
本記事ではまず「事前学習モデル」を紹介し、自然言語処理における代表的な手法の1つであるBERTを詳しく解説していきます。後続の記事では最新のGPT-nモデルについても紹介していきます。
まず、事前学習とは
ディープラーニングにおける事前学習モデル(pre-trained models)とは、大規模なデータセットを用いて訓練した学習済みモデルのことです。一般的に、特定の分野(例:画像分類、テキスト予測)のタスクに共通の汎用的な特徴量を、隠れ層にて「習得」してあるため、転移学習(transfer learning)に利用することができます。事前学習及び転移学習をセットで活用することで、手元にある学習データが小規模でも高精度な認識性能を達成することが出来ます。
転移学習を画像認識の文脈でよく聞きます。例えば、VGG16やResNetなどはImageNetなどを用いて事前学習した画像認識モデルです。同じ仕組みが自然言語処理にも応用されています。同様に、巨大なテキストデータ(コーパスと呼ぶ)を用いて、汎用的な特徴をあらかじめ学習しておきます。
従来では、比較的小さめのデータセットを使って、翻訳や質問応答などに特化したモデルを学習するのが主流でした。2018年以降、巨大コーパスで言語モデルの事前学習を行ったモデルを転移学習に用いる手法に成功しました。それをきっかけに、BERTやGPT系モデルなど、転移学習に使いやすい事前学習モデルが次々と開発・改良されています。
BERTとは
事前学習された言語モデルの先行者は、2018年にGoogleによって提案されたBERT(Bidirectional Encoder Representations from Transformers)です。
(原論文)[1810.04805] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERTの名称にある”Bidirectional Encoder”はどういう意味でしょうか?
わずかに話を逸らして詳細を説明します。リカレントニューラルネットワーク(RNN)を積み重ねて使用することができます。1つのRNNからの出力を別のRNNに入力するだけです。ところが、単独のRNNは過去から未来へと一方的にしか学習できません。そこで、「過去用」と「未来用」の2つのRNNを組みわせると双方向の情報を学習に活用できるようになります。
この双方向言語モデルのコンセプトはBERTにも採用されています。少し違うのは、RNNの代わりにエンコーダにTransformer を使っている”Bidirectional Transformerモデル“であることです。Transformer自身は、エンコーダとデコーダにAttentionのみを採用しており、学習の高速化や離れた位置にある単語同士の関係性も捉えやすいなど様々なメリットがあります。
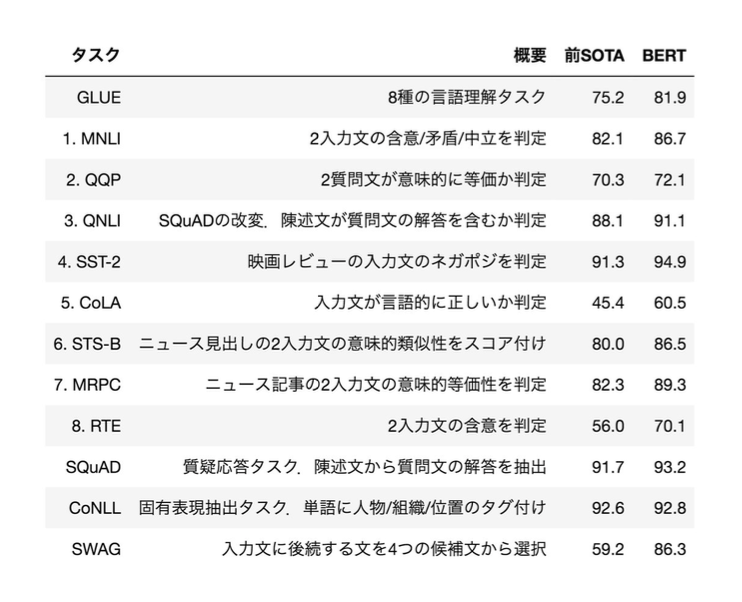
いずれにしても、BERTでは「過去から現在」と「未来から現在」の双方向(Bidirectional)の情報を同時に使用できることがここでのポイントです。BERT は開発当時から各種の自然言語処理タスクで精度スコアの記録を更新し続け、その高い性能と汎用性に一気に注目が集まりました。下図(出典:2018年10月11日にGoogleからArxiv公開された論文)のように、転移学習に使用すると、8個のベンチマークタスクでSOTAを達成しました。
ちなみに、機械翻訳など言語モデルのベースとなるエンコーダ・デコーダモデルについては以下を参考にしてください。

BERTの学習法と使い方
BERT の学習は、次の2段階から成り立ちます。
- 事前学習:大量のデータを用いる
- ファインチューニング:比較的少量のデータを用いて新しいタスクに適用する
そのうち、BERTの事前学習は、以下の2種のタスクを巨大なコーパスを用いて行います。
- Masked Language Model (MLM;空欄語予測)
* Next Sentence Prediction(NSP;隣接文予測)
MLMでは文章をトークンに分けた後に、一部(~15%)を「マスク」して隠した状態で入力し、マスクされた箇所のオリジナルの入力単語をモデルに予測させます。NSPでは2つの文を結合した状態で入力し、2つの文が連続する文かどうかのT/Fを予測させます。ここでは入力文章の合計系列長が512以下になるように2つの文章 をサンプリングしています。
BERTの訓練データには、BooksCorpus(800MB)と English Wikipedia(2500MB)を使用します。
BERTのモデルがどんなに大きいのか
2018年に提案されたBERTのパラメーター数は3億程度でした。計算コストを下げるために、パラメータ数を削減する工夫を施されました。2019年に、BERTの軽量版であるALBERTやDistilBERTが公開されました。実は、BERTのサイズは次回紹介するGPT-2, GPT-3に比べてはまだ比較的抑えられている方です。
他に、ロジックはBERTを参考にしている、MT-DNN(Multi-task deep Neural Networks)がMicrosoft社から発表されています。その性能はBERTを上回っていると言われています。
記事担当:ヤン・ジャクリン(分析官・講師)














