
こんにちは!今回は自社の自動機械学習ツール「ForecastFlow」と Python パッケージの「tsfresh」を使って時系列データからのクラス分類予測モデルを作ってみました。その結果、かなり要領よく予測モデルの構築ができそうだということが分かったので記事にまとめます。
このブログの内容は すいすい会 第29回「IoTセンサーデータのお手軽な予兆分析(時系列データの自動機械学習と自動特徴量作成)」で紹介しました。資料や動画は GRIのコーポレートサイトから参照ください。
概要
まず結論からいうと以下のようになりました。
- 自動で特徴量設計と機械学習を行う
- 高速で予測モデルが設計できる
- 数回の試行で高精度のモデルが設計できる
- 複雑で理解が難しい時系列データの特性を素早く理解できる
ちなみに今回後述する例では、予測モデルに費やした時間はデータセットの用意・整形・特徴抽出含めて約3時間ほどで、精度は元論文のものを超えました!(加えて頭を使った部分は Pandas でのデータ整形の部分くらいでした。)
時系列データとは
時系列データとは時間とともに変化するデータのことで、株価、加速度、音声、スペクトログラムなどが当てはまります。また、気温や人口などを連続的に観測してあつめたデータも時系列データです。このような時系列データは至る所で集めることができ、日常生活でも様々な場面で利用されています。
そのような時系列データで何かを予測するモデルを考えるとき、時系列の特性を良く理解した上で機械学習に入れやすいように整形する必要があります(そのままの原系列を入れる手法もありますが、その場合できることは限られています)。しかし、時系列データからとれる特性は多くあり、またその方法も数多くあり、明確な特徴量設計を行うのにかなりの知識とプログラミング力が必要となります。
サンプルデータでのテスト
では例題を元に時系列データのクラス分類をやっていきたいと思います。今回使用したデータセットは UEA & UCR Time Series Classification Repository に置いてあったデータセット「AsphaltObstacles」を使用します。このデータセットの問題設定は車に取り付けた加速度センサー(の速度変化)から通過した障害物の種類を予測するというものです。このデータセットを公開している論文では最大正答率は 81.13%でした。
※元論文全体は pdfのダウンロードにお金を求められてしまい概要しか読めていませんが、おそらく原系列を使って学習してそうです。

このデータセットの訓練用または予測用と各障害物の内訳は次の通りです。
| 横断歩道 | ロードマーカー | パンプ | 道路のつぎはぎ | |
| 訓練用 | 80 | 93 | 106 | 111 |
| 予測用 | 80 | 94 | 106 | 111 |
また、加速度センサー(の速度変化)をプロットしてみると障害物ごとに次のような大まかな特徴がみられました。加えて、「ロードマーカー」と「道路のつぎはぎ」の時系列パターンは似ている印象で分類が難しそうです。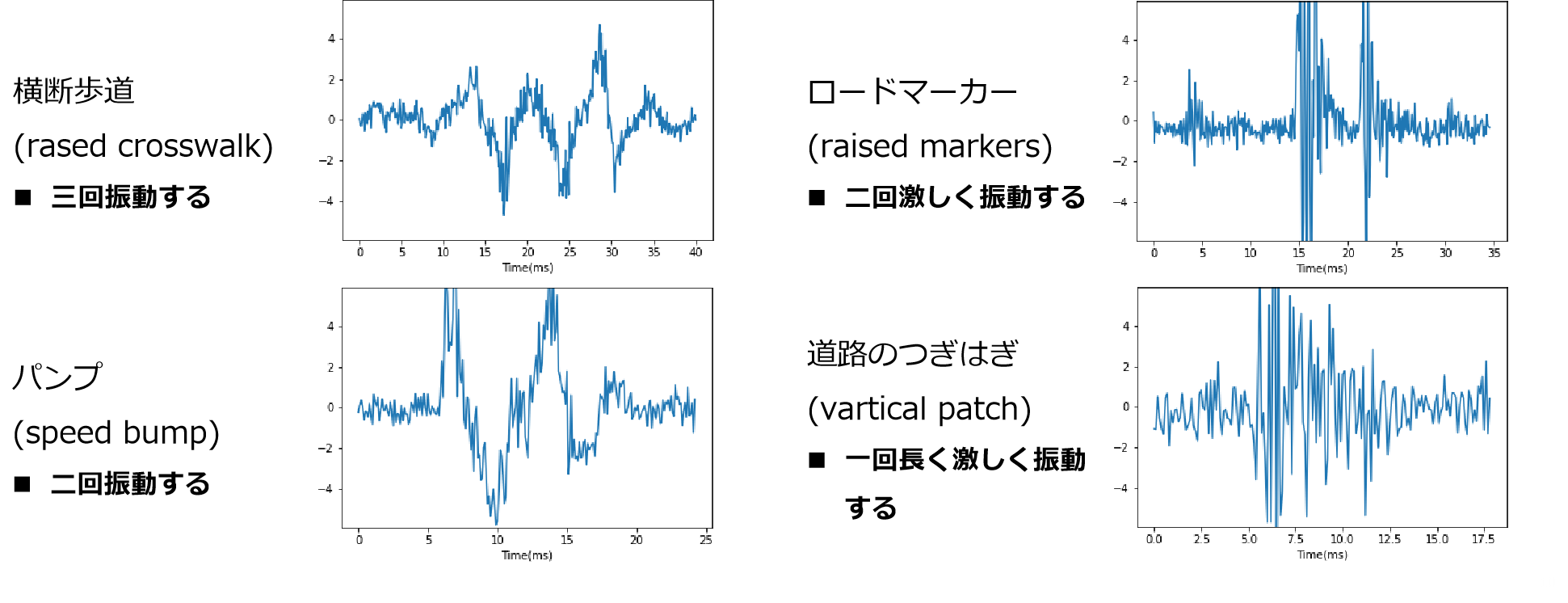
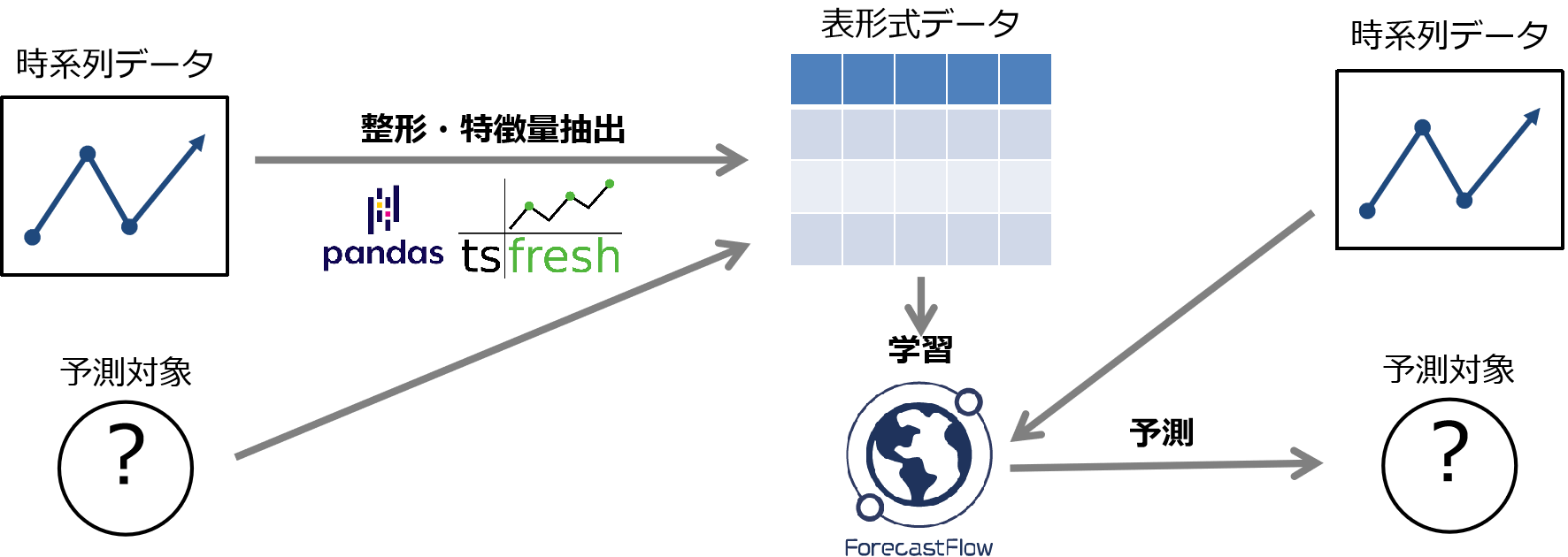
データ整形
ForecastFlowは表形式のデータを使って学習を行います。なので、観測点の数がまちまちだったりその順番が重要である時系列データをそのまま学習させることはできません。そこで、時系列データから特定の特性を抽出し表形式データに落とし込む必要があります。例えば、周期性を抽出する際にはフーリエ変換像のパワースペクトルやウェーブレット変換のスカログラムを、スパイクを抽出するにはピークのかずを数えたり、外れ値検定などを行います。この部分を Pythonパッケージの tsfreshを用いることでたった一行のコードで行うことができます。(tsfreshの使い方等については別記事にまとめています時系列データから大量の特徴量を生成するパッケージ「tsfresh」の使い方)
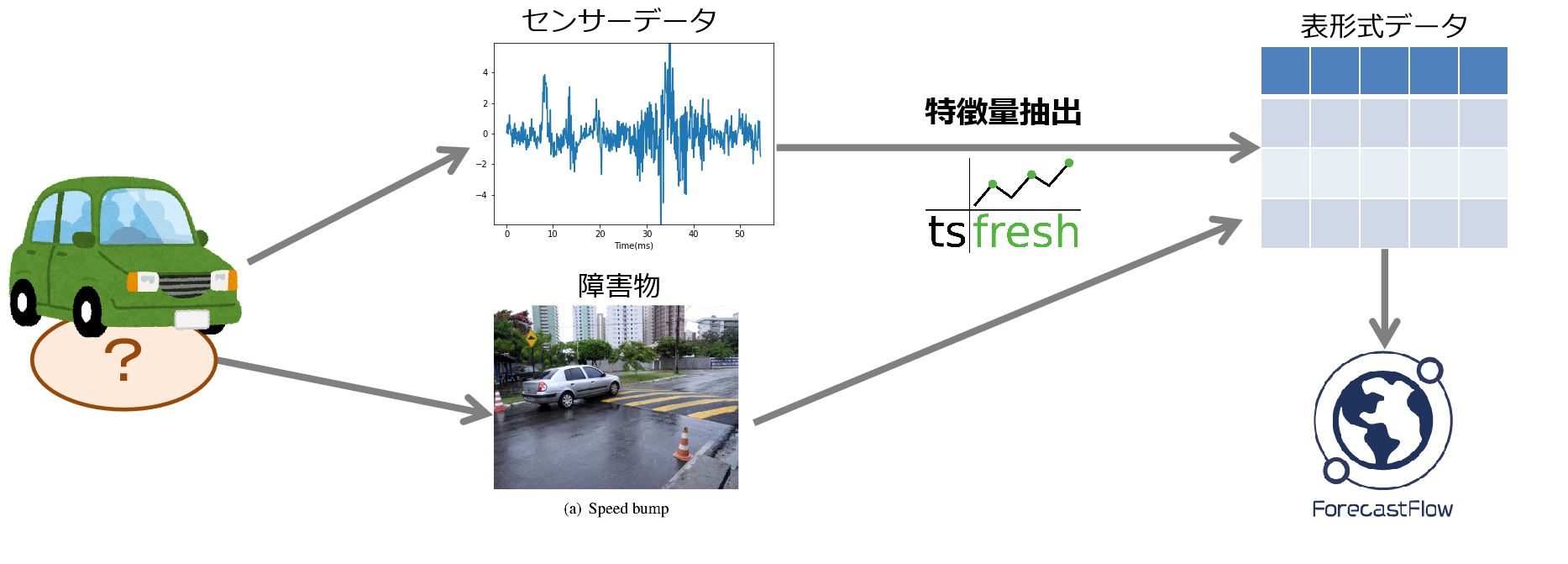
この時点での特徴量数は143個です。手作業でこの数の特徴量を時系列データから抽出しようとすると、それだけでかなりの時間を費やしてしまいそうですが、tsfreshを用いたことにより 2分程度で表形式データを用意することができました。
学習
学習には ForecastFlowを使いました。過去の記事でも何度か紹介されていますが ForecastFlowとは GRIが開発した自動機械学習ツールでノンコーディングで予測モデルを構築してくれます。
加えて、ForecastFlow側で強相関な特徴量を探し取り除くことが可能です。tsfreshにはこのような特徴量同士の強相関性を考慮する機能はなく、ForecastFlow内で素早く特徴量の選定を行うことができます。今回のケースでは強相関を取り除いても学習スコアに大きな変化はありませんでしたが、特徴量数が多い場合に学習スコアを良化させる効果が期待できます。
※今回の例では特徴量数を143 → 97まで減らすことができます。
訓練用データで学習し、予測用データで精度検証を行った結果は以下の通りです。
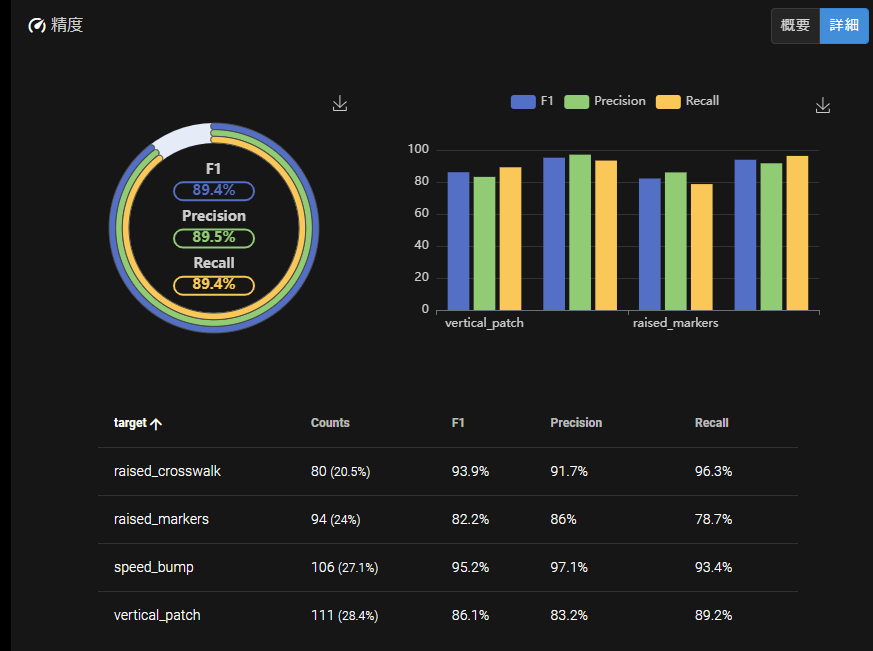
サンプル数 390個にしてはかなりの精度が出ていると思います。また、このときの混合行列は以下の通りです。
| 予測 | |||||
| 横断歩道 | マーカー | パンプ | つぎはぎ | ||
| 正解 | 横断歩道 | 79 | 1 | 11 | 0 |
| マーカー | 1 | 76 | 0 | 23 | |
| パンプ | 0 | 1 | 101 | 0 | |
| つぎはぎ | 0 | 26 | 1 | 102 |
ここから正答率を計算すると 89.4%となりました!これは論文の最大正答率 81.13%を約 8%上回っています。このように、tsfreshと ForcastFlowを組み合わせることで短い時間で・短いコーディング量で・高精度な予測モデルを構築することができます。
時系列特性の解析
ForecastFlowでは予測モデルの構築の他に、どの特徴量が重要かを分析する感度分析を行うことができます。これを利用することで tsfreshから抽出した特徴量で何が予測上大事であるかを分析。即ち、時系列データと予測ターゲットの関係性・特性を予測モデルから教えてもらうことができます。
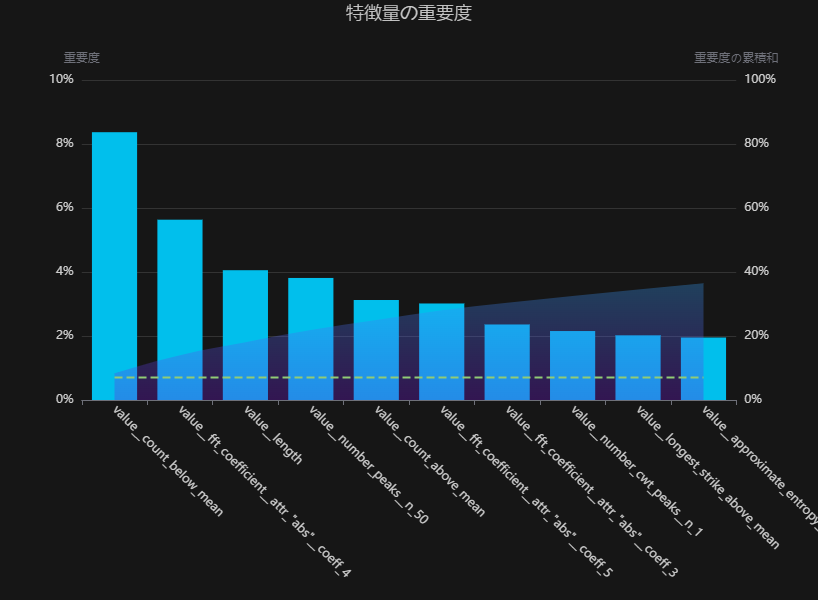
少し見づらいかもしれませんが、「fft」即ちフーリエ変換による、周期性に関する特徴量が上位に多く、障害物を分類する上で重要な要素は周期性であるということがわかります。
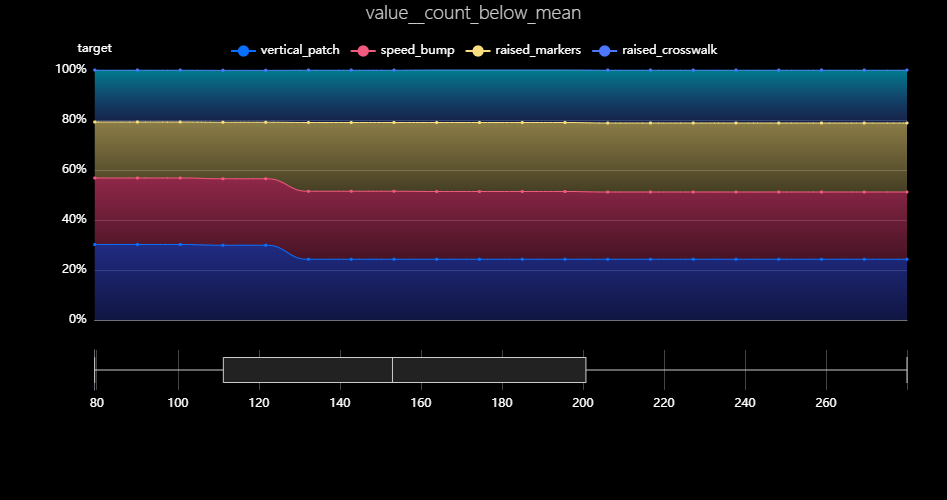
さらに、重要特徴量1位の「count_below_mean」の部分依存グラフをみると、値130 あたりを境に「横断歩道」と、「ロードマーカー」と予測される確率が変動していることがわかります。「count_below_mean」とは、時系列全体の平均値より値が小さい観測点の数のことで、私は時系列データのグラフをみたときにこの特徴量が重要そうとは思いもよりませんでした。
想定されるユースケース
どのようなケースでこの tsfresh+ForecastFlowによる予測モデル構築が活用できそうなのかを考えてみましたので、ご紹介させていただきます。
例1)状況・行動の予測
Apple Watchなどのウェアラブルセンサー・活動量計から心拍数や加速度を時系列データとして取り込むことで、装着者が今現在寝ているのか・歩いているのかなどの状況・行動が予測できます。もしこれが実現できるならば、介護施設などで深夜徘徊などの異常行動を検知することができ職員の労働環境を改善することが可能です。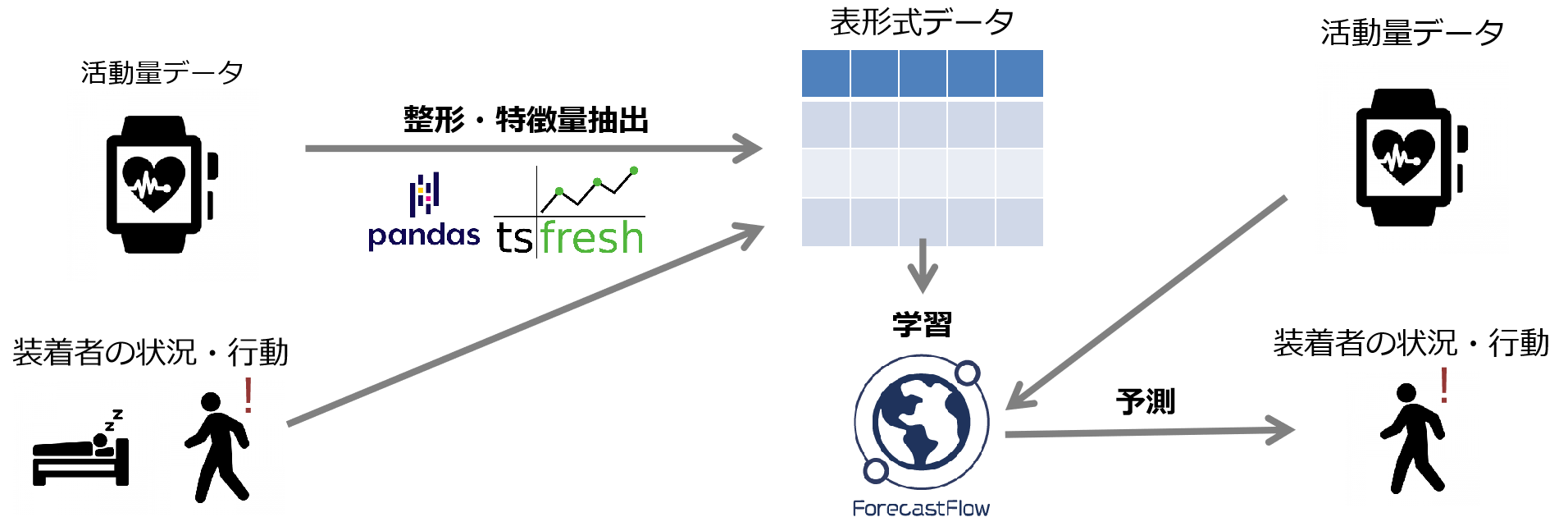
例2)趣味・興味の予測
普段私たちから利用しているスマートフォンやパソコンから閲覧しているインターネット利用状況(Web行動履歴)を時系列データとして取り込むことで、閲覧者の趣味や興味を予測することが可能です。そこから、閲覧者個人に対してオススメ商品のレコメンドを行うことができます。この形式のデータは閲覧回数や時間などに丸めて予測に使われることが多いですが、tsfresh+ForecastFlowならば時系列データとしてそのまま扱うことができます。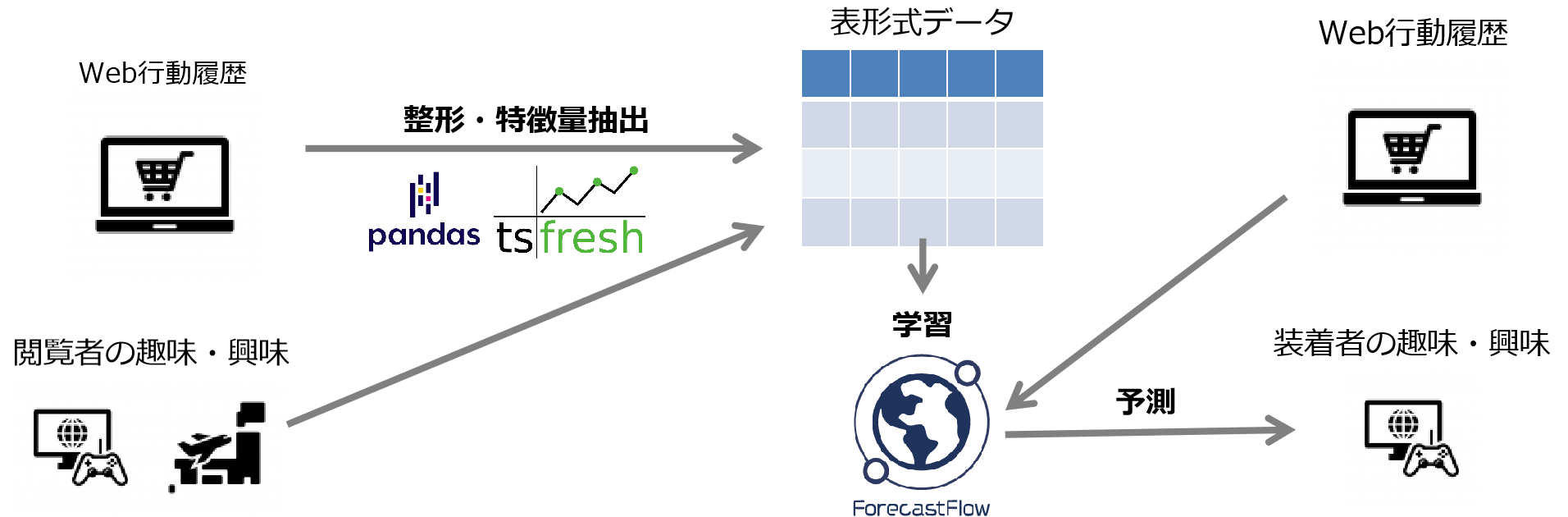
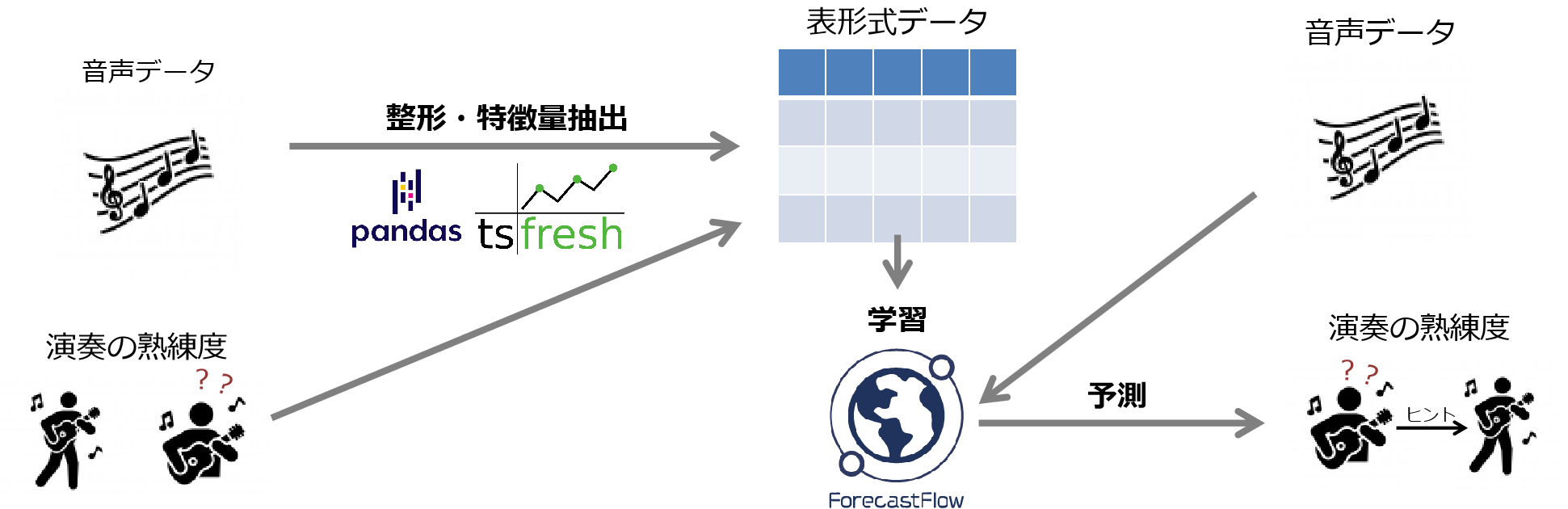
例3)熟練度の予測
時系列データとして扱えれるものとして音声データがあります。楽器の演奏を時系列データとして取り込むことで、プロが演奏したのか初心者が演奏したのかといった演奏者の熟練度を予測することが可能です。そして、その予測モデルの感度分析を参考に初心者の演奏の改善方法を知ることできます(例えば、周波数が違うならば音の高さを変えるように演奏するといった提案ができます)。
最後に
今までは ForecastFlowは表形式の構造化データでしか学習できなかったのが、時系列データに対して初心者でも・短時間で・高精度な予測モデルを構築できることがわかりました。
このような、時系列データの予測で弊社 GRIがサポートできますので是非お問い合わせください。
(もちろん時系列データに限らず、他の種類のデータでも柔軟に対応可能です)
GRIのコーポレートサイトはこちらから
弊社開発の自動機械学習ツールForecastFlowはこちらから
今なら90日間の無料トライアル実施中です!
最後まで読んでいただきありがとうございました。













