【はじめに】
日頃データサイエンスの研修においては、教師あり機械学習から入門し、それをビジネスの花形として紹介することが多いです。ただし世の中の問題に向き合うと実に教師なし機械学習の存在が大きいのも知っていただきたいです。その1つが異常検知です。
異常検知は異常値や外れ値を検出する手法を指しています。金融の不正取引識別、故障検知・故障予測、検品、設備管理、医療、セキュリティなど多岐にわたる分野で貢献しています。この記事では、異常検知の使いやすいかつ有力な教師なし学習手法の1つであるIsolation Forest手法を説明し、それを用いて不正侵入パケットに対する予測モデルの構築の例を示していきます。
演習に使用するデータ
インターネットの普及により,悪意のあるソフトウェア(マルウエア; Malicious Software)による攻撃が問題として現れています。コンピュータが感染すると、使えなくなったり、機密情報が流出したりします。全種類の攻撃から守ことは難しいですが、現在、攻撃に対抗するシステムが色々開発されております。大きく分けて、攻撃検知型 ( IDS=Intrusion Detection System)と検知後に脅威を排除する攻撃防御型 ( IPS=Intrusion Prevention System)の2タイプがあります。アクセスデータに対する分析手法も2タイプあります。攻撃パターンを把握し合致した通信データを得た場合に攻撃と判断する「シグネチャ型」、もう1つは正常通信のパターンを定義し、そこから性質が離れている通信データを攻撃と判断する「アノマリ型」があります。
IDS や IPS の研究で扱われる代表的なデータセットとしてKDD CUP 99 Data Set があります。UCI Machine Learning Repository から入手できます:http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
約 500 万件(4,898,930) のフルセットから 10%を抽出した約 50 万件(494,021)の 10%データセットを今回、異常検知タスクの題材とします。自分で精度を評価したかったので、学習用データセットのみ使用します。
学習用データの、”label” 列に正常通信(normal)と22 種類の攻撃が含まれています。normalから不正を識別するためには、もちろん様々な機械学習の手法を使用できます(SVM、教師ありアンサンブル、ディープラーニング、K-Meansなどの距離ベース)が、今回はIsolation Forest を使った分析例を紹介します。
【Isolation Forestについて】
分析手法の仕組み
Isolation forestは異常検知に特化して設計された教師なし学習の手法です。異常データを「孤立させる(isolate)」ことにより認識します。
馴染みの深いRandom Forestと同様に、Isolation Forest もアンサンブル学習器です。データ(行)と特徴量(列)をサンプリングして個別の木々(Isolation Trees) を作り、組み合わせることでロバストさを図ります。
簡単にIsolation Forest のデータ処理の流れを説明します。特徴量の中から1変数を選び出し、初期的にその変数の(最小値, 最大値)区間で「分割点」をランダムに選びます。最終的には、上記の分割点が節、データ点が葉である木構造になります。この分割操作を、満足の基準になるまで再帰的に分割を繰り返します。
各データ点に対して、葉にたどり着くまでの分割数はルートノードから葉までの距離に対応します。この距離(path length) path length という概念が重要です。なぜなら、 Isolation Forest アルゴリズムは「異常値は量が少ない、かつ 正常データと性質がかけ離れている」という仮定に基づいています。異常データは、早い(木の浅い)段階で分割される確率が高く、結果としてpath length が小さくなります。この傾向を利用して異常データを正常データから見分けます(*)。
個別の木々を組み合わせる時、各データ点に対して、path lengthを森全体でとった平均を最終判断として採用します。この平均深さがまさに異常スコアに対応します。
(*)を直感的に理解するための例として、会社員の1ヶ月の給料のは概ね30万を中心に分布していますが、たまたま給料1000万のデータがあると、そのデータの区間は(30くらい, 1000)になります。この区間で分割する値をランダムに決める(一様分布とする)と、1000万のデータ点がisolateされる確率は圧倒的に高いですよね。
Isolation Forestの利点
異常検知の手法は他にも色々あります。その多くは「正常データ」のプロファイルを作り、それと比較して「遠い」ものを異常と判定します。この距離の概念は特徴量空間で形成されます。Isolation Forestは違います。「正常」の定義をしない、データ間の距離を計算に使わない、が差別化ポイントです。そのようなIsolation Forest のメリットとしては以下が挙げられます:
- 高速に異常値を検出可能(理由:他のdistance-based手法と違って正常データのプロファイル作成不要のため、計算コストが比較的少ない)
- メモリ占有率が比較的少ない(↑と似た理由)
- 木が発達する深さを表すパラメータ max_depth を小さく設定できる(理由:異常データは短いパスのうちに既に識別できるから)
- 小さなデータセットでも不利益が少ない
- 不均衡データにも使いやすい (**)
(**)の補助説明:一般的に、正常データと異常データの間の不均衡問題が難しいです。不均衡をなくすために、データに重み付けをする方法とデータ数を調整する方法があります。後者では少ない方のデータを増やすオーバーサンプリングと多い方を減らすアンダーサンプリングがあります。一方で、Isolation Forest は不均衡問題にさほど敏感ではなくなるような設計なので、データ前処理の工数も削減できます。
【不正パケット検出のデモ】
演習を見せながら残りの解説をします。(本質ではないコードの部分を省略)
データの読み込み・概観
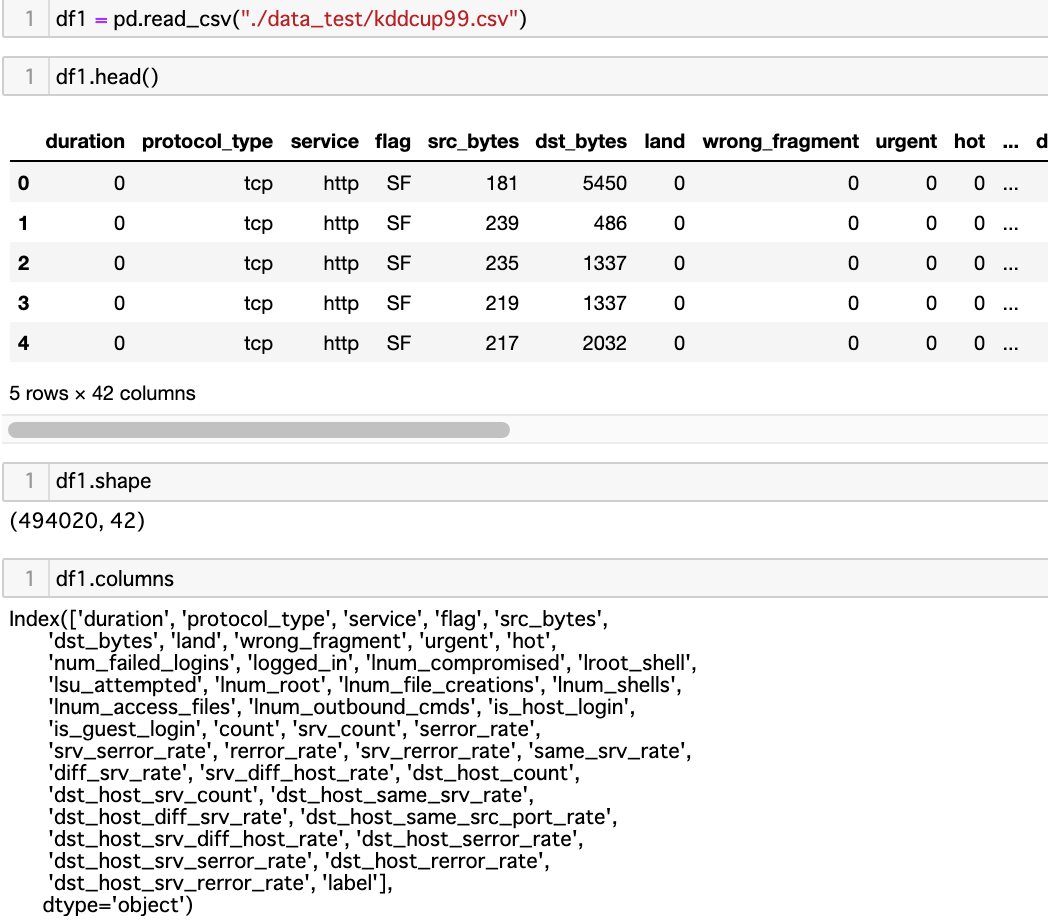
正常、不正常データの割合を観察
今回はサービスの種類を http (よくあるもの)に限定した分析としました。
文字列データのlabel encoding を行いました。
データを学習用と検証用に分割
Isolation Forestは教師あり学習ではないのですが、訓練データと評価データがあります。訓練データにもラベルがついている必要はありません。訓練データを用いて、Isolation Forestを学習させます。評価データでは、データを森に入れて、各データ点に対して異常スコアを取得します。
- 入力:データ
- 出力:各データ点の異常スコア

モデルの定義・パラメータ設定・学習
Isolation Forest で重要となるパラメータは以下です。
- n_estimators :アンサンブル内の木の数。デフォルトは100です。ここで500。
- max samples:: それぞれの木を作るためにランダムサンプリングされるデータ数。 ‘auto’ にしている場合 max_samples=min(256, n_samples)
- contamination: 最も敏感に反応するパラメータの1つであり、その初期設定に要注意です。データせっとの中の期待される異常値の割合です。これはスコアの算出や判定閾値を出すときにも重要です。ここでは1割とする。

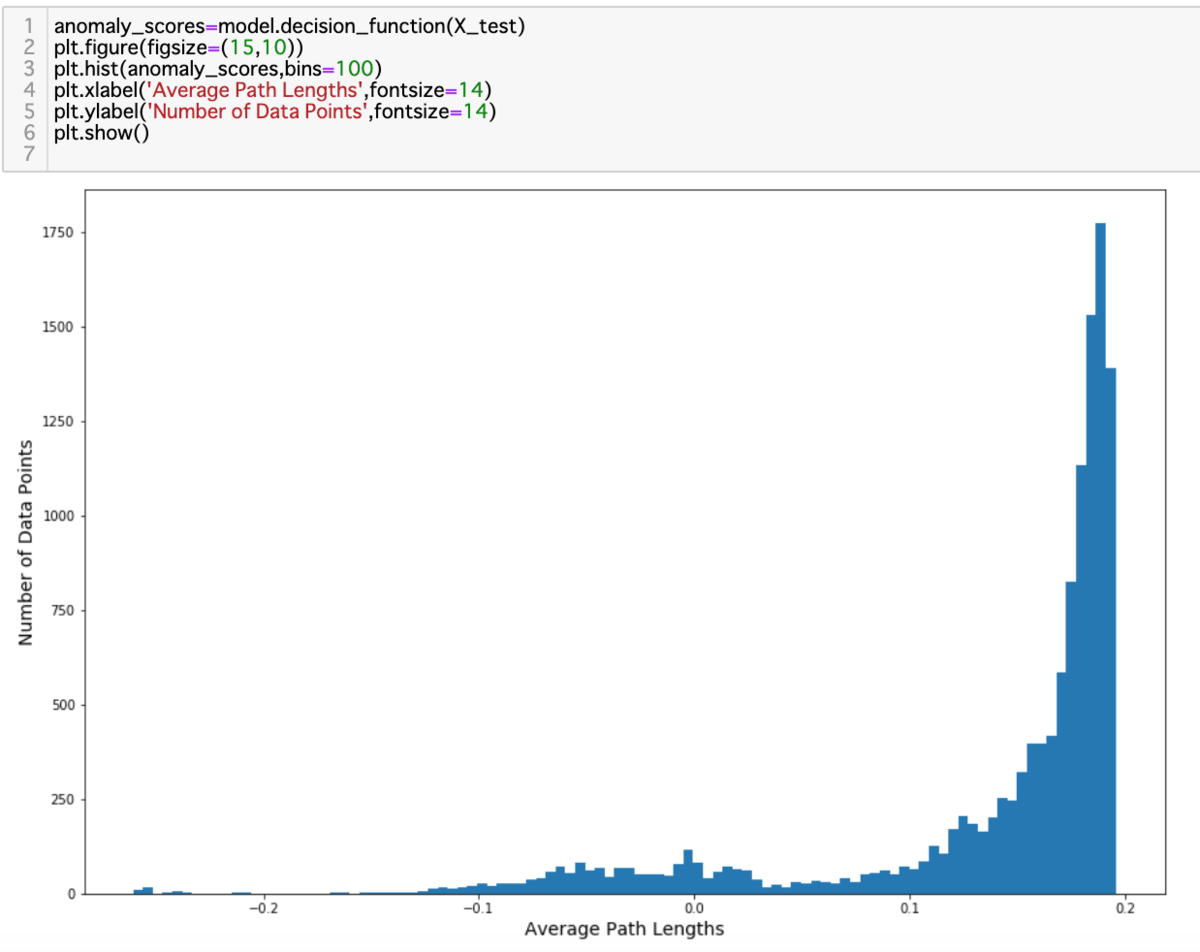
異常スコアの算出・可視化
検証用と呼ばれている部分のデータに学習済みモデルを当てて、異常スコアを算出します。棒グラフで視覚化すると、異常判定の閾値が見えてきます。
精度算出
図5において、スコアに対する閾値を0.19と決めました。
検証用データには正解がついており、それを用いて評価したAUCスコアは98.2でした。
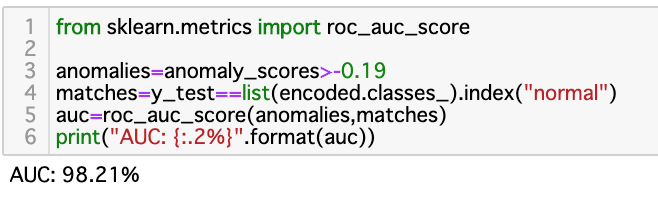
ちなみに、同じ課題を、アップまたはダウンサンプリングを行わずでKMeansで対応したところ、精度は85%程度でした。これだけの少ない工数でIsolation Forest手法を用いて、リアル世界の問題に対処できたのは素晴らしいと思います。
課題
今回は一発だけIsolation Forest の使い方を試しましたが、現実には精度を保証するために注意が必要です。例えば ….
- 個別の攻撃を用いた場合、攻撃の種類、正常通信と攻撃通信の割合など学習データのバリエーションを増やした上での精度も評価すべき
- 学習データにはない種類の攻撃が検証データにあったら精度はどうなるのか?
今度は、教師あり手法(random forest, SVM)やきちんと不均衡問題を解消するための前処理を施した上での kMeansの結果ときちんと比較したいと思います。
担当: ヤン・ジャクリン(分析官・講師)
参考
Scikit-learnのドキュメント
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html
https://scikit-learn.org/stable/auto_examples/ensemble/plot_isolation_forest.html
論文
Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008, December). Isolation forest. In 2008 Eighth IEEE International Conference on Data Mining (pp. 413-422). IEEE.















