
画像処理におけるヒトと機械の違い
画像処理とは、画像データの性質(形状、色、サイズ、方向など)を加工し、特性を読み取り、映っている対象物を識別するための技術全般を指しています。
画像を連続的に、高速に処理すると動画の処理に繋がります。
画像処理の代表的なタスクは物体認識です。以下の2つのタスクから成り立ちます。
- 物体の位置を特定(物体検出またはセメンティックセグメンテーションを使用)
- 画像分類を行う
②の画像分類とは、画像データから特徴量を抽出し、画像に写っている対象物のカテゴリを推定することです。
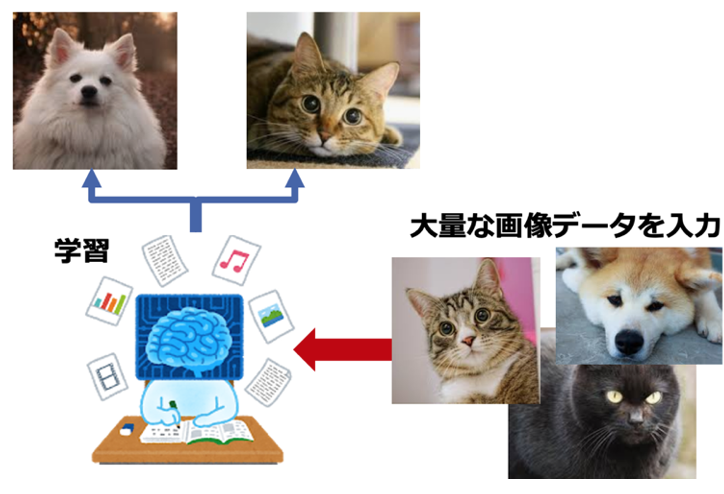
今では、ニューラルネットワーク(ディープラーニングの元となるアルゴリズム)を画像分類に活用することが主流になっています。他の機械学習の手法とは異なり、ニューラルネットワークは、画像データから特徴量を自動的に抽出できるためです。下図のように、ニューラルネットワークに画像データを大量に投入すると、効果的な特徴量を見出し、これらの特徴量に基づいてモデルの学習が行われます。
もっと具体的に、機械で画像分類をどのように行なっているのかを考えましょう。
私たちは、ヒト特有の「経験」と「理解力」と「思考力」を駆使し、物体を1度見ただけでそれを覚え、次回同じ物体を見た時には同じものだと認識できるようになります。これに対して、コンピュータ(機械)に画像認識をさせる場合は、画像データの中の色合いを表す画素(ピクセル)の並ぶパターンを認識し、そのパターンを特徴量として画像認識モデルが訓練されます(下図)。

2015年頃には、機械学習(ディレクティング)による画像認識の精度は人間による認識精度を超えたと言われています。精度だけではなく、処理の高速化も重要です。アルゴリズムやGPUの改良により、大量のデータ処理が短時間で出来るようになりました。
身近の画像認識の活用例
こうして、人間にしかできない「ものを見て認識する」ことが今では、人間の眼と脳の処理能力をある程度まで模倣したAIの技術によって実現されています。物体認識、顔認識、文字認識など、日常の色々な場面でもその技術が応用され、人に代わり判定・測定が可能になっています。身近な事例を幾つか見てみましょう。
■顔認識
画像に映る顔を識別して個人を特定する顔認識は、スマートフォンやセキュリティ・ゲート、防犯カメラなどで使われています。最新の顔認識技術は、対象人物が意図的に髪型を変えたりメガネをかけたり、マスクをつけたときでさえ、個人を識別可能になっています。近年では、静止画ではなく、動いている映像から、挙動不審な人物を特定できる技術が開発されています。
■製造業の現場における品質管理
製造業の分野では、画像認識による品質検査が自動的に行われると、人手不足が解消され、かつ小さな「かすり傷」も逃さないため、検品と品質管理の精度が上がります。
■スマート農業
画像処理技術を農業に活用した「スマート農業」はここ数年ブームを迎えています。
作物の収穫時期や品質仕分けの判断に活用されることが多いです。これらは従来では経験に頼る要素が多く、業務の一部をAIで代用することが、農業の高齢化問題へのアプローチでもあります。AIモデルが考慮する情報は「色」だけではなく、葉っぱの萎れ具合、茎の様子など複数の変数を加味して判断をします。
参考:
AIの判断に基づく高糖度トマトの生産:https://www.shizuoka.ac.jp/news/detail.html?CN=6180
農家がグーグルのAIエンジン「Tensor Flow」でキュウリの自動選果を実現
画像データの構成と性質
身の回りのどこででも見る「画像」ですが、機械学習ではどの部分に着目しているのか、皆さんは想像できますか?
画像データの1枚1枚は配列
画像は画素(ピクセル)を最小単位としています。画像の上に、画素が格子状に並んでおり、それぞれの画素が何らかの数値を持っています。コンピュータは格子状に並んだ画素を配列情報として扱い、画素にある数値を特徴量として機械学習モデルの学習に用います。
例えば、畳み込みニューラルネットワーク(CNN)の畳み込み層では、元の画像に対してフィルター(これも2次元配列)を掛けて、行列演算を行うことで凝縮した特徴を取り出します。
画像の色をどう表現するのか
画像を配列として考える際に、配列の次元はカラー画像とグレースケール画像では異なります。両者で大きく違うのは、色次元のチャネル数です。
画像は基本的に、縦 × 横 × 色(または輝度)の3次元です。カラー画像の1つのピクセル(画素)の色を表現するのに、{Red(R)、Green(G)、Blue(B)}の3種類の値(3つのチャネル)が必要です。RGBカラー画像はこの3つの色の強さを組み合わせて表現された画像です。これに対して、グレースケール画像の場合は、1つのピクセルあたりに輝度(明るさ)を表す単一の値のみ割り当てられます。
R, G, Bのそれぞれは256階調となっており、そのためカラー画像の情報量は8bitx3 = 24bitです。グレースケール画像は輝度のみなので8bitです。256階調というのは0~255の間の濃度の値をとる、という意味です。
三原色のそれぞれの濃度を調整することによってあらゆる色味を表現することができます。例えば黒は(R,G,B)=(0,0,0)、白は(255,255,255)です。紫っぽい色はRとBの成分が大きく、(200,30,200)のような組み合わせが考えられます。
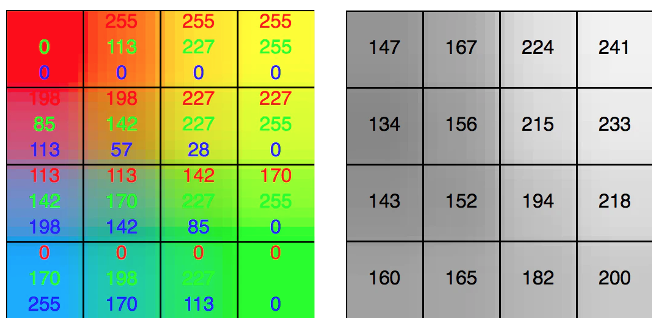
ちなみに、「グレースケール画像」と「モノクロ画像」(白黒画像)は言葉が似ているが、異なるものです!モノクロ画像は各画素の色が白と黒の2色のみで表現された「バイナリー画像」です。これに対してグレースケール画像はあらゆる輝度の値をとることができます。白と黒とその中間の幅広い濃淡のグレーを含みます。
執筆担当:ヤン ジャクリン (分析官・講師)














