機械学習にはいくつかの手法があり、学習対象によって最適な手法は異なると考えられます。
現在では scikit-learnなどのライブラリを用いることで、モデルの作成や学習は数行でできるものの、思い当たる機械学習の候補全てで精度比較を行うには膨大な量のコードを書く必要が出てきます。
PyCaretと呼ばれるPythonライブラリを用いることで、さまざまな機械学習手法を一瞬で試せるようになり、精度を簡単に比較することが可能になります。
この記事でやること
- PyCaret の導入および精度比較の流れを説明します
- 実際のデータセット(mnist_784 データセット)を用いてJupyter上で行う精度比較の具体例を示します
PyCaret の導入
PyCaretのライブラリ自体は、pipやanacondaなどで簡単に入れることができます。
ただし、機械学習のさまざまなライブラリを同時にインストールするため、依存関係が複雑になっているようです。
筆者がインストールした時のPyCaretのバージョンは2.3.10でしたが、既にscikit-learnというライブラリが入っている場合、そのバージョンを0.23.2以下にバージョンダウンする必要があるようです。
pip install scikit-learn==0.23.2
pip install pycaretpipでのscikit-learnのバージョンダウンとpycaretのインストール
PyCaretによる精度比較
データセットを用意すると(ここでは pandas.DataFrame 型の学習データとしてdf、その中のターゲット列名をTargetとします)、以下の記述だけで精度の比較ができます。
from pycaret.classification import *
setup(data = df, target = "Target")
best_model = compare_models()
にわかには信じがたいことかもしれませんので、次の章で例を示します。
実際のデータセットへの適用
今回はmnist_784 データセットを用いました。これは機械学習でよく使われる、1桁の手書き数字の28×28=784pixelの解像度での画像のデータセットです。
引用元:https://www.atmarkit.co.jp/ait/articles/2001/22/news012.html
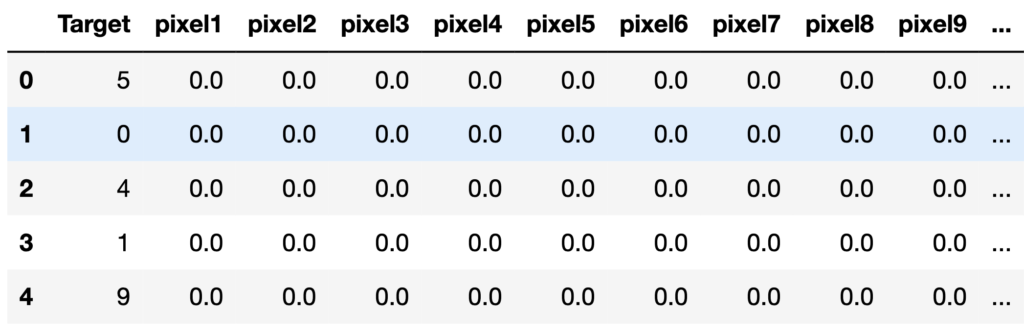
データセットは以下のようになっています。
Targetはその画像で書かれている数字の種類であり、それ以降で784個のpixel(画像を構成している小さい四角の塊)ひとつひとつに対するグレースケールの値を示します。真っ白なピクセルが0で、真っ黒な場合は255です。
このデータセットをdfとしてロードするためのコードは以下の通りです。
scikit-learnのfetch_openml()を用いることで、mnist_784のデータをロードできます。今回は学習時間等の都合で、最下行でデータを10,000件に絞って取り出しています。
from sklearn.datasets import fetch_openml
import pandas as pd
dataset = fetch_openml("mnist_784", version=1, as_frame=True)
data_df = pd.DataFrame(dataset["data"])
target_ds = pd.Series(dataset["target"], name="Target")
df = pd.concat([data_df, target_ds], axis=1).loc[1:10000]
あとは「PyCaretによる精度比較」の章で示したコードを実行するだけです。
このとき setup()の部分でデータの確認と前処理がなされ(処理の後一度Enterキーを押す必要があります)、compare_models()で各機械学習手法での精度比較が行われます。
GPUのない環境でも5分ほどで処理が終わり、以下のように手法(Model)ごとの各指標による精度が出ます。最も良いモデルの情報がbest_modelに格納されます。
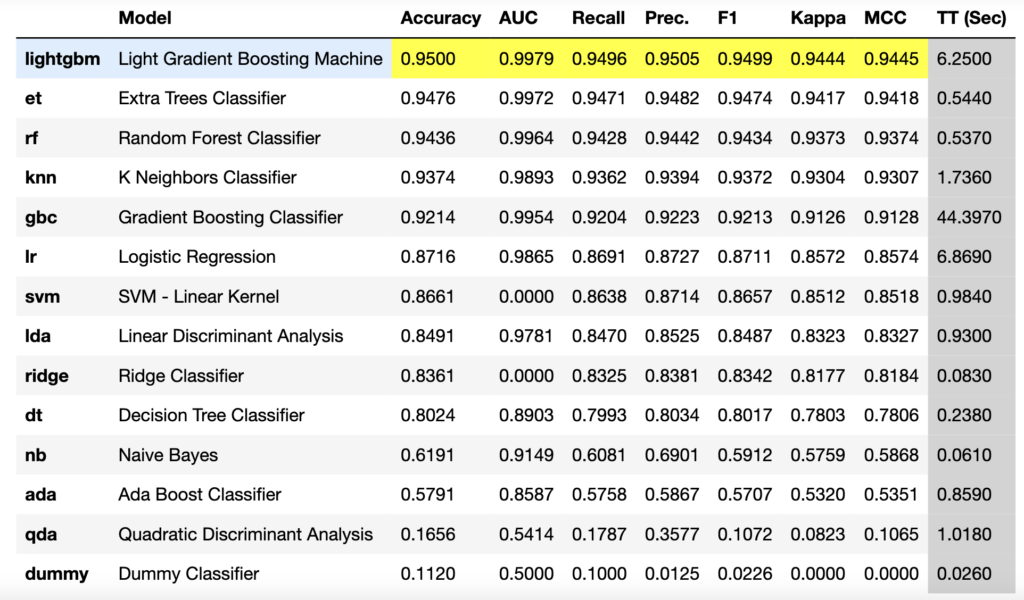
ここから、lightgbm(Light Gradient Boosting Machine) での精度がどの指標でも高いことがわかり、採用すべき機械学習モデルであると言えます。
また、TT(学習時間)と精度のバランスで見るとet(Extra Trees Classifier)やrf(Random Forest)も良い手法であると言えそうです。
Modelでの各手法の詳細や精度評価の指標についての説明は割愛しますが、上記で挙げた手法はいずれも決定木によるアルゴリズムに分類されます。
特にLightGBMは弊社の自動機械学習ツールForecastFlowにも採用されており、幅広いタスクで高精度なモデルを作りやすい手法と言えます。
PyCaretでは機械学習手法ごとの詳しい精度を見たり、モデルのデータやさまざまな情報を取得することも可能ですが、そのような「応用編」については次回以降説明していきます。