
ことの発端
は友人の結婚式の2次会でのこと。
2次会恒例(?)のビンゴゲームに興じていたんですが、ランダムで数字を生成する(と称している)ビンゴゲームのアプリでやっていたんですね。
すると、出るわ出るわ「57」。3連続で出たり、10回に一回くらいのペースで出たりと大暴れです。そもそも重複なく出るような設定であれよ、と思うんですが一旦そこはグッと堪えましょう。
これは流石におかしいだろと思い一緒にビンゴをやっていた友人に「どういう設定?全然ランダムじゃねえじゃねえか」と言ったところ、その友人は訳知り顔で

とのたまうではありませんか。
、、、いや一応自分もデータサイエンティストの端くれ、大学院で研究してた時も乱数生成よく使ってたしランダムが意外に偏るのはわかるんですよ?
ニュートンさんもわかりやすい例を用いてこう言ってますし。
二つの図のうち「ランダムな点の分布」はどちら? こう聞かれて,「左」と答える人もいるでしょう。実際は「右」がランダムな点の分布で,左は点どうしがなるべく重ならないように配置したものです。人は,ランダムである右の図から,“意味がありそうなパターン”を読みとってしまいがちなのです。 pic.twitter.com/tDiheQcUM6
— 科学雑誌Newton(ニュートン)公式 (@Newton_Science) August 21, 2018
ただ、それを考慮しても75個の数字から選ぶのに、3連続とか10回に一回とかのペースはおかしい。そういう疑問提起だったわけです。
とまあ、水掛け論してもしょうがありません。シミュレーションして白黒はっきりつけようじゃないですか。
白黒ハッキリさせたいこと
つまり以下の帰無仮説が棄却できそうかどうかを確認していきます。
1-75の75種類の整数からランダムに1個整数を出す操作を100回繰り返す時、10回同じ数字が出るのは良くあること
(正直もっと出ていた気もしますが、こんなもんにしといてやります)
具体的には以下のようなプロセスで検証します
- 1-75の整数から一つ数字を選ぶ
- ①を100回繰り返す
- 100回の中で最も出た数字の出現回数を記録(例:「57」が6回出て、他の数字はそれ以下だったとすると「6」を記録)
- ①〜③を10万回繰り返し、最頻値の出現回数を10万個取得
- ④で得た10万個の最頻値の出現回数の分布を確認、10回同じ値が出るのがどの程度あり得そうなのかを確認
シミュレーションしてみる
以下のコードで上で書いたプロセスを再現しています。
import collections
import random
import pandas as pd
# 1-75の中からランダムに{count}個の整数を生成
def get_numbers(count):
return [random.randint(1, 75) for i in range(count)]
# 生成したランダムな整数のリストから最頻値の出現回数を取得
def get_mode(list_numbers):
c = collections.Counter(list_numbers)
return c.most_common()[0][1]
# 100個の数字を出すことを10万回繰り返してデータ出力
count = 100
realization = 100000
list_mode = []
for i in range(realization):
list_mode.append(get_mode(get_numbers(count)))
df_mode_dist = pd.DataFrame(list_mode, columns=['mode'])
df_mode_dist.to_csv("./output.csv", index=False)
結果は以下の通りになりました。3回と4回に集中しておりこの程度ならば「良くあること」と言えそうです。が!7回までで99.5%、10回以上同じ数字がでる確率はわずか0.01%。文字通り万が一の確率です。ほら見てみい!
これは流石に「良くあること」とは言えないんじゃないでしょうか?
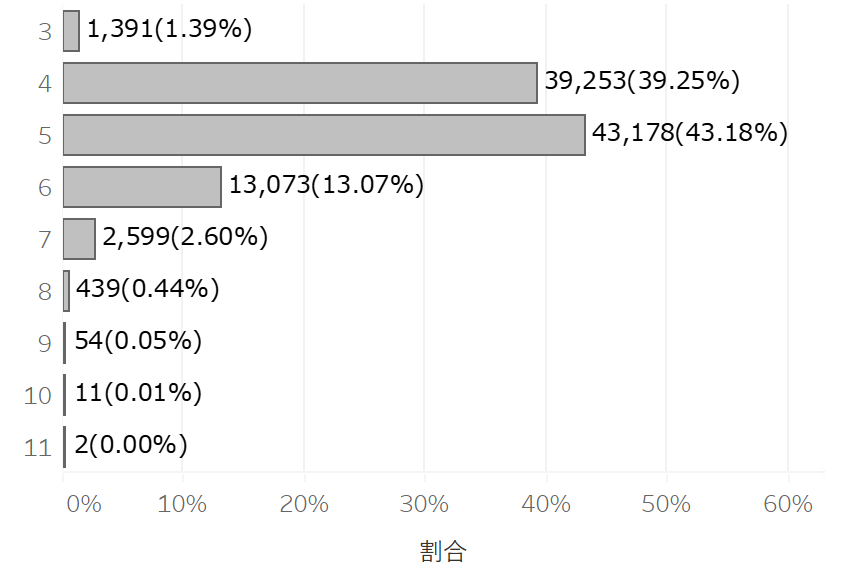 シミュレーション結果のプロット。縦軸が「最頻値の出現回数」、横軸がその出現割合を表す。棒グラフの横の数字は出現回数(合計すると10万)、()内の数字が割合。
シミュレーション結果のプロット。縦軸が「最頻値の出現回数」、横軸がその出現割合を表す。棒グラフの横の数字は出現回数(合計すると10万)、()内の数字が割合。お互いの直感をぶつけ合う不毛な水掛け論にサラバ、データサイエンス万歳!
ご指摘ある方オナシャス!














