
TL;DR
- タイトルだけ読んで「あー分かるわ」と思ってくれる人とは美味しいご飯が食べられる。
- 合格基準点の±1, 2点付近に大量の受験者がいるようなテストは受けたくないですよね?AIとか機械学習の予測結果を信頼できるかどうかも、似たような感じだと思いました。
- 弊社のAutoMLサービス「ForecastFlow」も信頼できるAIを広く世の中にお届けできるように絶賛開発中です。
- 最近のラノベみたいに、記事タイトルや自社製品の名前を長文にするのクセになりそう。
秋田県立大学の地域ビジネス革新プロジェクトのブログ
当該テーマを考えるキッカケは過去にもいくつかあるんですが、今回記事にしようと思ったのは秋田県立大学の教員の方のブログが面白かったからです。
テストの点数の分布はどうなるのが良いのか?(秋田県立大学アグリビジネス学科 地域ビジネス革新プロジェクト)
 ブログ内の画像を引用
ブログ内の画像を引用
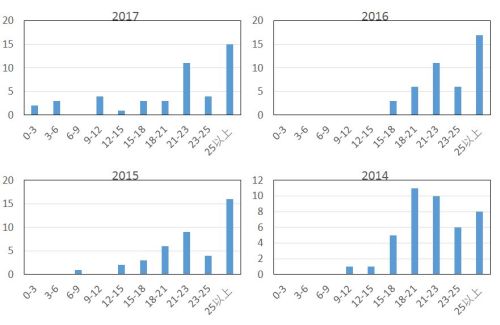
こちらのブログでは、2014年からの4年間のテストの成績の分布を示し、どのように試験問題を設計すればきちんと勉強した人とそうでない人を切り分けられるかの試行錯誤について書かれています。かいつまんで箇条書き(※私見も入る)すると、
- 成績の頻度分布において、点数の高いグループと低いグループの2つが切り分けられるテストが理想的
- 成績の分布が正規分布のようになっちゃうと1点差で泣く人が続出するし、合格基準点を決めるのも難しくなるので、ある程度勉強すれば良い点数がとれるが、何も勉強していないと全然できないという試験問題を考えるのは重要
- 問題を選択形式から部分点ありの記述形式にすることで、2017年の成績分布は狙い通りになってきた
という感じになると思います。(面白そうと思った人、ブログを読んでみてください。)
AIにおけるクラス分類タスクとのアナロジー
上記の試験問題の設計は、機械学習やAIの典型的なタスクであるクラス分類問題の設計と似てる、というか本質的には同じと言っても良いと思います。クラス分類AIの用途としては、例えば、「病気にかかっているか否か」「近い内にサブスクを解約するか否か」などを予測するなどが分かりやすいです。
AIは過去のデータを学習して予測するものと言われますが、もう少し詳細に書くと、
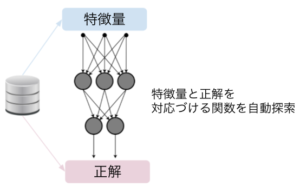
- 人間が過去のデータから特徴量と正解クラスという2つのパートから構成されるデータ・セットを準備
- AIはその特徴量と正解クラスを結びつけるためのパターンを学習
という感じになります。ちなみに特徴量とは、例えば性別や年齢、過去の既往歴や問い合わせ回数などのそのヒト・モノを特徴づけるデータのことです。
学習済みのAIモデルの生の出力は、それぞれのクラスに分類される「確率」になります。先の例でいえば、「病気の確率」とか「解約する確率」となる訳ですね。用途によってはこの確率値だけあればOKということもあるでしょうが、予測結果としては結局どっちなのか教えてほしいというケースも多くあります。後者の場合には、どちらのクラスに分類させるかの確率の閾値を決めてあげる必要があります。
クラス分類モデルの性能評価指標として最も良く使われるのはF1というものです。(ここでは何かは言及しません。ググってください。)なので、F1を最大化するように閾値を調整するのが一般的で、弊社のAutoML「ForecastFlow」でも同じ考え方で調整しています。
 ForecastFlowクラス分類モデルのサマリー画面
ForecastFlowクラス分類モデルのサマリー画面
AIプロジェクトのPoCフェーズなどでも、F1などでモデルの精度を報告する場合も多々あります。分かりやすい反面、それだけ見ていてもモデルの信頼性や頑健性までは分かりません。信頼性に関する情報を抜き取るための1つの方法は、モデルの出力する確率の頻度分布をプロットしてみることです。
たとえば、確率の頻度分布として次のような2パターンのモデルがあったとするなら、あなたはどちらのモデルをより信頼しますか?
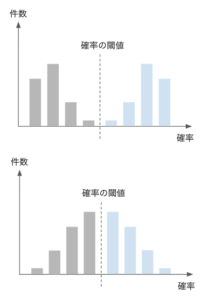
上下どちらの分布も閾値を中心にして左右対称なので、F1精度としては全く同じになります。しかし、下の分布をもつモデルはちょっとした入力データの誤差によって分類結果が異なるケースが多発することが考えられるので、現場での実運用は難しそうなのが分かると思います。
現在、ForecastFlowではこのようなモデルの頑健性や信頼性に関する情報を簡単にご覧頂くための画面を絶賛開発中で、2022年の初頭ころにはローンチできるかと思います。
AIモデルのキモはデータの質と特徴量設計
理想的なテストの成績分布と頑健性の高い機械学習モデルの確率分布には似た特徴があることが分かりました。テストでは理想形に近づけるために、問題の難易度や質、記述方法などを工夫されていました。その点もAIモデルの場合と全く同じで、予測したいことになるべく直結するデータの収集とその加工における創意工夫が最も重要で、このような背景から、AIはドメイン知識が重要だからビジネスが分かる人を巻き込めとか、特徴量の設計ができるデータエンジニア人材の確保や育成が重要と言われています。
ちなみに、ForecastFlowなどでも利用できる良い特徴量設計の一例として以下の記事をご紹介します。
決定木系アルゴリズムはなぜ特徴量同士の四則演算を明示的に入れる必要があるか(実験編)
決定木系アルゴリズムはいかにして特徴量空間に「斜めの線」を引くか
さいごに
AIと言われると難しいイメージを受けてなかなか実感が湧かない人もいるかもと思うので、なるべく身近な例で説明できると多少は距離感が縮まるかもと思い、この記事では理想的なテストとのアナロジーから、AIでの重要ポイントを説明しました。結局のところは良く分からんけど、AIでやりやいことが少し分かったという方が一人でもいれば目標達成です。














