
近年VRなどで必要不可欠となる複数の視点の画像から新たな視点画像を生成するタスク「Novel View Synthesis」が注目されています。このタスクで驚異的な精度を誇り着目された手法が「NeRF」と呼ばれるものです。「NeRF」は機械学習により画像を生成するAIモデルです。
今日は、複数視点から画像生成するAIモデル「NeRF」を紹介しようと思います。
1. NeRFの概要
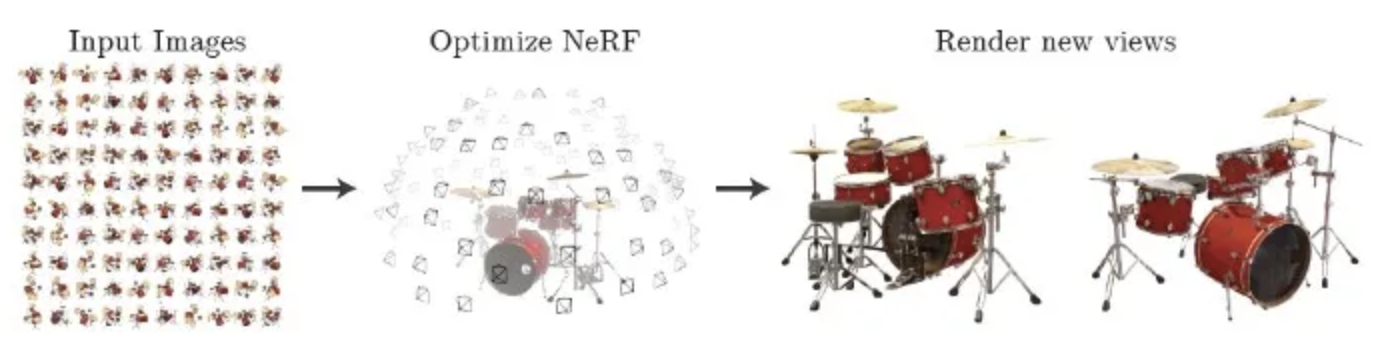
「NeRF」はGoogleの研究部門であるGoogle Research及び、米カリフォルニア大学によって研究開発された、さまざまな角度から撮影した画像を機械学習により自由な視点から見られる画像を生成する技術です。

上の画像はレゴのブルドーザーを4視点からそれぞれ生成し、別視点から見ることができます。この技術を用いて生成した画像は視点を変えても、その視点に合わせた新しい画像が連続的に生成されます。そのため、立体感を保ったまま閲覧が可能になります。
2. NeRFの技術的側面
「NeRF」はニューラルネットワークの一種であるMultilayer perceptronで学習されています。このモデルの最大の特徴は、一般的な画像生成モデルで広く使用されるCNN(Convolutional Neural Network)が使われていないことにあります。このモデルではCNNを使用せずともそれ以上の高精度な結果を出力できます。
「NeRF」ではニューラルネットワークで表面と体積の表現をエンコードする機能があります。
これにより、「NeRF」では他の視点からの画像を予測しレンダリングすることが可能になりました。
モデルは、画像の各点の位置(複数視点の3次元座標)と見る角度(2次元の視線方向)から対象物の密度と色を予測します。その後画像を合成します。合成された画像は光の反射も考慮しているため、見る視点を変更すると同時に反射具合も変わり、写実的な状態を表現することができます。
3. おわりに
VRなどの3Dレンダリングに使われる画像生成モデルの「NeRF」について紹介しました。
CNNを使わずに画像生成することが従来のモデルとの大きな違いですね。
近日では、新たにGoogleが超リアルな画像生成モデルとして「Parti」を報告しました。
自己回帰によるテキストから画像への変換が行われるモデルで、パラメーターが最大200億個に達するまでクオリティは向上するのことです。
情報が出次第また調査したいですね。















