を最大化する方策に収束しようとする中で、局所最適解に収束する可能性もあります。
執筆者:ヤン ジャクリン (GRI 分析官・講師)















