
こんにちは。分析官のA.K.です。前回に引き続き、Bigqery(以下、BQ)上にあるテーブルをGoogle Cloud Storage(以下、GCS)にcsvファイルとして定期的に移行する方法を紹介しようと思います。今回は、Pythonベースで実装する方法を紹介していきます。
目次
- SQLベースで実装する方法(前回)
- Pythonベースで実装する方法
Pythonベースで実装する方法
Pythonベースで実装する場合には、Cloud Functionsを使用して、BQ上にあるテーブルをGCSへ移行させるためのジョブを作成して、Cloud SchedulerおよびCloud Pub/Subを使用して定期的にジョブを実行させます。今回もサンプルとして前回用意したirisのデータを利用したいと思います。
基本的なアーキテクチャは下記の通りです。
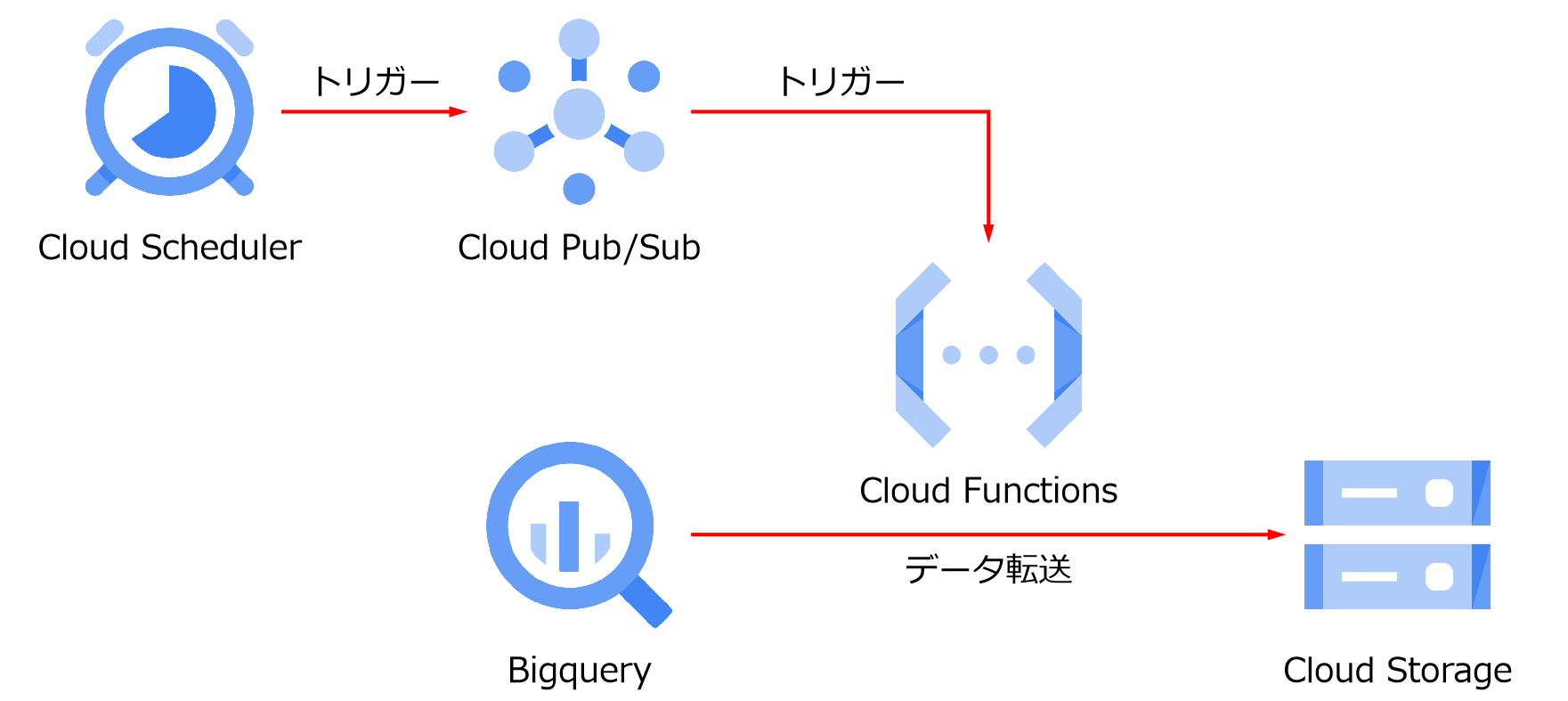
Cloud Functionsの設定
まずは、Cloud Functionsの設定からしていきます。使用する基本的なPythonコードは下記の通りです。(参照リンクはこちら。)

# from google.cloud import bigquery
# client = bigquery.Client()
#BQ側の設定
project = "bigquery-public-data" #出力したいテーブルのGCPプロジェクトを指定
dataset_id = "samples" #出力したいテーブルのデータセットを指定
table_id = "shakespeare" #出力したいテーブルのテーブル名を指定
# GCS側の設定
bucket_name = 'my-bucket' #出力先のバケットを指定
destination_uri = "gs://{}/{}".format(bucket_name, "shakespeare.csv") # 出力先のuriを指定
dataset_ref = bigquery.DatasetReference(project, dataset_id)
table_ref = dataset_ref.table(table_id)
extract_job = client.extract_table(
table_ref,
destination_uri,
# Location must match that of the source table.
location="US",
) # API request
extract_job.result() # Waits for job to complete.Cloud Functionsを構築していきます。Cloud Functionsのコンソールに移動したら、[ファンクションの作成]をクリックして、各種設定を行います。設定項目の詳細は下記の通りです。
1ページ目
- 環境 : 第1世代(筆者が第2世代を使用したことがないため…。)
- 関数名 : 任意の名前を設定。
- リージョン : 適当な場所を設定。基本的にはBQやGCSと同じリージョンを使用
- トリガー
- トリガーのタイプ : Cloud Pub/Sub
- トピックを選択 : [トピックを作成する] > 任意の名前のトピックを作成
- ランタイム、ビルド、接続、セキュリティとイメージ
- 基本的にはデフォルト設定を使用
- 転送するデータが大きい場合のみ、「割り当てられるメモリ」の容量または「タイムアウト」の時間を拡張する
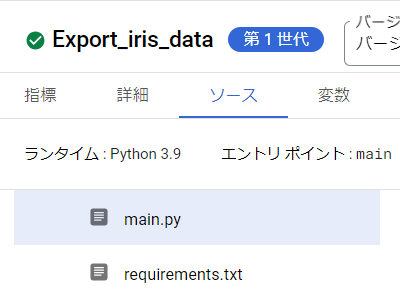
2ページ目
- ランタイム : Python3.9
- ソースコード : インラインエディタ
- エントリポイント : main
- main.py : Pythonコードを記述
- requirements.txt : Pythonで使用するパッケージバージョンを記述
各コードは下記を使用します。
#main.py
from google.cloud import bigquery
def main(event, context):
client = bigquery.Client()
#BQ側の設定
project = "r-and-d-199908" #出力したいテーブルのGCPプロジェクトを指定
dataset_id = "blog_sandbox" #出力したいテーブルのデータセットを指定
table_id = "iris" #出力したいテーブルのテーブル名を指定
# GCS側の設定
bucket_name = 'blog_sandbox' #出力先のバケットを指定
destination_uri = "gs://{}/{}".format(bucket_name, "/iris/versicolor.csv") # 出力先のuriを指定
dataset_ref = bigquery.DatasetReference(project, dataset_id)
table_ref = dataset_ref.table(table_id)
extract_job = client.extract_table(
table_ref,
destination_uri,
# Location must match that of the source table.
location="US",
) # API request
extract_job.result() # Waits for job to complete.#requirement.txt
google-cloud-bigquery == 3.1.0上記が全て設定できたら、[デプロイ]をクリックして、関数をデプロイします。デプロイには5分ほど時間がかかります。デプロイ後、関数の名前の前に緑色のチェックマークがついたらデプロイ完了です。
Cloud Schedulerの設定
Cloud Functionsの設定の途中でCloud Pub/Subの設定は行ってしまったので、残りはCloud Schedulerの設定をすれば完了となります。
コンソールからCloud Schedulerの画面に移動して[ジョブを作成]をクリックします。各種設定は下記の通りです。
- スケジュールを定義する : スケジューラーの概要を設定する
- 名前 : 任意の名前を設定
- リージョン : 任意のリージョンを設定
- 説明 : 何のジョブをスケジュールしているのかを記載。未記入でも問題ない。
- 頻度 : ジョブの頻度を設定。「分、時、日、月、曜日」の順に数値または*(アスタリスク)で記述。詳細はこちら。
- タイムゾーン : ジョブ実行の基準となるタイムゾーンを設定。今回は日本時間(JST)を使用。
- 実行内容を構成する : 実行する際のターゲットを指定する
- ターゲットタイプ : Pub/Sub
- トピック : 先ほどCloud Functions設定時に作成したとぷっくを設定
- メッセージ本文 : Pub/Sub送付されるメッセージを記述。今回の場合は、任意の言葉で問題ない。
- オプションの設定 : 再試行回数などの設定ができる。今回はデフォルトを使用
上記の設定が完了したら、作成をクリックしてジョブが構築されるのを待ちます。ジョブが構築されたら、「…」から強制実行することでジョブのテストができます。

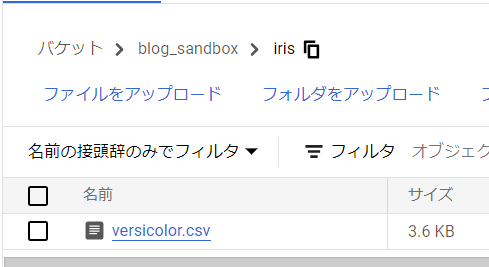
GCSのバケットを見てみると、無事ファイルが転送されていることが確認できました。
さいごに
いかがでしたでしょうか。前回の記事に引き続き、BQ上にあるデータをGCSへ定期的に移行させる方法を紹介してきました。今回紹介した方法は、GCPのいくつかのサービスを組み合わせて構築する必要があるため、少し複雑な部分はあります。ただ、前回紹介したSQLベースでの実装で出来なかった、GCS上のファイル名に余分な名前を付けないでデータ転送することができます。他にも良い方法がありましたら、また紹介していきたいと思います。
前回記事はこちら。
















