
皆さんは、「このダンスを踊りたい!」と思ったとき、どのように習得しているでしょうか。
私は一昨年のハロウィンの時期、友人と USJ に行った際に上記のダンスを身につける必要に駆られました。夜になると急にゾンビたちが現れてこの Rat-tat-tat ダンスを踊り始め(全員キレッキレなのがまたシュールでした)、来場者も一緒に踊るというイベントでした。
楽しい雰囲気で盛り上がりましたが、ダンスを見様見真似で踊るのは私にはなかなか難しく、上手く踊れる人を羨ましく感じたものでした。
私が今回試したものは、動画からそこに写っている人間のポーズを推定する AI 技術です。
ミュージックビデオと自分自身それぞれから体の各部位の座標を得られれば、自分の動きが正解とどの程度異なっているかを把握できます。
これが実現すれば、私を含むダンスが上手く踊れない人への一助となるかもしれません。
利用したツール
今回の推定には、上記の機械学習を用いた三次元ポーズ推定のデモ機能と、あらかじめ用意されている学習済みモデルを用いました。
[1704.02447] Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach の論文を Python で実装したものであり、屋外背景の 1 枚の画像から三次元で人体の各位置を推定するモデルです。
リポジトリと、説明にある学習済みモデルをそのまま引っ張ってきて、必要なライブラリをインストールすれば実行できます。学習済みモデルを利用するため GPU も不要です。
用意されていたデモ画像に対する実行結果はこのようになります。


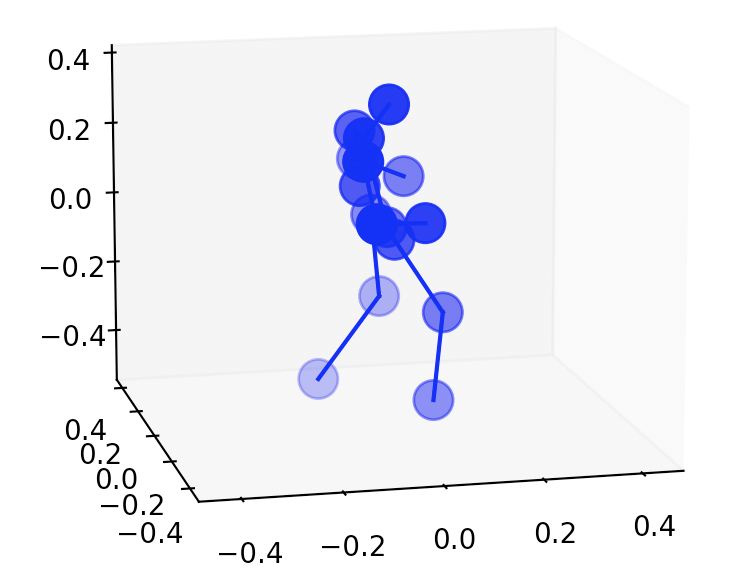
一番右の三次元推定の結果は、マウスでグリグリして視点を動かすこともできます。
ミュージックビデオへの適用
最初の動画に実装していきます。
このデモは 1 枚の画像にしか適用できないため、動画をコマごとの各画像に切り取って処理していく必要がありました。すなわち、
動画 → コマ送り画像 → 各画像で推定
の流れで処理していくことになります。
今回はミュージックビデオの短い一部分を使用したためコマの 1 枚ずつに適用していきましたが、流れ全体の自動化もそこまで難しくなさそうなので今後実装していきたいところです。
最初にあげた動画の 1:05 頃の “Hands down!” している部分に適用した結果がこちらです。
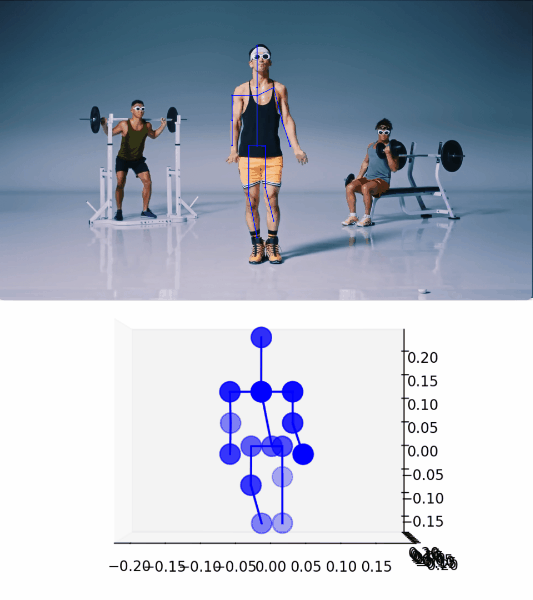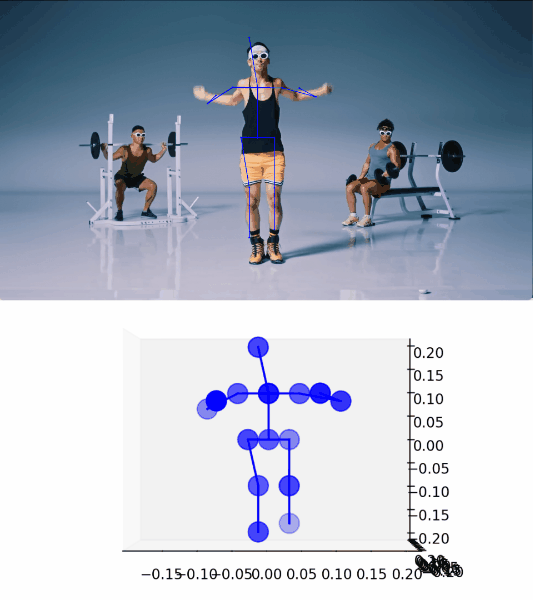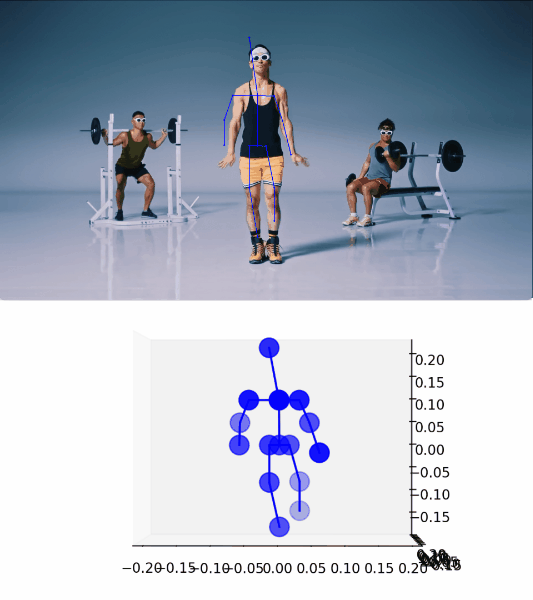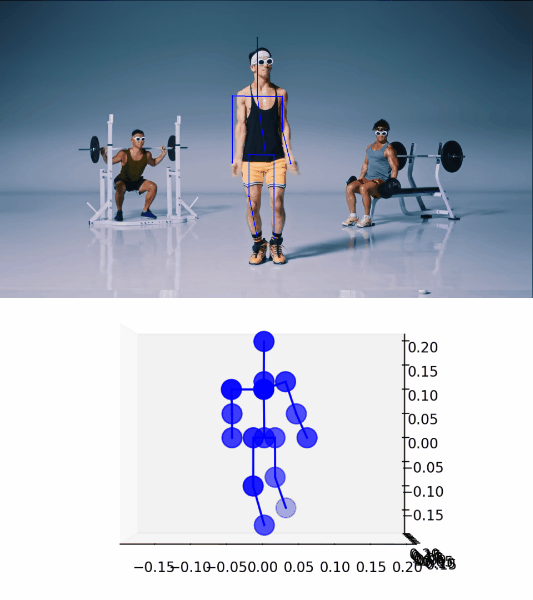
ポーズを精度良く検出できていることがわかります。
今後の課題・方針
今回のモデルでは 1 人の人間しか検出できないため、複数人を同時に推定するには
各コマで人物検出 → 人ごとにトリミング → それぞれでポーズ推定
という処理を行う必要がありそうです。
また、上半身のみなど、全身が映ってない画像に対しては検出がうまくいっていないことが多く、そのようなデータも含めた学習も必要になるかもしれません。
以上の点が解決されれば、ミュージックビデオおよびそれを真似て踊る人のポーズを推定することで、ダンスを効率的に学び、習得することが可能になると考えられます。
このような身の回りにある課題を、AI や分析の技術と結びつける楽しさも弊社で働く魅力の 1 つです。
分析官 K. K













