前回、自然言語処理における事前学習と転移学習に関して、以下のように書きました。

最新の事前学習モデルとして、OpenAI*1が開発したGPT(Generative Pre-Training)系列のモデルが有名です。本記事では、GPTの技術について紹介します。
GPT-nモデルの全体的説明
GPTは、過去の単語列から次の単語を予測するように学習を行います。文章の内容や背景を学習する上で高い性能を発揮し、幅広い「言語理解タスク」に対応できます。例えば、文章分類に使われる評判分析(sentiment analysis; 入力文がpositiveかnegativeかneutralかを判定)、質問応答(question answering; 常識推論、質問文が与えられたときに、適切な回答を選択肢の中から選ぶ)、意味的類似度(semantic similarity; 2つの文が同じ意味かどうかを判定)などが挙げられます。
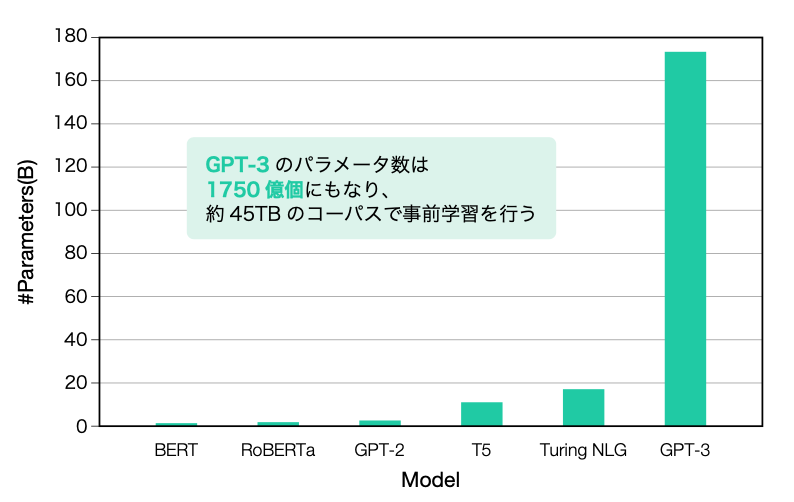
初代のGPT、GPT-2、GPT-3の順で相次いでバージョンアップしていきました。これらを本記事でGPT-nと呼んでいます。下図からもわかるように、GPT-2とGPT-3は初代のGPTに比べてパラメータ数が桁違いに増加しています。初代GPTはパラメータ数が1.1億、2019年に発表されたGPT-2は15億、2020年のGPT-3は1750億と、GPT2の約117倍以上になります!モデルのサイズアップに伴い、長い文章を生成する能力や高度なタスクに対応する能力も上がっていきました。
本節の残りでは、GPT-3を中心にお話していきます。
GPT-nモデルを含む事前学習モデルのパラメータ数 GPT-3のパラメータ数は1750億個にもなり、約45TBのコーパスで事前学習を行います!
引用:OpenAIのブログ, https://towardsdatascience.com/gpt-3-the-new-mighty-language-model-from-openai-a74ff35346fc
GPT-3による文章の自動完成
GPT-3の仕組みについて特筆すべき点を紹介していきます。
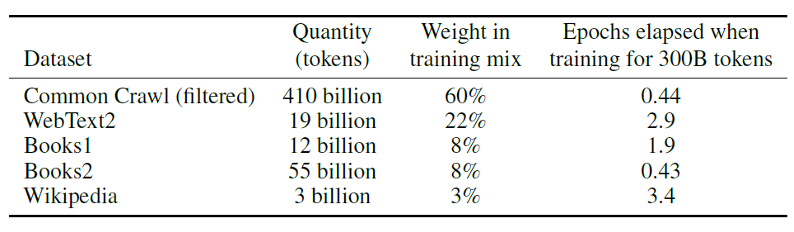
前述の通り、GPT-3のパラメータ数は1750億個もあり、モデルを学習するために約45TBにもなる大規模なテキストデータ(コーパス)を事前学習します。この巨大データセットには何千億もの単語や語句も含まれています。学習データの多くはウェブからデータをスクレイピングしたものや電子化された書籍やウィキペディアから来ています(下表)。
出典:https://arxiv.org/abs/2005.14165
GPT-3の構造は、トランスフォーマー(Transformer)を基本としています 。エンコーダを持たず、トランスフォーマーにあるデコーダと似た構造を持つネットワークになっています。トランスフォーマーは2017年にGoogleが発表した(当時は主に機械翻訳のための)言語モデルです。以下の記事の説明がわかりやすいです。
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
GPT-3では「ある単語次に来る単語」を予測し、自動的に文章を完成できるように、教師なし学習を行います。例えば、以下のような単語系列の次に来る単語を予測するケースを考えましょう。
”I”、”need”、”ice”、”because”、”my”、”drink”、”is”
出力値は「その単語が次に来る確率」です。単語の確率が、”hot”:50%、”warm”:30%、”good”:15%、”cold”:5%になったと仮定すると、”I need ice because my drink is”の後に続く単語は”hot”が尤もらしい候補で、”warm”はまあまあ可能性がある、”good”や”cold”は確率が低いと推測できます。
GPT-3は何がすごいのか
その1:幅広い言語タスクを人間の知能を思わせるような高い精度で実現できることがすごい
ビッグテキストデータセットを用いて巨大なネットワークを学習しているだけに、GPT-3は今までにない精度で、入力された言葉に続く言葉を推測することができます。そのため、あったかも人間が書いたような文章も自動生成できたりします。文章を生成するだけでなく、翻訳、質疑応答、文章の校正、文章の穴埋めなど、実に様々なアプリケーションで使用されています。例えば…
・自然言語からソースコードを生成する
・楽譜を創作する
・デザインを生成する
(参考)https://gptcrush.com/resources/
オフィスの中で、GPT-3を活用してマニュアル、提案書、報告書、会議議事録など業務上必要な書類を自動生成することが想像できますね。
その2:数少ない事例で言語能力を習得できることがすごい
GPT-3に文章の書き出し、プログラミングコードの最初のたった数行を与えて実行するだけで、様々な用途に合わせて続きを自動生成できます。このような少数の事例で学習できるAIを「Few Shot learning」と呼びます。原論文のタイトルはまさに「Language Models are Few-Shot Learners」です。
参考:https://arxiv.org/abs/2005.14165
このことは、楽に転移学習に使えること、とも関係しています。GPT-3は事前学習したモデルと同じモデルを転移学習に使用できます。つまり、モデル再構築やアルゴリズムの最適化のプロセスを省くことができ、少量の正答例を付与するだけで、文章生成など個別のタスクにモデルを適用します。ただし、事前学習(基礎訓練)には相変わらず膨大な量のデータが必要であることに注意してください。
GPT-3は、驚くほど高度なタスクを実行できる能力を示している一方で、その利用に関しては社会的な問題とリソース的な問題が報告されています。後続の記事では、このようなGPT-3の活用に関する課題について述べます。
ここまで読んでいただきありがとうございました。それでは、次回またお会いしましょう。
記事担当:ヤン・ジャクリン(分析官・講師)
関連記事
*1:OpenAIは、宇宙開発企業スペースXとテスラの両方の共同設立者とCEOを務めるイーロン・マスクらが設立した非営利団体です。













