TL; DR
- 自動機械学習ツールForecastFlowを使って、SUUMOからいい感じのお得物件を探すプロセスを考えてみたよ
- 本記事では主にSUUMOから分析に必要なデータを抽出した部分を説明するよ
- プロセスだけ知りたい人はイントロを飛ばしてね
イントロ(そして僕はSUUMOの扉を開く)
どうも、弟と一緒に住んでいる筋肉系データサイエンティスト岡部です。
大抵「仲良いね〜」とか「微笑ましいね」などのコメントをいただくことが多いのですが、10代〜20代前半のピチピチヤングボーイたちが同居してるならともかく、アラサー独身男性が二人同居しているものはそう微笑ましいものではない(断言)
Tシャツを脱いで半裸になり鏡の前で己の肉体に惚れ惚れしているところを見られたり、
後で食べようと冷蔵庫に入れておいたプロテインバーがなくなっていたり、
家に帰るや否やくっせえ匂いがするなと思ったら寸胴鍋で豚骨が煮込まれていたり、
食べ終わった後の食器をどちらが洗うかでチキンレースが始まったり、、、
そんな良いものではない(断言2)
ではなぜ二人暮らしをしているのか?
家賃が高いからです
ちなみに「東京は物価高いよね〜」とはよく聞くんですが、個人的には飲食店やスーパーなんかはお店が多い分競争も激しく、むしろ田舎よりも安い所なんかも合ったりします(探せば)。
だが家賃、てめえは別だ
地元広島の友達が駅近・市街地の一等地に1LDKの超綺麗なマンションの一室を月7万円で借りてる話や、京都に行った友達が「5万出せば1DKの新築に近しい物件借りられる(実際借りてる)」と豪語していた話を聞くと、聞くに堪えない。
都内だったら、7万とか比較的都心のアクセスいい立地であればワンルームがせいぜいだし(というかその条件だと普通に8万するまである)、5万とか多少交通の便を我慢したとしても、ワンルームがせいぜいです。
しかし、家賃が高くても割り算の威力は甚大です。例えば10万の家だとしても二人で住めば一人当たり5万。しかもDKとかLDKのおまけ付き。さらに「生活費は世帯人数のルートに比例して増える」という経験則もあり、それに基づくとざっくり出費が0.7倍程度に抑えられることになります。実質年収1.4倍じゃ(暴論)。
さて、こういう適当なことを言っているとそろそろ、「いい物件を見つけられないのはお前の検索能力が低いからじゃ」とお叱りを受けそう、、、
でも一生で90回以上引っ越しを繰り返したと言われている歌川広重でもない限り、普通の人は引っ越しなんて一生で数回程度が関の山。
そんなPDCAが回せない状況の中、お得物件を見つける/家賃か適正価格かどうかを見極める、なんて難しくないですか、、、??
しかも引っ越しの時期というのは一般にライフステージの節目であることが大半。そんな他の雑務も膨大にあるクソほど忙しい時に悠長に家のことだけ考えてる暇はないわけです。
では、我々は個人キャッシュフローで最大の支出を占める家賃に対し無力であり続けるしかないのか?悪徳不動産業者の言いなりになるしかないのか?
(実際のところ、個人の経験でしかないけど、不動産仲介業の人はめっちゃ親切。具体例はキリなく出てくるので割愛。)
否。
我々にはあの緑色でふさふさの先輩がついている。そう、SUUMO先輩がね。
ということで、先輩のお力を借りれば、私のような凡夫でも自分の要望に見合った素晴らしい物件を探し出すことができるはず。
豚骨の匂いから抜け出し、鏡の前で好きなだけプロテインバーを謳歌する
そんな夢の一人暮らしへの期待で胸を膨らませ、私はブラウザの検索コンソールに「SUUMO」と、そう入力しました。
本記事はそんなノリの内容です。
物件探索のプロセス概要
物件の探索ですが、以下のような手順で進めていきます。
本記事は(2)まで説明し、(3)以降は次の記事で記述していきます。
(1)探索条件の整理
(2)SUUMO物件データのクローリング・スクレイピング
(3)データ前処理・可視化
(4)機械学習(ForecastFlow)で予測モデル作成
(5)予測モデルによるコスパ良物件の発見
(1)探索条件の整理
では改めて僕が住みたい物件の条件を整理していきます
- 会社の最寄り駅から5駅以内(がその物件の最寄り駅)
- 予測家賃よりも実際の家賃が安い
- 家賃は8万円が上限
- 近くにフィットネスジムがある
- 近くに銭湯がある
それぞれ補足していきます
会社の最寄り駅から5駅以内(がその物件の最寄り駅)
実は弊社には福利厚生の一環で「会社から5駅あるいは5km圏内に住んでいれば初期費用を〇〇万円まで会社が負担」という職住近接支援金制度があります。(〇〇がいくらなのか気になった人は、採用情報から弊社にコンタクトしてきてね。けっこう貰えるよ。)
とするとこの福利厚生を使わない手はない。タイトルの「会社の近く」はこのルールに基づいて定義することにしましょう。
会社の位置はここで、最寄り駅は「浜松町駅」「大門駅」「芝公園駅」「御成門駅」の4つです。
ただ実はこのルール、意外と解釈に任意性があって、例えば
- 会社から5駅とは、快速の場合は停車駅だけ考慮する考え方でいいの?
その場合「浜松町(京浜東北線快速)→東京(東海道線のぞみ)→品川→新横浜→名古屋→京都」となって京都駅に住んでも貰えるの? - 5kmってオフィスからどこまでが5kmなの?家のピンポイントな位置?それとも住所エリアの代表的な地点?階建ての場合3次元的な距離も考慮するの?だったら地球の曲率を考慮した距離で計算するの?
などなど(後者の後半は物理学徒的ないちゃもん。どの定義だろうと変わらんと思う)。
実態としては、「そこんとこかっちり決めるのも手間だし面倒なんで、常識的な範囲でよしなにやってください」ってところでしょう。
なので今回は簡単のため、定義が揺れないであろう5駅ルールだけを採用し、快速なし、乗り換えなし、のシンプルなルールを採用します。
具体的には以下の駅が最寄りである物件を探索します。(赤字は基準となる駅、また路線ごとに表にしているので重複があることには注意)
| JR山手線 | 秋葉原、神田、東京、有楽町、新橋、浜松町、田町、高輪ゲートウェイ、品川、大崎、五反田 |
|---|---|
| JR京浜東北線 | 秋葉原、神田、東京、有楽町、新橋、浜松町、田町、高輪ゲートウェイ、品川、大井町、大森 |
| 都営浅草線 | 戸越、高輪台、泉岳寺、三田、大門、新橋、東銀座、宝町、日本橋、人形町 |
| 都営三田線 | 目黒、白金台、白金高輪、三田、芝公園、御成門、内幸町、日比谷、大手町、神保町、水道橋 |
| 都営大江戸線 | 国立競技場前、青山一丁目、六本木、麻布十番、赤羽橋、大門、汐留、築地市場、勝どき、月島、門前仲町 |
予測家賃よりも実際の家賃が安い
本記事のコンセプトです。要は「この物件駅近だし、2DKなのに、なぜか安いね」みたいな物件を探したいわけです。
完全に余談ですが、実はあまりにも相場と比較して安すぎると事故物件の可能性があります。実際、個人の実体験なのですが「駅から徒歩3分で築10年オートロックで2LDKなのに家賃7万円」みたいな物件を見つけ意気揚々と仲介業者に尋ねてみると、実は事故物件だった、みたいなことがありました。
とはいえ、そんなもの事前にわからんので(大島てるさんのサイトからクローリングすれば分かるんかもしれんが面倒なんで)、今回は実際の家賃が予測結果よりも安い物件をリストアップすることにします。
家賃8万円が上限
ぶっちゃけ家住むだけなのに8万円も出したくない。けどあまりにも物件が少なくなっても分析が面白くないので、渋々これくらいにしといてやります。
近くにフィットネスジムがある
must条件です。脳筋系データサイエンティストの生命線。
ここでは世界中に店舗を構え、どこの店舗にも一つのキーで入店できるAnytime様が近くにあることを条件としましょう。
そしてここで「近くにある」とは「同一地区(=住所から丁目以下を除いたもの)にある」と定義します。(例えば「東京都港区芝公園2-3-6」なら「東京都港区芝公園」まで)同一地区であれば徒歩圏内でしょうしチャリなら一瞬です。
近くに銭湯がある
できれば欲しい。東京銭湯様からデータを抽出します。
近いの定義はフィットネスジムと同様です。
(2)SUUMO物件データのクローリング・スクレイピング
要はサイトからデータを構造化して抜き出すところ。
一番大変と言ってもいいところなんですが、先人たちによる素晴らしい参考サイトがたくさんあります。なので、詳しいデータ抽出に関しては、以下のようなサイトを参考にしていただくとして、本記事では詳しい説明を割愛させていただきます。
- Python – SUUMOで関東一人暮らしお得物件を見つけたい! ~ 不動産賃貸物件スクレイピング
- SUUMO の中古物件情報を Tableau で分析してみる ~データ収集編~
-
【コード解説】PythonでSUUMOの賃貸物件情報をスクレイピングする【requests, BeautifulSoup, pandas等】
あと重要なところですが、クローリング・スクレイピングの時は規約に注意しましょう。
物件の探索範囲ですが、とりあえず23区に存在する物件を全て表示させ、物件の情報を抽出しました。練馬区とか江戸川区とかは絶対5駅じゃ辿り着けないので、やり過ぎな気もしますが、色々比較したくなる可能性も考慮してこのようにしてます。
また、クローリングとスクレイピングは分けて行い、クローリングしてページごとにhtml保存→スクレイピング、の流れにしています。
クローリングとスクレイピングを分けたのは、取得特徴量を増やそうと思った時に、同じ物件に対してデータ抽出を行えるようにするためです。SUUMOのような日々激しく内容が入れ替わるサイトだと、日を跨げば同じ物件が表示される保証はないので、一般に両者は別々に行った方がベターです。
ちなみにクローリングは2022年6月に実施したので、他の方が結果を全く同じ再現するのは不可能です。結果に再現性がないのはサイエンス的にはNGなんですが、できないものは仕方ありません。そこで本記事では、具体的な結果ではなく分析のプロセスに焦点を当てることで、プロセスの方に再現性を持たせるようにします。
今回は第一弾ということで以下の情報を抜き出しました。物件の一覧ページで取れる情報だけで、部屋のページまで見に行かないと取れない情報は見送ってます。
また、複数の部屋が公開されている物件も存在し、その場合は部屋ごとに1レコードとしました。1階と10階では家賃も異なるなどの状況を想定しているためです。
一応URLも取得して、ページごとに取れる特徴量を拾いに行く気持ちは見せていますが、多分今となってはリンク切れのものも多いはずです。(本当はクローリングの時にこのページもhtmlで保存しておかないといけなかった、、、)
| 物件名(name) | 物件の名前 |
|---|---|
| カテゴリ(category) | マンションかアパートかといった物件のカテゴリ |
| 住所(address) | 町丁目までの住所(番地まではわからないようになっている) |
| 最寄り駅(station) | 路線と駅、かかる時間(一番近い駅のみ格納) |
| 築年数(age) | 築年数 |
| 階建(story) | 物件が何階建てか |
| 部屋の階数(floor) | 部屋は何階にあるか |
| 家賃(rent) | 家賃、予測対象 |
| 管理費(administration_cost) | 管理費 |
| 敷金(deposit) | 敷金 |
| 礼金(key_money) | 礼金 |
| 間取り(layout) | 部屋の間取り |
| 専有面積(area) | 部屋の面積で、玄関ポーチやバルコニーを含まない(参考) |
| URL | その物件のページのURL |
物件名とURLは一応隠して、取得したデータは以下のようなイメージです。
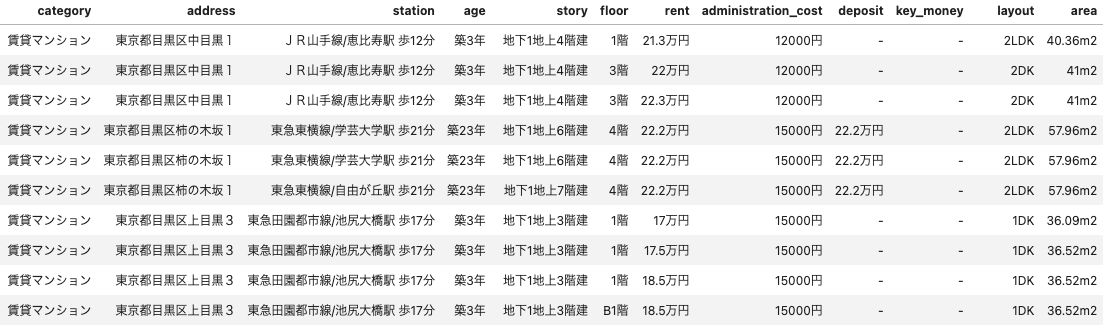
これに加えて、エニタイムと銭湯の存在フラグを住所(address)粒度で持たせました。
こちらの詳細は割愛させていただきます。
結果的にトータルの物件×部屋数は278,382件、家賃の中央値は8.5万円でした。この段階ではまだ23区全体の結果であって、会社から5駅ルールを適用していないことにはご注意ください。
分布としては以下のような感じです。高い側は際限なくかなりロングテールなので、平均で見ると10.4万円になります。流石にこの値は感覚とずれる気がするので、雰囲気は中央値でざっと確認するのがベターでしょう。
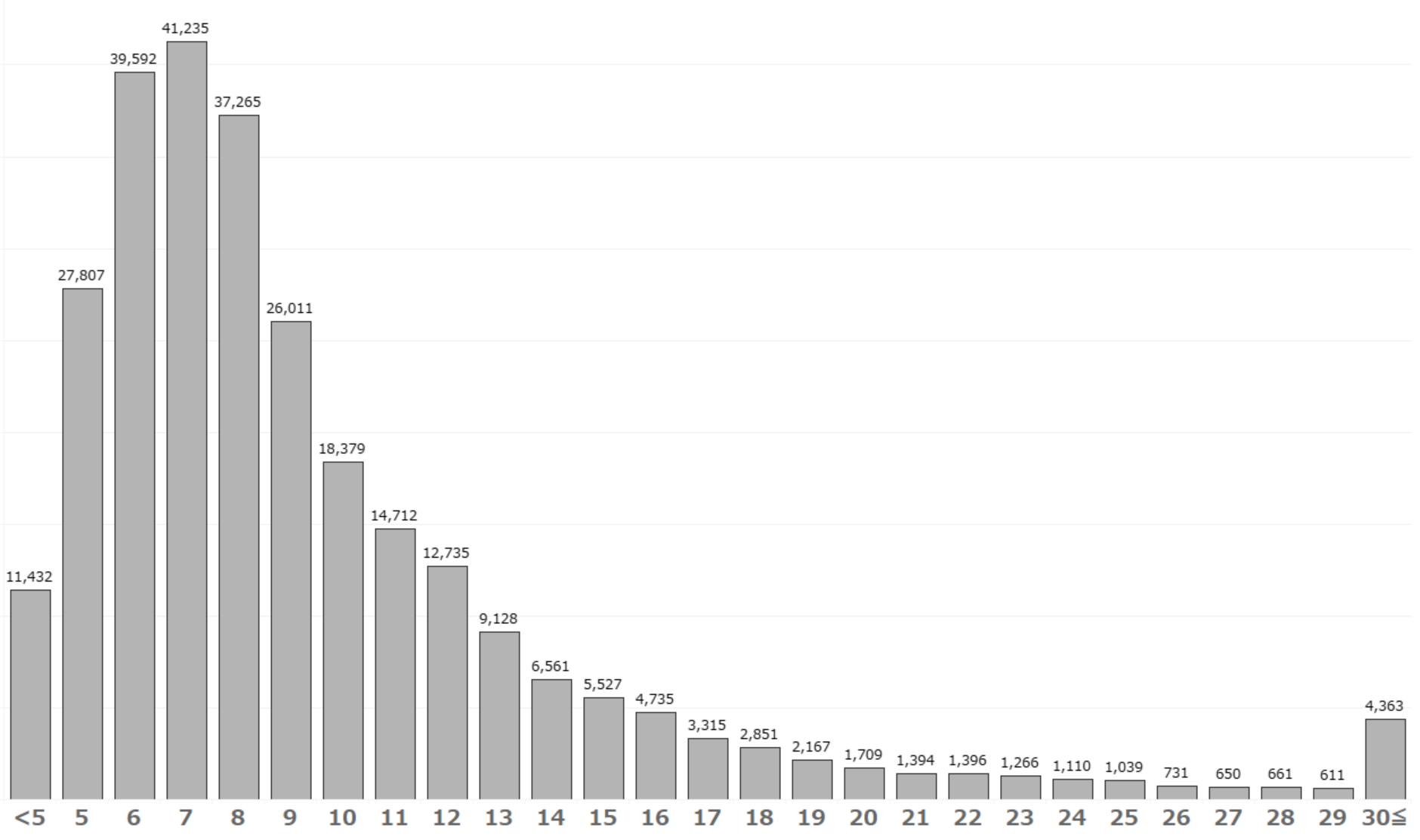 横軸の単位は万円、縦軸は部屋数を表す。「5」とある棒は5万円≦家賃<6万円の部屋が該当。視認性を上げるため、5万円未満と30万円以上の部屋はまとめた。
横軸の単位は万円、縦軸は部屋数を表す。「5」とある棒は5万円≦家賃<6万円の部屋が該当。視認性を上げるため、5万円未満と30万円以上の部屋はまとめた。
区ごとに確認すると下のようになります。やはり港区高い、、、隣接する中央区や千代田区、渋谷区なんかも軒並み高いですね。だからこそ相場だけに惑わされず、会社に近くてお手頃な物件を探す必要があることがわかります。
あと、このグラフでレイアウトの割合も確認してみたんですが、家賃が高いエリアは結局1DK/1LDKが多いエリアなようにも見えます。職住近接で独身貴族的な「ワンランク上の一人暮らし」をする方々を狙っての間取りでしょうか。
逆に家賃が安いエリアは2部屋以上の物件数が多く、葛飾区や江戸川区、足立区、練馬区など少し都心から離れたファミリー向けの方々を狙ってそうです。
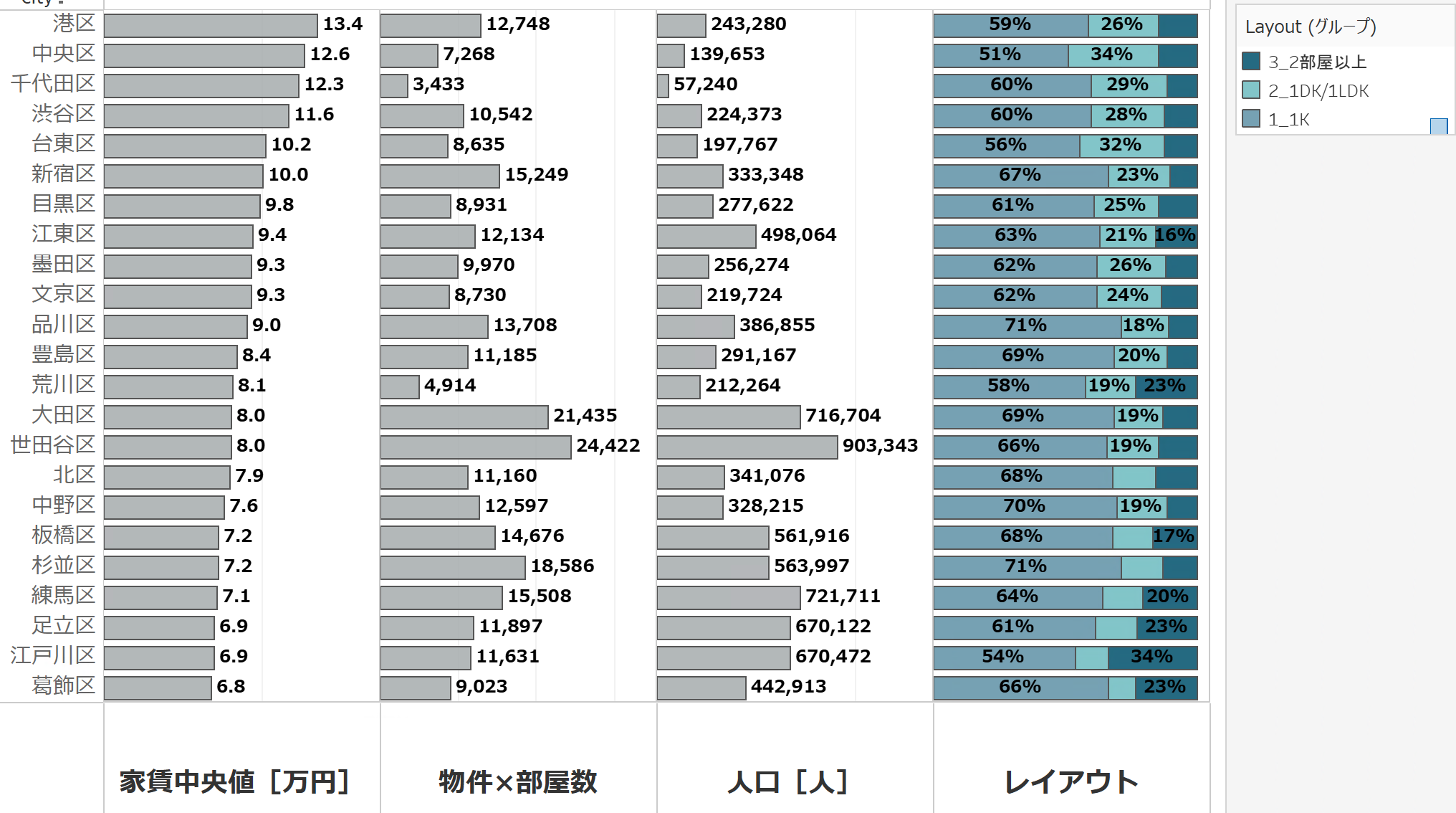 左から区ごとの家賃中央値、物件x部屋数(=部屋数です)、区の人口、レイアウト構成比(ワンルーム+1K→1K、2K以上→2部屋以上としてまとめた)を表す
左から区ごとの家賃中央値、物件x部屋数(=部屋数です)、区の人口、レイアウト構成比(ワンルーム+1K→1K、2K以上→2部屋以上としてまとめた)を表すナイーブに考えると、物件数と人口は比例しそうなもんで、上のグラフでもなんとなくその傾向は現れてます。これを直接的に見るため、下に人口vs物件数のグラフを書きました(人口は2015年のものなので、最新データとは若干の乖離があることに注意)。
やはりバリバリに相関しており、(物件0のエリアは当然人口0なので)原点を通る直線でモデル化すると、R2乗は0.92と非常に当てはまりが良いことが分かります(係数やR2乗の計算はTableauで実行)。
係数がおよそ0.03であることから、(非常に乱暴な仮定ですが)表示物件が1ヶ月で全て契約されるとすると、人口100人あたり3人ほどが毎月引っ越してくる計算になります。
人口に対して物件数が多い区(直線の上側にある区)は順に千代田区、港区、中央区、渋谷区、新宿区で、オフィス街を抱えており職住近接で入れ替わりの激しい単身世帯エリアと見ることができます。そして利便性の良さから総じて家賃が高い。
逆に人口に対して物件数が少ない江戸川区、足立区、葛飾区、練馬区、荒川区は先ほど言った通り、ファミリー層が多いために子育て世帯も多いと考えられ、一度住み始めると比較的長く住み続けるエリアなのでしょう。そして都心から外れるゆえに家賃が安い。
これだけ眺めてるだけでも結構面白いことが色々分かります。
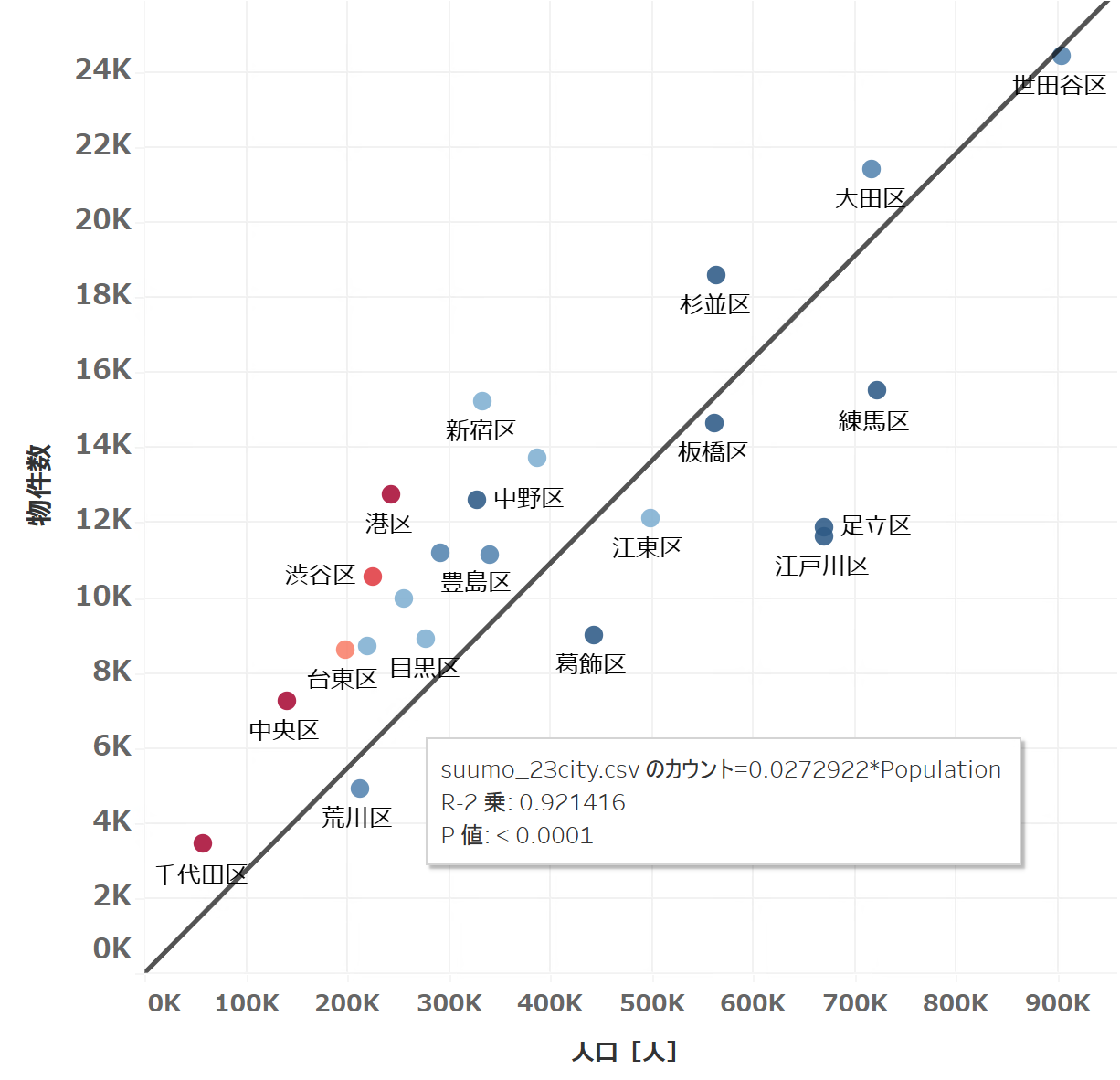 人口vs物件数の散布図。色は家賃中央値(赤に行くほど高い、青に行くほど安い)。直線は原点を通る直線でモデル化したもの。「中野区」の文字の真上にある点は品川区、「豊島区」の文字の真上にあるのは北区、目黒区と渋谷区に挟まれているのが墨田区、台東区と目黒区に挟まれているのが文京区をそれぞれ表す。
人口vs物件数の散布図。色は家賃中央値(赤に行くほど高い、青に行くほど安い)。直線は原点を通る直線でモデル化したもの。「中野区」の文字の真上にある点は品川区、「豊島区」の文字の真上にあるのは北区、目黒区と渋谷区に挟まれているのが墨田区、台東区と目黒区に挟まれているのが文京区をそれぞれ表す。というわけで、データ収集までできたので本記事ではこれくらいにして。
後続のデータ前処理・可視化・分析のタスクは別記事で書いていきます。