
突然ですが、「チョコレートの消費量」が多い国は「ノーベル賞受賞者」が多いことはご存知でしょうか。
素晴らしい発見、「チョコレートをたくさん食べる」と「ノーベル賞がとれちゃう」……
そんな甘い話はありません
事実、「チョコレートの消費量」が多い国は「ノーベル賞受賞者」が多いです。
これは、一方の数が多いともう一方の数も多い相関の関係です。「チョコレートの消費量」が多いと「ノーベル賞受賞者」が多い、「ノーベル賞受賞者」が多い国は「チョコレートの消費量」も多いといったような双方向の関係です。
一方で、「チョコレートをたくさん食べる」と「ノーベル賞とれちゃう」という表現は、因果の関係を表すことになります。一方の変化に伴ってもう一方の値が変化する、逆方向では同じことを表さなくなる単方向の関係です。
相関が分かると、ある2つの変量の関係性はわかりますが、何かアクションを起こしたときに起こる変化まではわからないのです。因果なら伴う変化なので、そこまでわかります。
相関だけじゃ物足りない、因果まで知りたくなってきました。
そこで今回は、因果探索手法LiNGAMを実際に動かしてみたいと思います。
「因果探索って何よ」という方は、以下の記事で少し説明しておりますので参照いただければと思います。

Linear Non-Gaussian Acyclic Model
LiNGAMは、Linear Non-Gaussian Acyclic Modelの略です。重要な特徴として以下が挙げられます。
- Linear → 線形
変数の関係は線形で表される - Non-Gaissian → 非ガウス分布
誤差の分布がガウス分布に当てはまらない - Acyclic → 非巡回
因果をたどった時に、自身には戻ってこない
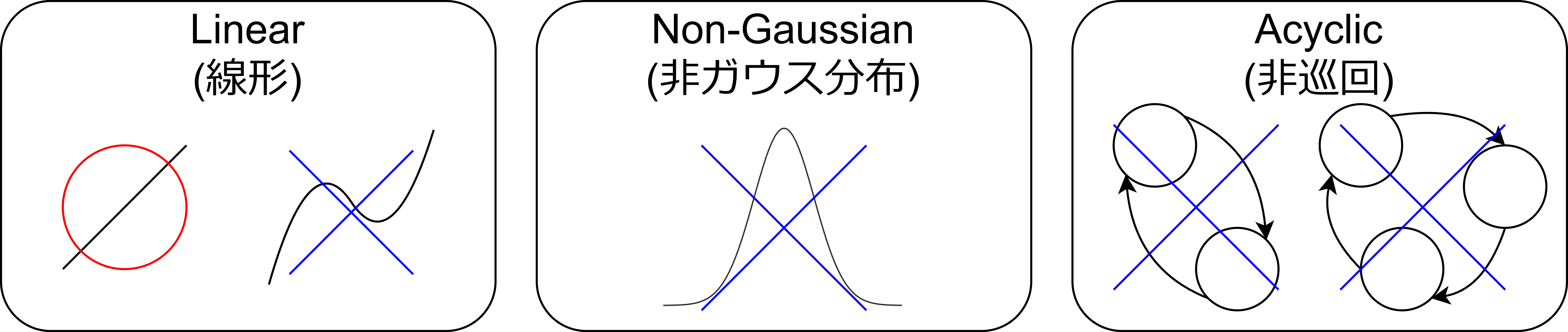
これらの制約は、因果という複雑な事象に対して少しでも楽にアプローチするためのものです。高校物理で空気抵抗を無視するのと同じです。
ここでは、理論の説明は割愛します。私が参考にした書籍『統計的因果探索』などを参照していただけると幸いです。
必要な準備
LiNGAMはPythonにライブラリが存在しますので、そちらを用います。
pip install lingamで利用可能になります。環境構築後に実行しておいてください。
環境は、WindowsのローカルでAnacondaを用いて構築しました。
バージョンは以下の通り。
- python:3.11.5
- numpy:1.26.3
- pandas:2.1.4
- graphviz:0.20.1
疑似データ投げてみた
早速、LiNGAMを試してみます。
import pandas as pd
import numpy as np
import lingam
疑似データとして、以下のような関係を持つ変数群を用意しました。この変数群の関係はLiNGAMの特徴である線形、非ガウス分布、非巡回を満たしているものになります。
sample = 3000
def gamma_rand(sample_size):
return np.random.gamma(shape=np.random.random()*4,
scale=np.random.random()*4,
size=sample_size)
a4 = gamma_rand(sample)
a6 = 3*a4 + gamma_rand(sample)
a1 = 3*a4 + gamma_rand(sample)
a5 = -2*a4 + gamma_rand(sample)
a3 = 2*a6 + 3*a1 + gamma_rand(sample)
a2 = -1*a6 + 4*a5 + gamma_rand(sample)
a0 = -3*a5 + gamma_rand(sample)
a7 = -4*a3 + 5*a0 + gamma_rand(sample)
関係を図で表すとこんな感じ。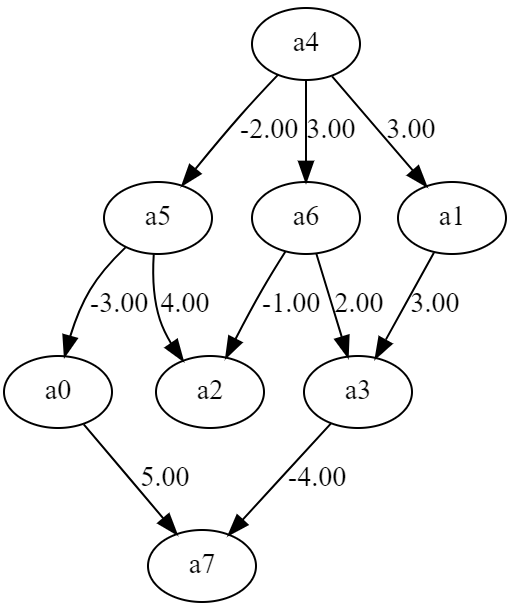
では、この関数群にLiNGAMを適用します。
labels = ['a0', 'a1', 'a2', 'a3', 'a4', 'a5', 'a6', 'a7']
df = pd.DataFrame(np.array([a0, a1, a2, a3, a4, a5, a6, a7]).T, columns=labels)
model = lingam.DirectLiNGAM()
model.fit(df)
#図の出力用
# dot = lingam.utils.make_dot(model.adjacency_matrix_, labels=labels)
# dot
出力を図示するとこんな感じ。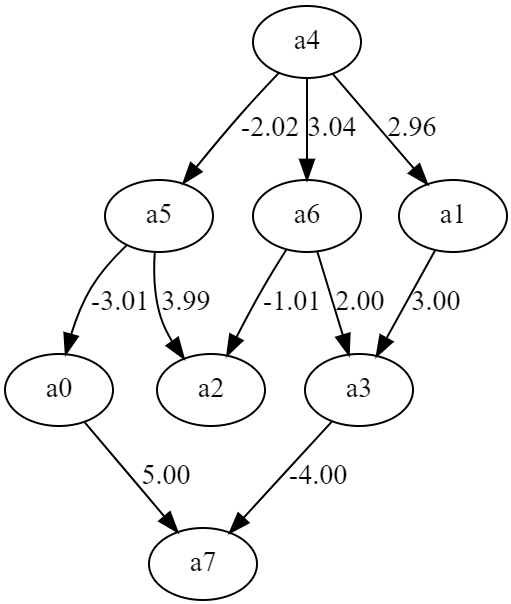
見比べると、かなり高い精度で因果関係を推測できていることが分かります。
この図はサンプル数3000ですが、1000程度だと予測結果は安定してませんでしたね。
ここまで
ここまで、疑似データに対して因果探索手法LiNGAMを使ってきました。
後編では、実データに対してLiNGAMを適用したいと思います。
後編はこちら
















