
前編では、以下のAAAI-21の最優秀論文の概要と研究の背景を解説しました。

Mitigating Political Bias in Language Models Through Reinforced Calibration
筆者和訳:強化学習を用いた、言語モデルにおける政治的バイアスの軽減
論文リンク:https://arxiv.org/pdf/2104.14795.pdf
今回(後編)では本研究で開発・活用された技術の詳細、そして最後に本記事の執筆者の感想を述べます。
政治的バイアスを除去する仕組み
本研究では、GPT-2によって生成された文章の政治的バイアスを、強化学習フレームワークを用いて、文章生成の過程の中で軽減しています。
※強化学習の理論が関与するため、論文の数式の解説を本レポートで割愛させていただきます。
簡単に強化学習を解説
強化学習とは、ある特定の状態下で、最大限の「ご褒美(報酬)」をもらうために、どのような行動をとるべきかを学習するための機械学習手法です。教師ラベルがなくても学習できるのが1つの特徴です。強化学習の「主体」であるエージェントは「環境」が与えた「状態」の中で「行動」の試行錯誤を繰り返しながら意思決定ルールを見出します。「行動がどの程度よかったか」を示す指標として「報酬」が環境から与えられます。最終的に最大の報酬をもらえるような行動ルールを学習します。
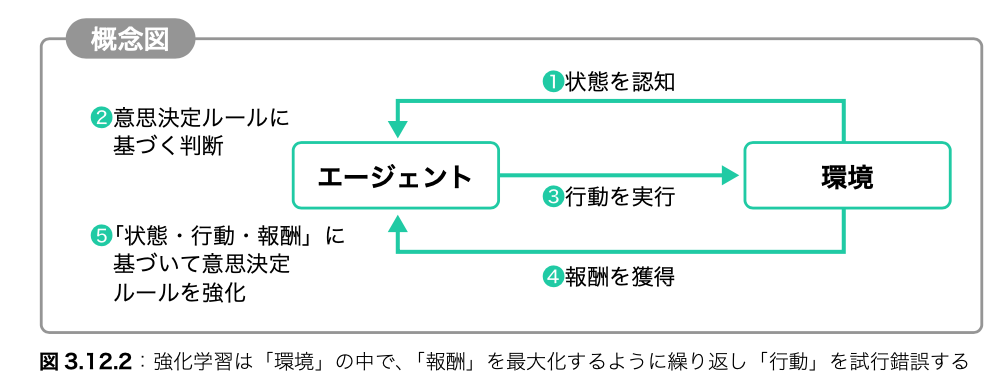
出典:ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[明瞭解説+良質問題]
https://www.sbcr.jp/product/4815611675/
バイアス除去手法の2種類のモード
言語モデルのバイアス除去手法には2種のモードを提案しています。
Mode1: Word Embedding Debias (埋め込みモデル)
Mode2: Classifier Guided Debias (分類器)
本研究における「報酬」とは、ベースラインGPT-2を用いた場合の方策とバイアス除去手法を適用した時の方策の比率、そしていずれかの方策から得られた加点を考慮して計算されたものです。この報酬を設定することにより、エージェントは、バイアス無しの文章を生成できるようにどんどん「賢く」なって最適化されていきます。
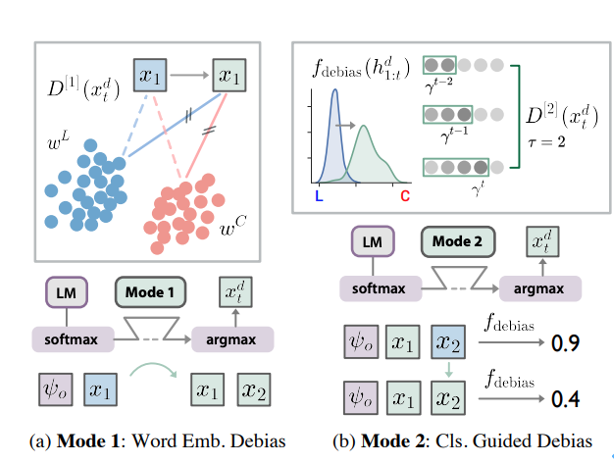 原論文より出典: 2つのモード(埋め込みと分類器)で強化学習によるバイアス除去を行なっています。
原論文より出典: 2つのモード(埋め込みと分類器)で強化学習によるバイアス除去を行なっています。
バイアス除去は文章生成の中で行われるものの、以下のメリットが保たれます。
1)新たに学習データを集める必要がない
2)もとの言語モデル(GPT-2)を再訓練する必要がない
性能評価のための実証実験
3種のモデルから生成された文章を評価しました。
- ベースラインGPT-2 、バイアス除去なし(論文ではvanilla GPT-2と記述)
- Mode1でバイアス除去されたGPT-2(単語埋め込みモデル; word embedding)
- Mode2でバイアス除去されたGPT-2(分類器; classifier)
実験のセットアップ
実証実験の以下のモデルを準備する必要があります。
- 文章生成モデル: 40GBのコーパスで訓練されたGPT-2; パラメータ数355M
- 政治バイアスを判断する分類器: LXNet(GPT-2が生成した文章を入力とする)
LXNetを大規模な政治的イデオロジーのデータセット”Media Cloud Dataset”で訓練しました。10以上のリベラル派と保守派のメディアから収集された260k以上のニュース記事を含みます。
定性的な評価
間接的バイアスのpromptをトリガーとして3種類のGPT-2のそれぞれが生成した文章を、文章分類器XLNetに入れてバイアスを判断した結果を観察します。クラスタリング手法(UMAP)を用いて可視化した結果は下図に示されています。
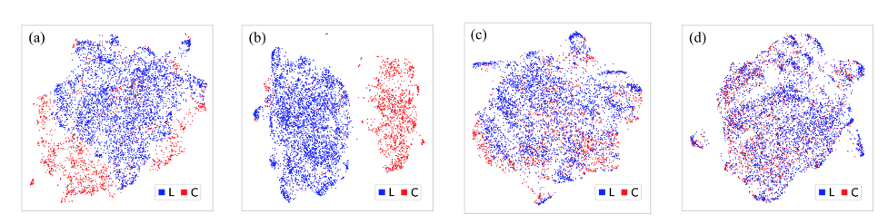 (a)と(b)は通常のGPT-2の生成物をXLNetで文章埋め込みした出力です。このうち、(b)だけは政治バイアスに対してチューニングされているXLNetを使っています。(c)と(d)はバイアス除去されているGPT-2で生成した文章に対する結果です。(c)はMode1(word embedding)、(d)はMode2(classifier)を使ったものです。 図は原論文より出典
(a)と(b)は通常のGPT-2の生成物をXLNetで文章埋め込みした出力です。このうち、(b)だけは政治バイアスに対してチューニングされているXLNetを使っています。(c)と(d)はバイアス除去されているGPT-2で生成した文章に対する結果です。(c)はMode1(word embedding)、(d)はMode2(classifier)を使ったものです。 図は原論文より出典
図から以下のことが観察されます。
XLNetが政治バイアスに対してチューニングされていない(a)の場合でも、LとCの分離したクラスタが見えています。(b)の場合はさらに顕著です。これはバイアス除去を施していないGPT-2では生成された文章に政治的バイアスを被ることを示しています。
対照的に、(c)と(d)はバイアス除去を施されたGPT-2で生成した文章の結果です。この時、XLNetが政治バイアスに対してチューニングされているものの、クラスタの明確な分離が見えていません。
定量的な評価
下の表はベースラインGPT-2に比べ、バイアス除去されたGPT-2のバイアスを計算した結果を示しています。全ての属性に関して、間接的・直接的バイアスともに大きく減らされていることが見受けられます。また、全般的に、Mode2(分類器ベース)がMode1(埋め込みベース)よりもバイアス除去の性能が高く出ています。トピックのうち、Healthcareと Immigration、ジェンダーの”Female”はMode1の成績が特に低めです。
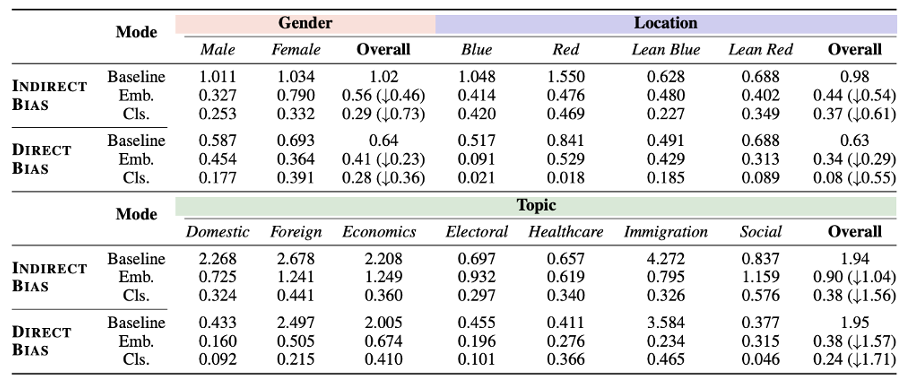 バイアス除去性能の定量評価の結果。Baselineに比べてそれぞれのModeでバイアス除去した結果であるEmbやClsの方が数値が低く、バイアスの削減を表します。 ※ 原論文より抽出
バイアス除去性能の定量評価の結果。Baselineに比べてそれぞれのModeでバイアス除去した結果であるEmbやClsの方が数値が低く、バイアスの削減を表します。 ※ 原論文より抽出
以上により、本研究の手法は、政治バイアスの除去に効果的であることがいえます。
文章生成の質とのトレードオフ
バイアス除去の機能が強くなればなるほど、”perplexity”(生成された文章の分かり難さ)が増える傾向にあります。ユーザーは自分の好みでパラメータを調整することでこのバランスを図ることができます。
記事の執筆者の感想
画像、音声、自然言語、さらにマルチモーダルの分野でニューラルネットワークの「精度」だけを競ったところでは、限界まで来ているではないかと感じます。「すごいことが出来る」と分かった今、精度をある程度犠牲にしても社会の中での使いやすさを重視すべきだと思います。せっかく有能な技術が開発されているので、社会の中で有益に使用できるようにするための研究が近年重要視・期待されるでしょう。
- モデルの透明性・解釈可能性
- モデルの公平性、バイアスをなくす
- モデルを構築するコストの削減、AIの民主化
今まではモデルを高性能で大きくする風潮がありましたが、これからはモデルをより小さくし、よりシンプルにすることが1つの方針になるでしょう。
以下は、自然言語の分野に絞って、特に課題と感じるポイントを取り上げます。
■公平性の担保
自然言語処理は人間の言語を対象とするため、どうしても人間社会に潜むバイアスに影響されやすくなります。性別、人種、宗教などの属性に左右されるモデルを使用した場合、特定のグループにとって不利な結果を出力してしまいます。有名な事例としては、Amazon社が開発したAI人材採用システムで、履歴書に「女性」という単語が含まれると評価が下がるように学習してしまったことです。参考:ロイターの報道リンク
もちろんGPTも文章生成の能力が高く評価されていると同時に、公平性の問題が指摘されています。例えば、女性という単語から生成された文には「美しい」や「華やか」などフェミニンな単語を含む傾向が現れています。共起する単語の感情スコアを検証したところ、「黒人」はネガティブな表現と共起しやすく、「イスラム教」は「テロリズム」と共起しやすい、という許しがたい結果が出ました。世界の平和・秩序を取り戻す、維持することが重要視される現在の世の中、これらは非常に重大な問題といえるでしょう。
そして、自然言語モデルから見られるアルゴリズムバイアスやデータバイアスは、人間社会に潜むバイアスや社会問題をあらわにしてくれる存在でもあるでしょう。
■モデルサイズを工夫
近年開発された有名な言語モデルのパラメーター数が驚くほど膨らんでいきます。2018年に提案された「BERT」のパラメーター数は3億程度であるのに対して、2020年の「GPT-3」が1750億個程度まで巨大化しました。
確かに、パラメータ数の多いモデルほど、幅広いタスクにおいて汎用的に高い性能を発揮できると言えます。しかしデメリットはコストです。パラメーター数とともに、学習データの量と計算資源も増やす必要があります。近年の巨大モデルの学習には数百〜数千個のGPUやTPUを使います。パラメーター1000個に対しておよそ$1使用すると見積もられているので、GPT-3(1750億個)は10億円を超えます!だからこそ言語モデルの研究開発は、どうしても計算のリソースや予算を使えるIT大手企業を中心に競い合われることになります。
参考:The Cost of Training NLP Models: A Concise Overview
■法規制をなるべく早めに整備する
自然言語処理モデルに限らず、AIを社会に適用する上で、人間が想像できる以上のリスクがあることがわかった今、AIを開発・使用するための法規制を明確に設定すべきです。法規制は技術の発展を阻害する、あるいは、トレードオフな関係にあると考えられることが多いです。しかしこれは浅すぎる、むしろその逆ではないでしょうか。
仮に法律が全く存在しない国があったとすると、そこにどんな素敵な大自然があったとしても、殆どの人はその国に旅行しないはずです。同様に、リスクが公表されておらず法律が設定されていない技術を使いたい人は多くないはずです。技術は一般の人々に使われてこそ改善され続けられます。よって、多くの人々に安心して使われるために、専門家の協力を得ながら、法律の体制を国や政府レベルでしっかりと整えなければいけません。
■リスクだけではなく、有益な使い方を知ってもらう
以前のレポートで「ディープフェイク」という技術の有益な使い方をそのリスクとともに紹介しました。ディープフェイクには有益な使い方も?
画像や文章の生成技術はエンターテインメントやクリエイティブ分野で人間社会にとって喜ばしい目的での利用されることが期待されています。
例えば、画像・音声を生成する「ディープフェイク」に関していうと、有名な芸術作品を学習させて、新作を生み出す[1]ことができます。また、亡くなった大切な方の写真をもとに「動く擬似写真」に変換し「蘇らせる」[2]事例も公開されています。このような人間を幸福にするような使い方に感心しました。自然言語モデルのGPTを用いて同様な成果を残せるのではないでしょうか。例えば、大切な方が書いた言葉(日記、手紙、音声書き起こしなど)をプロンプトに使い、「会話」を生成できたら心のリハビリを支援する手段になると思いました。もちろんこれらの使い方にも、心理的な悪影響や詐欺に悪用される事も考えられるので、リスク防止対策を用意することが必須です。リスク明確化や有効性の検証など、まずは臨床心理分野等と連携して進んでいけたら、と願っております。
[1] https://mainichi.jp/articles/20220104/ddm/003/070/030000c
[2] https://www.myheritage.ch/deep-nostalgia
今回も最後まで読んでいただき、ありがとうございました。
担当者:ヤンジャクリン(分析官・講師)













