
こんにちは。分析官のA.K.です。今回はBigqery(以下、BQ)上にあるテーブルをGoogle Cloud Storage(以下、GCS)にcsvファイルとして定期的に移行する方法を紹介しようと思います。SQLベースで実装する方法と、Pythonベースで実装する2つの方法を紹介するので、自分が慣れている方法で行ってみてください。
目次
- SQLベースで実装する方法
- Pythonベースで実装する方法(次回)
SQLベースで実装する方法
SQLベースで実装する場合には、BQのワークシート上にGCSへ出力するクエリを書き、記述したクエリをクエリスケジューラーで定期実行させるやり方です。
基本的なクエリは下記の通りです。(参照リンクはこちら。)
EXPORT DATA
OPTIONS (
uri = 'gs://bucket/folder/*.csv', #ファイルの出力先gsutil URIを指定
format = 'CSV', #ファイルの出力形式を指定
overwrite = true, #ファイルの上書きを指定
header = true, #ファイルヘッダーの有無を指定
field_delimiter = ',') #ファイルの区切り文字を指定
AS ( #「AS」以降に出力したいデータのクエリを記述
SELECT field1, field2
FROM mydataset.table1
ORDER BY field1
);今回はサンプルデータとして「iris」のデータをBQ上に用意して、こちらのデータセットから「Versicolor」種のデータのみをcsvとして、GCSに移行させてみたいと思います。
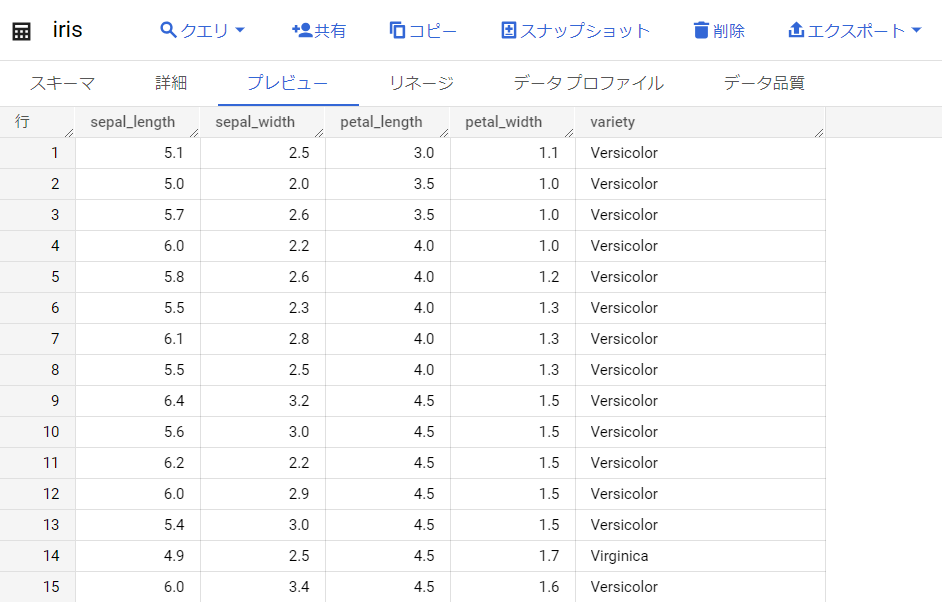
上記データを下記のコードを使用して、GCSの「blog_sandbox」というバケットに移行させてみたいと思います。
EXPORT DATA
OPTIONS (
uri = 'gs://blog_sandbox/iris/versicolor_*.csv',
format = 'CSV',
overwrite = true,
header = true,
field_delimiter = ',')
AS (
SELECT *
FROM blog_sandbox.iris
WHERE variety = "Versicolor"
ORDER BY petal_length
);いざ、実行。
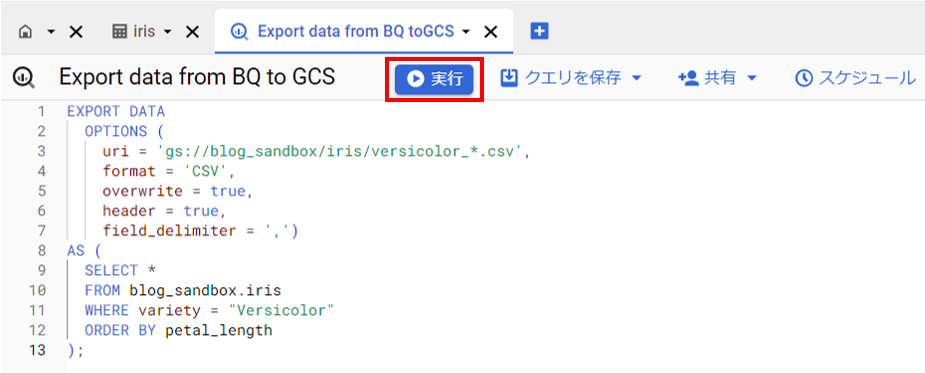
GCSの方を見てみると、無事csvファイルが作成されていました。また、クエリのuriオプションで「/iris/」を指定したため、バケット内に勝手フォルダの階層が生成されて、フォルダ階層の配下にデータが出力されました。
あとは、先ほどのクエリを定期実行できるように設定するだけです。設定方法はBQのワークシート上の「スケジュール」を押すと、スケジューラーの設定画面が開くので、そちらから設定を行います。
(※ただし、初めて使用する場合にはGCPのAPIの有効化を求められます。)
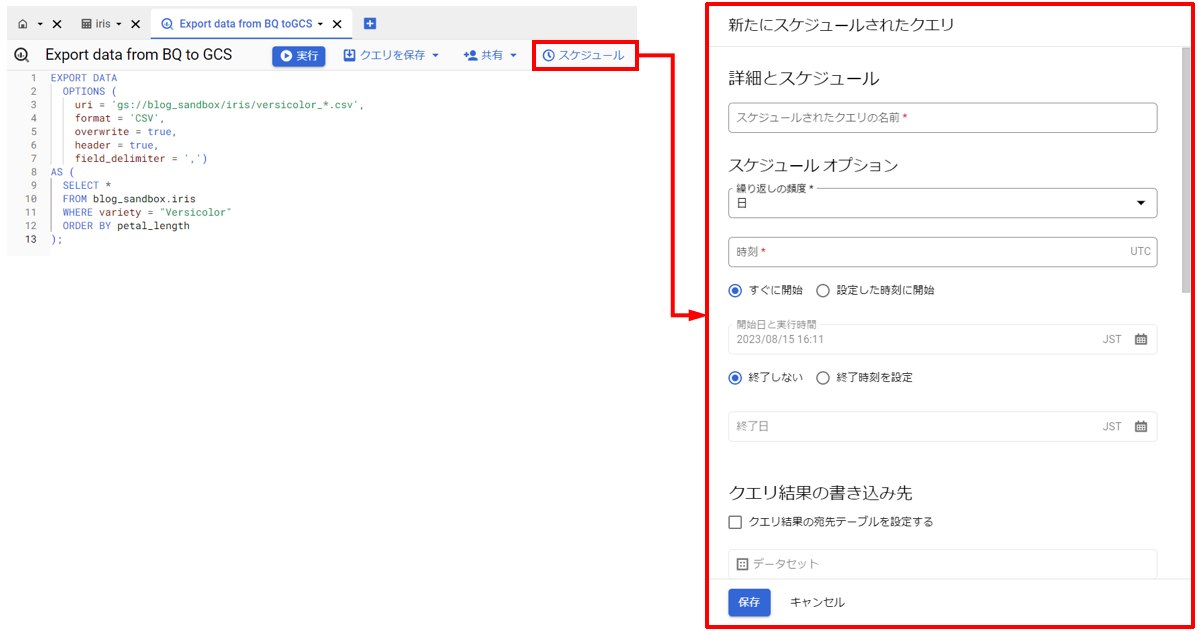
スケジューラーの設定項目は下記の通りです。
- 詳細とスケジュール
- スケジュールされたクエリの名前 : 適当な名前を設定
- スケジュールオプション
- 繰り返しの頻度 : スケジュールの実行間隔を指定
- 時刻 : 実行の時刻を設定
- クエリ結果の書き込み先 : クエリの結果を書き込むテーブルを指定する項目。今回はGCSに出力するため、デフォルトを使用。
- 詳細オプション
- 暗号化 : データの暗号化オプション。特にこだわりが無ければデフォルトを使用。
- サービスアカウント : データ転送時に使用するサービスアカウント。BQおよびGCSへの読込・書込権限を持つアカウントを使用。未設定の場合、スケジューラー作成者のアカウントが使用される。
- 通知オプション : スケジューラー実行時に通知を送りたい場合、設定。
各項目の設定が終わったら「保存」を押して完了です。また、設定したスケジューラーはサイドバーの「スケジュールされたクエリ」から参照することが可能です。
さいごに
いかがでしたでしょうか。SQLを使用できる人であれば、比較的簡単に30分くらいで定期的にデータを出力するジョブを作れてしまいます。ただ、記事の中では触れませんでしたが、今回の方法では出力するファイル名に必ず12桁の数字が付いてきてしまいます。これは、BQからGCSのデータ転送をできるファイルサイズの上限が1GBであるため、1GB以上のファイルをデータ転送しようとした場合に自動でファイルが分割されてindex番号を付与してしまう制約が原因になります。
次回は、ファイル名もユーザーが自由に指定できるPythonコードベースのやり方を紹介したいと思います。
次回記事はこちら。














