
どうも、いつまで経ってもあまりにも花粉症がひどいため血液検査で様々な(スギとかヒノキとかブタクサとかに加えて動物とか虫とかも)アレルギーに対して白黒つけることにした分析官岡部です。(10種類くらいやって5,000円行かないくらいの感じでリーズナブルだった)
※追記:スギとイネにひっかかりました。お医者さん曰く「あんま知られてないけどイネはどこでも生えてるし一年中飛んでるから大変だね〜ガハハ」とのこと。
TL; DR
- 決定木系アルゴリズムを使うときは性別×年代みたいなカテゴリカル変数同士の組み合わせを明示的に入れるとパフォーマンスが向上するケースがある
- とは言え、全てのカテゴリカル変数の組み合わせを調べるのは誤った判断に繋がりかねないので、意味を考えた上で設計するのがベター
- 語りたいことが多すぎてスコープを絞るのが大変だった、余力があれば別記事で色々補足したいし、まとまりがなくて分かりにくいなら指摘してほしい
イントロ
以前の記事で決定木アルゴリズムを使用する時は特徴量同士の四則演算を明示的に特徴量として入れてあげると、精度向上に寄与するケースがあることを紹介し、その振る舞いに関して簡単に議論しました。以下の2つの記事がそれに該当します。

公開当時、その記事を読んだ社内の方々から「カテゴリカル変数でも組み合わせとなる特徴量を入れると精度向上に寄与するケースが多々観測されている」のようなコメントをいただきました。
コメントをいただいた時、そのような状況を簡単に証明するために即座に思いついたケースが後で紹介する「2変数が完全に相関しているケース」でした(カテゴリカル変数なので相関は実は自明ではないのですがノリで把握してください)。
とまあ、思いついてはいたのですが、冷静になって考えると、決定木の最も得意とするパターンだよなとか、流石にこのケースくらいであれば完全に分離してくれるよな、とか色々考えた結果、実験をやらないまま今日まで寝かせてしまったという経緯があります。今思えば簡単な実験だし、思いついた瞬間にやってしまえばよかった。プロシュートの兄貴に「『思いついた』なんて言葉は使う必要がねーんだ、なぜならその言葉を頭の中に思い浮かべた時には、既に行動しちまって終わっているからだ。」などと誹りを受けそうです。
御託はおいておき、今回も非常に簡単な実験を通じて、なぜ特徴量同士の組み合わせを明示的に入れる必要があるのか、どのようなケースで有用なのかを考察していきましょう。
なお今回の記事もF1や特徴量重要度など、機械学習の基礎的な知識がある方を対象にしていますのでご承知ください。
実験に使用したForecastFlow
前回に引き続き、本記事は弊社開発の自動機械学習ツールForecastFlow(内部では決定木系アルゴリズムを使用)を使って実験しました。
再掲ですが、データバリデーション、ラベルエンコーディング、ハイパーパラメータチューニング、特徴量重要度・PDP算出まで一気にやってくれるすげえやつです。
使い方は以下の動画で解説しているのでご覧ください。
決定木アルゴリズムが苦手なデータ分布
天下り的ですが、まずは下のようなデータを用意してみます。とあるECサイトにおける、とある商品の性年代ごとの購買有無の記録だとでも思ってください。idが0-999まで1,000ユーザーの一意のid、genderがそのユーザーの性別、ageが年齢(今回は簡単のため20代と60代しかいないものとします)、targetが商品購入の有無をそれぞれ表します。
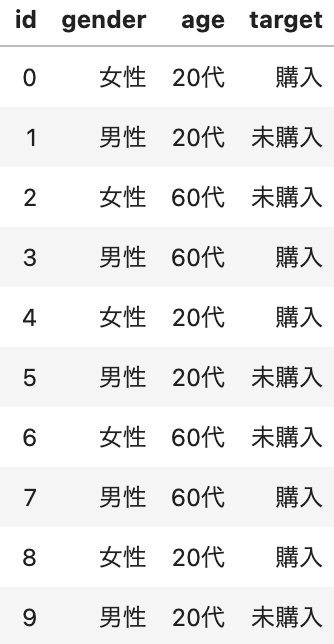
非常に極端なケースですが、集計してみると
- 20代女性が250ユーザー → 全員商品を購入
- 20代男性が250ユーザー → 全員商品を未購入
- 60代女性が250ユーザー → 全員商品を未購入
- 60代男性が250ユーザー → 全員商品を購入
となっているようなデータとなっています。なぜか20代女性と60代男性から圧倒的支持を受けており、20代男性と60代女性からは圧倒的不人気な(謎の)商品です。(下:gender・age・targetでgroup byした時のidのカウント)
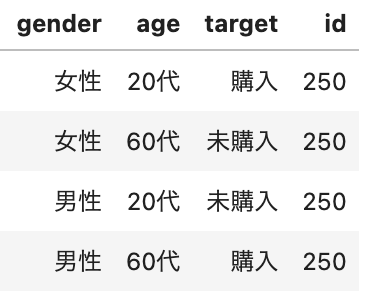
このデータの肝は性別あるいは年齢だけの情報では購入か未購入かは分からないことにあります。つまり、女性も男性も購入と未購入は半々、同様に年齢で見ても、20代と60代は共に購入/未購入が半々というようなデータになっているということです。両者の情報を組み合わせて初めて完全に購入/未購入ユーザーを分類することができます。
これを冒頭でも触れたように「2変数が完全に相関しているケース」と呼称しましょう。
(かっこよく言ってますが要はXORです)
データが準備できたことで、決定木を用いたモデル作成に移行します。今回の問題設定は「ユーザーの性年代情報から各ユーザーの購入の有無が予測できるか?」というものにしましょう。(今のデータ分布で果たしてこのような問題設定に意味があるのか疑問ですが、実験のため極度に状況をシンプルにしています。)
苦手なデータ分布でモデルを作ると…
用意したデータをForecastFlowに入れます。訓練の設定はデフォルトで、精度検証用データは1,000ユーザーに対するものを7(訓練):3(検証)で分割して用意しました。
結果は以下のようになります。
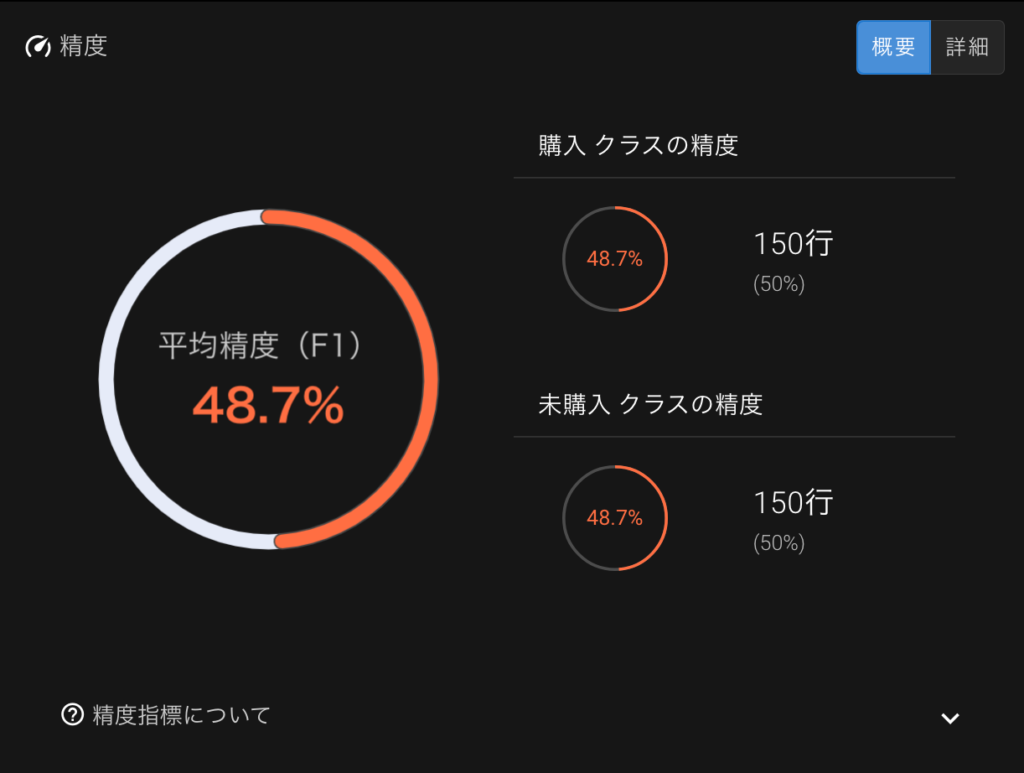
細かいことはいいからF1精度指標としてみてみるとおよそ50%(なんなら少し下回っている)とほとんどランダムな予測をしてしまっていることがわかります。
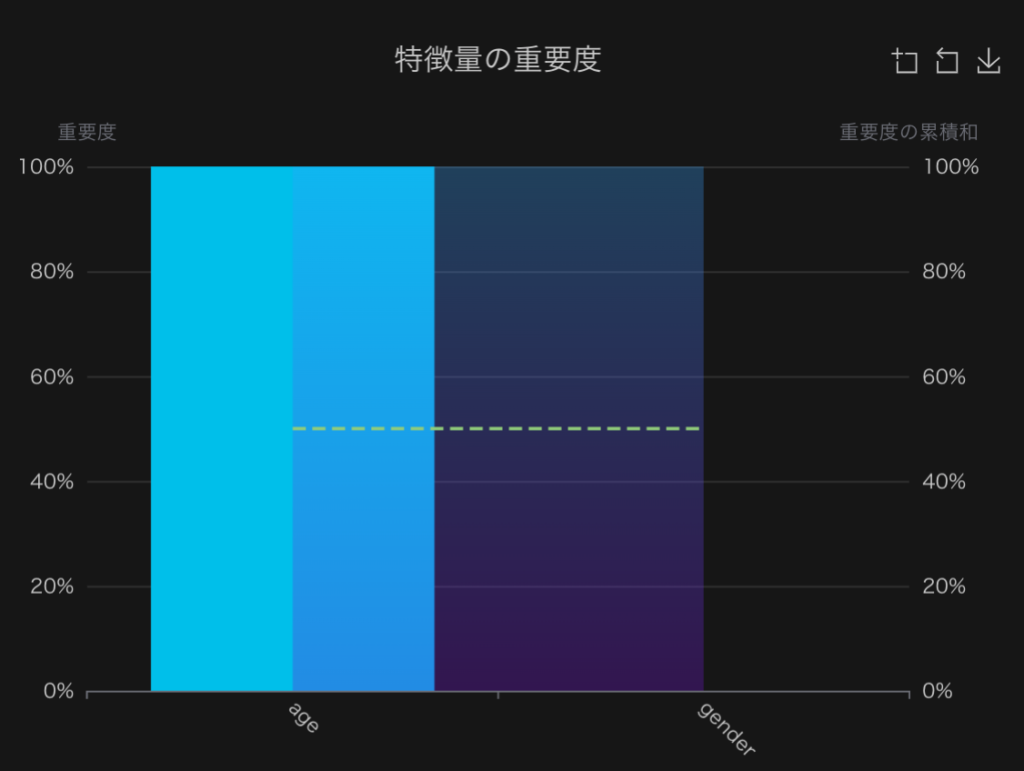
特徴量重要度を見ても(下図)、年齢の情報だけ使っていて、本来分類に使うべき性別の情報は一切無視されてしまっています。
込み入った説明は置いておき(余力があれば別記事で補足するかもしれません)、ラフにイメージだけ説明しておくと、決定木アルゴリズムは先を読んで全体最適になるように分類を行うわけではなく、ある瞬間そのノードにいるユーザーを分類するだけだからです。
今回のケースで言うと、性別で見ても年齢で見ても購入/未購入は半々なので、初手の分割線の引き方がわからなかったんですね。
もし先読みして全体最適するようなアルゴリズムであれば、「今回の分割でエントロピーは減らんが、次の分割で完全に分類できるから、一旦性別で線を引いておこう」といったことをよしなにやってくれるはずですから。
余談ですが、その時の特徴量重要度は自明ではなくなる気がしてきています、つまり性別と年齢で重要度を分かち合うのか、それともどちらか一方に重要度が偏るのか。いずれにしてもベストなのは組み合わせ特徴量を入れることであるのは間違いありません。
※ちなみに、本件に関して社内の人と雑談していると「Lookahead Decision Tree Algorithmsなる先読みする決定木アルゴリズム、ありますよ」(参考:Lookahead Decision Tree Algorithms)と教えてもらいました。
今回は詳細まで説明しないので、気になる方は上の記事を読んでみてください。こちらも余力があれば別記事にて紹介したい気持ちはあります。(するとは言ってない。)コンセプトは分かりやすいのでイメージは湧きやすいんですが、実際にどこまで機能するのか実験してみたいですね。
組み合わせ特徴量を明示的に入れると…
では次に性別と年齢を組み合わせた特徴量を追加してモデルを作成してみましょう。用意するのは簡単で、以下のgender_ageのように単純に年齢と性別を文字列として結合しただけの特徴量を作ります。
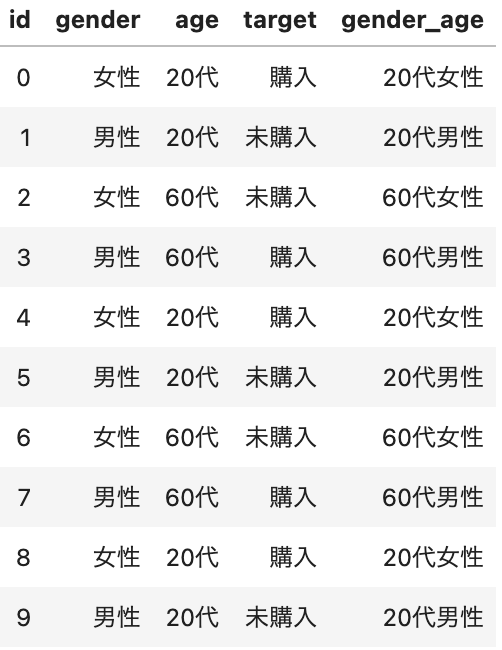
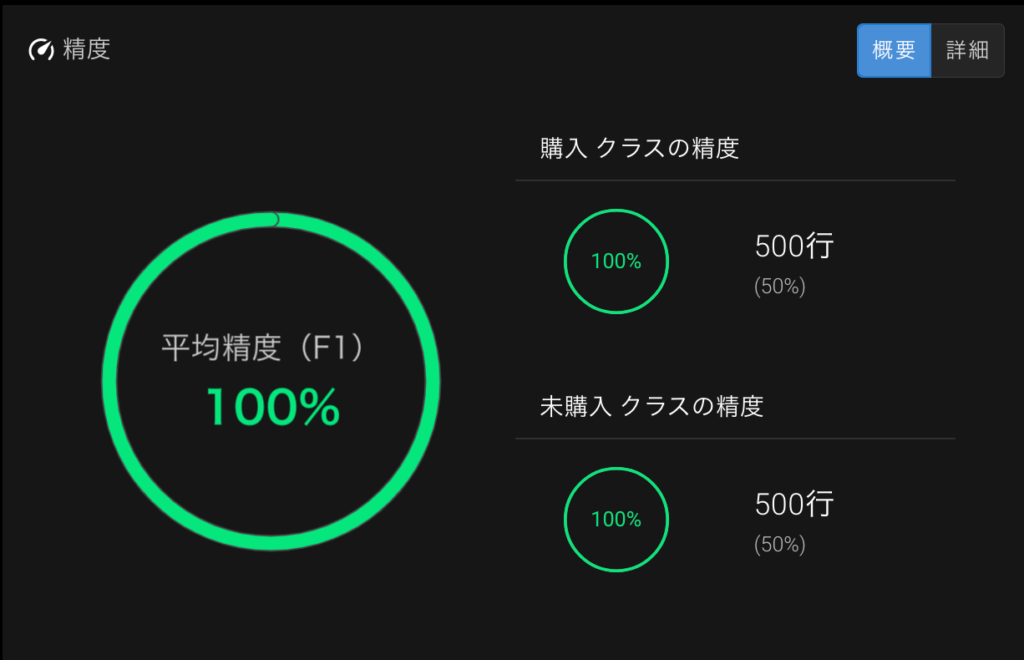
このような列を追加してForecastFlowでモデルを作ってみると、当然以下のように精度は100%となります。(そうなるようにデータを用意したので。)
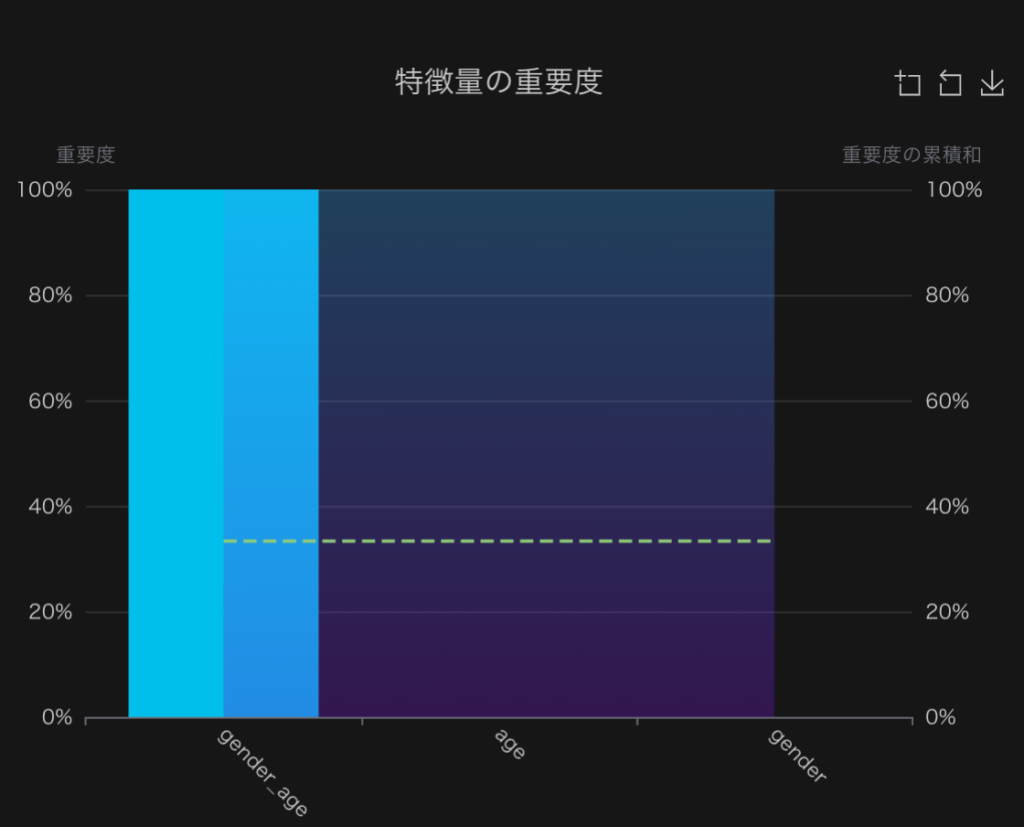
特徴量重要度も当然以下のようにgender_ageだけで全てが決まっており、
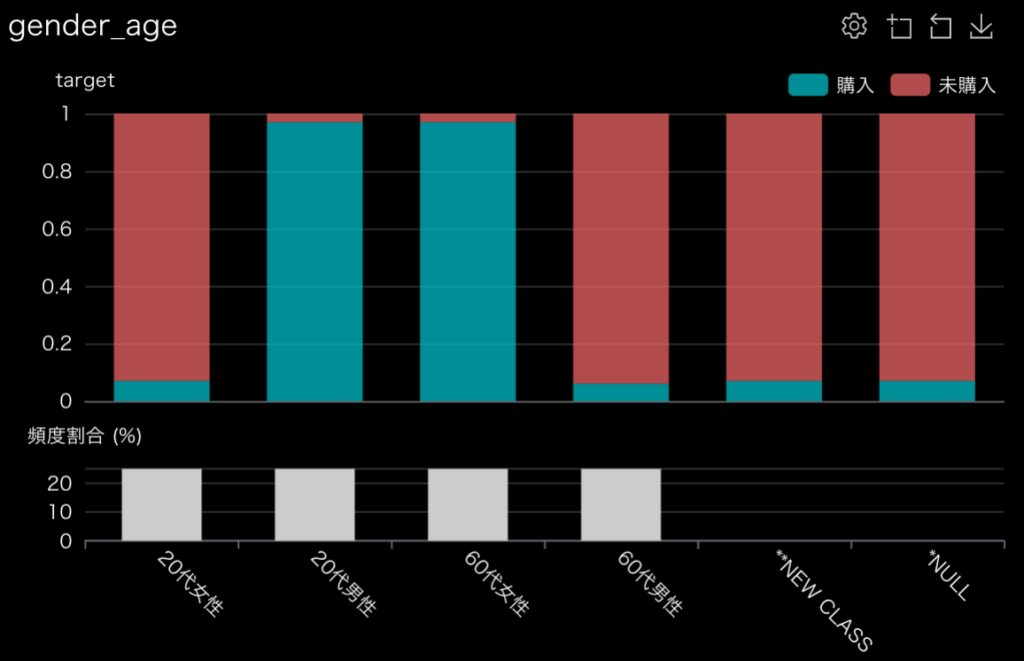
PDPもちゃんと性年代の組み合わせごとにくっきり特徴が出ていることがわかります。
実務でモデル作成をするときはどうすればいいのか?
- サービスへの流入経路×契約サービスのプラン
- 資料請求ページアクセス時のデバイス(スマホ/PC)×アクセス経路(自然検索/ニュースサイト/ダイレクトetc.)
- Webサービスアクセス時のOS×ブラウザ
そして、例えドメイン知識に乏しい場合でも自分なりに仮説を立ててデータを探索し(弊社では「データにダイブする」などと言ったりします)、得られた結果をもとに仮説検証していく、それがデータ分析に携わるものの基本所作なのだろうと考えております。
結論
というわけで、当たり前のことではあるんですがデータを見て、意味を考えながらアクションを考えながら分析しましょう(主に自分への戒め)。確かに、前処理や特徴量設計なんて面倒なことはやらず、持っているデータを入れたらガラガラポンで結果を返してくれるAIがあればなんと素晴らしいでしょう、とは思います。が、現実的にそのレベルのAIが実用化されるにはしばらく時間がかかると思うので、当分は人間とマシンとが協業することでインパクトのある分析結果を生み出していくのがいいのではないでしょうか。












