
この記事は 「PyCaret を用いて様々な機械学習手法の比較を一瞬で行う」の続きです。
この記事でやること
- 前回記事(PyCaret を用いて様々な機械学習手法の比較を一瞬で行う)の振り返りをします
- PyCaret の setup() 実行時にパラメータとして指定できるカスタマイズ方法について、主要なものを説明します
- PyCaret の compare_models() 実行時にパラメータとして指定できるカスタマイズ方法について、主要なものを説明します
前回の振り返り
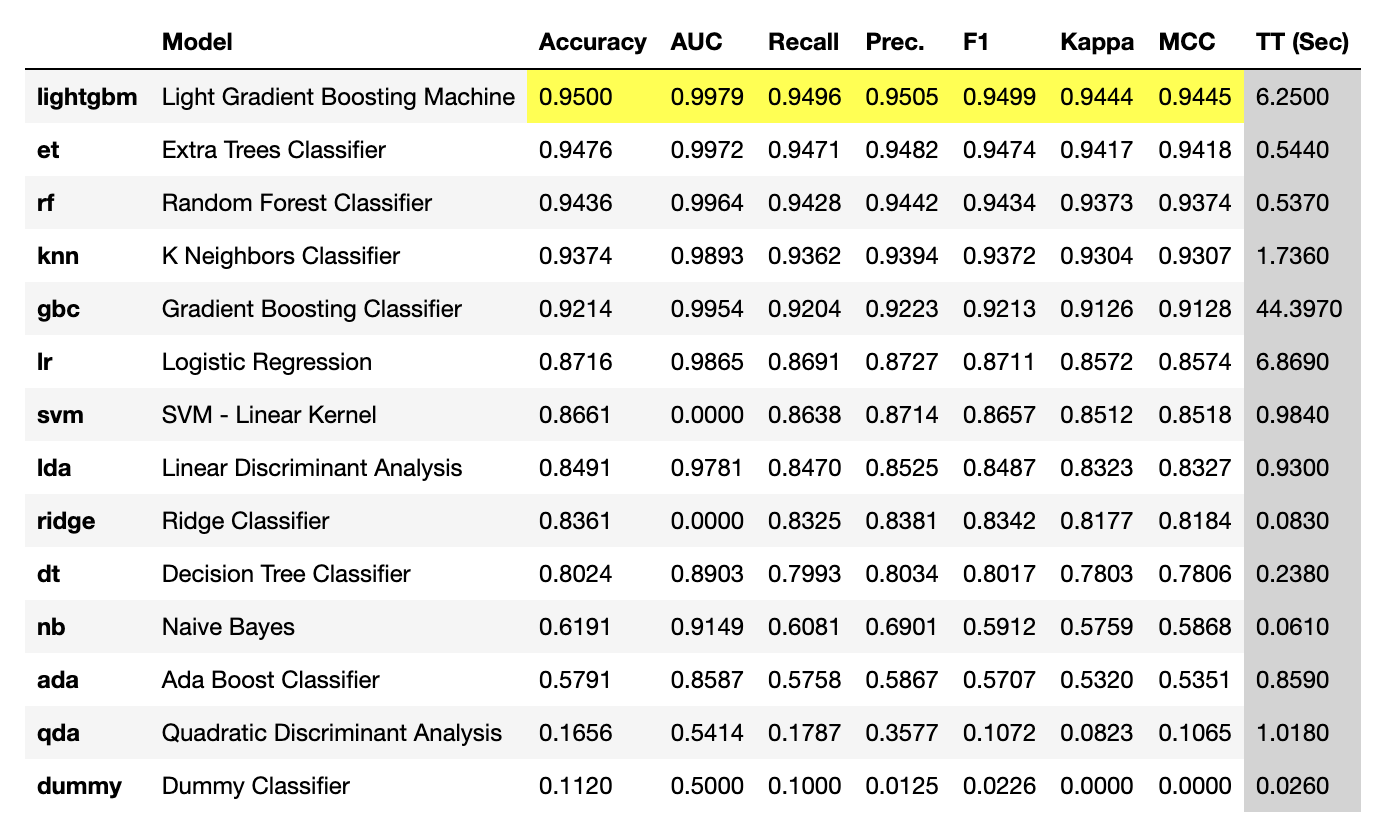
PyCaret での精度比較は、対象のデータセット df を用意することで、以下の記述をするだけでできるのでした。
from pycaret.classification import *
setup(data = df, target = "Target")
best_model = compare_models()
比較結果
以下では、setup() と compare_models() で記述できる引数を元にカスタマイズ方法を説明していきます。
setup() でのカスタマイズ
setup() では主に学習のためのデータの指定と前処理についてのパラメータを記述できます。
参照元: https://pycaret.readthedocs.io/en/latest/api/classification.html#pycaret.classification.setup
data
上記例でも指定されている、学習元となるデータです。ListやDictでの入力もできますが、pandasのDataFrameで与えるのが一番簡単です
target
上記例でも指定されている、学習するターゲットの指定です。例ではdata内のターゲット列を指定していましたが、何も指定しなければ自動的に最後の列を選びます。また、ListやpandasのDataSeriesで、data内にないターゲットを外挿することも可能です。
train_size
dataにおける学習データの割合を小数で指定します。train_size=0.8とすれば学習データとテストデータが8:2の比で分割されます。例のように何も指定しないと 0.7 となります。data内からの分割ではなく外挿する場合はtest_dataのパラメータを使います
test_data
テストデータを学習データと別で用意している場合は、このパラメータで指定することで外挿することができます。これを使うときはdata_split_shuffleをFalseに設定する必要があります。
data_split_shuffle
データ分割時にシャッフルを行うかを指定します。デフォルトではTrueでシャッフルが行われます。test_dataを外挿した場合でもTrueのままだと学習データと混ぜられてしまうので(バグ?)、外挿時はFalseにする必要があります。
data_split_stratify
データ分割時にターゲットのラベルの比を維持するかを指定します。デフォルトではFalseで、指定しなくても大体は同じになりますが、Trueにすることで分割前と全く同じ比にできます。
remove_multicollinearity
他の特徴量と相関の高い特徴量を自動で除きます。デフォルトではFalseです。multicollinearity_thresholdで閾値を指定することもできます。
remove_outliers
外れ値を自動で除きます。デフォルトではFalseです。outliers_method, outliers_thresholdで詳細を指定することもできます。
normalize
データの正規化を行います。デフォルトではFalseです。normalize_methodで詳細を指定することもできます。
pca
PCA(主成分分析)による次元削減を行います。デフォルトではFalseです。pca_method, pca_componentsで詳細を指定することもできます。
compare_models() でのカスタマイズ
compare_models() ではモデル比較時のパラメータを記述できます。
参照元: https://pycaret.readthedocs.io/en/latest/api/classification.html#pycaret.classification.compare_models
include, exclude
比較対象に含めるモデルをincludeにListで指定します。あるいは含めないモデルをexcludeにListで指定します。
turbo
デフォルトのTrueでは学習に時間のかかるモデル(MLP, Gaussian Process等)を除き、処理の短縮を図っています。Falseにすることでそれらのモデルも使用されます。
















