この記事では、従来の強化学習の延長上に研究が進められてきた深層強化学習について、従来の強化学習に対する改善点、技術の進化、課題などを述べていきます。
まず、「強化学習」についてはじめて学ぶ方のために、簡単に一言説明:
- 教師あり学習と教師なし学習と並んで、機械学習の3大分野の1つである
- 試行錯誤や探索を通じて、意思決定と行動最適化のルール、つまり「最終的に環境から最大の報酬をもらうために、どんな行動をとるべきか」を学習することが目的である
深層強化学習のはじまり
強化学習の研究は1990年代を中心に栄えていました。しかし、以下の難点にぶつかっていました。
- 「状態」の表現の仕方が難しい
- 状態に対して、現実的な時間内で行動を判断することが難しい
実世界での応用が困難と思われたため、強化学習の人気は、2000年代に一時期衰退してしまいました。
従来の強化学習では行動の組み合わせの全パターンを計算していたため、現実的な速度で課題に対応できないのが問題でした。この問題に対応すべく、深層強化学習が開発されました。深層強化学習は、ディープラーニングと強化学習を組み合わせた技術です。ディープラーニングを用いることによって、学習にとって本質的な部分を見つけ出しやすくなりました。そうすると、状態や行動の表現が改善され、強化学習の使い道がグッと広げられました。
代表的な手法は DQN(Deep Q-Network)
深層強化学習の圧倒的に代表的な手法は DeepMind社が開発したDQN(Deep Q-Network)です。DQNは、従来の強化学習モデルにおけるQ学習を基本的な思想としており、その上にCNNを取り入れています。
強化学習の学習法の基本: Q学習
DNQやQ学習には、Q値(状態行動価値)という用語が深く関連します。Q値とは、各状態においてエージェントがある行動を実行することで得られる報酬の期待値と解釈することができます。1つの状態と行動の組み合わせに対して1つのQ値が割り当てられます。新しい状態に遷移し別の行動を選択するたびにQ値が更新されます。Q学習というのは、Q値を最大にするように学習を行う手法です。
従来の強化学習では、「状態」を表現することや、状態の1つ1つに価値関数(Q値)を割り当てることが困難でした。例えば、囲碁で対戦するAIの場合、状態が碁盤の画像として与え、画像のピクセル値がわずかに変動しても別の状態と認識されてしまいます。ロボット制御などの複雑なタスクでは状態の組み合わせが膨大に膨らんでします。これに対して、深層強化学習は、行動価値や方策を推定するアプローチをディープラーニングに置き換え、状態を「そのままの形」(例:碁盤の画像)でCNNに入力することができます。DQNでは、状態と行動と報酬をまとめた「Qテーブル」に対し、ディープラーニングで回帰を施し、これを近似することで状態数が膨大になっても学習の時間が発散せずに済みます。
一般的にディープラーニングを含む機械学習では、サンプル間の相関は学習結果に悪影響を及ぼします。DQNの初期には、エージェントから得られるサンプル同士に強い相関があることが問題視されました。これへの解決策は、Experience Replay(経験再生)というテクニックです。サンプルのバッファーから一度に複数のサンプルを取り出してミニバッチ学習を行うという仕組みです。これによって, サンプル間の相関を軽減でき、DQNが上手くいくようになりました。
DQNの有名な活用事例
DQNのデビュー実績は、2013年にAtari社のブロック崩しゲームで人間のスコアを超え、反響を引き起こしたことです。その後2015-17年にDeepMind社開発の AlphaGo(アルファ碁)シリーズのモデルが世界トップの棋士を次々の打ち倒しました。その後、DQNをベースに多くの深層強化学習の改良版モデルが開発され、深層強化学習は今では難しいゲーム以外に、自動運転・ロボティクスにも活用されはじめています。
深層強化学習の技術の進歩
経験再生やネットワークの構造などを工夫することで、これまでに、DQNを拡張させた深層強化学習の手法が数多く開発されました。有名なものとして、ダブルDQN(Double DQN; DDQN)、デュエリングネットワーク(Dueling Network)、ノイジーネットワーク(Noisy Network)などが挙げられます。これらのアルゴリズムの良い特徴を組み合わせた「全部載せ」モデルが RAINBOWです。図1にあるように、Atariゲームを用いた試験においては、RAINBOWは他の全ての手法に勝るパフォーマンスを示しました。
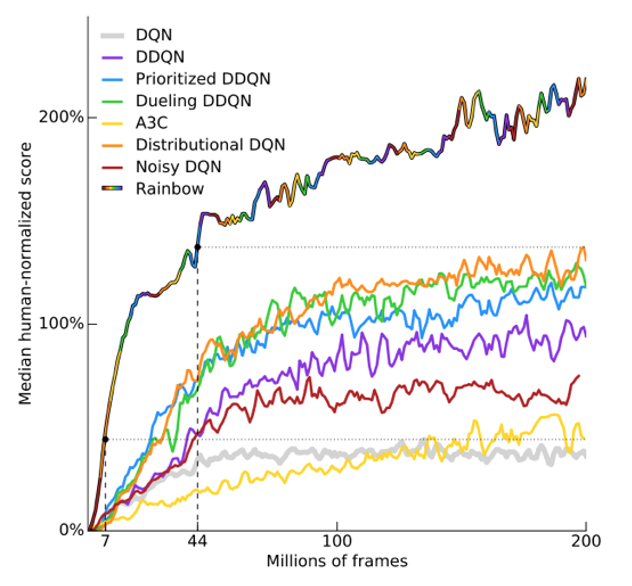
図1: Rainbowとそれを構成している手法について、ゲーム機Atari 2600のスコアを人間のスコアとの比をプロットしたもの。
次の記事では、DQNの活用事例、特に、AlphaGOシリーズのアルゴリズムの進化について述べていきたいと思います。
ここまで読んでいただきありがとうございました。それでは、次回またお会いしましょう。
記事担当:ヤン・ジャクリン(分析官・講師)
(追記)後続の記事では、DQNについてずっと後に開発され、計算の効率も性能も従来のアルゴリズムに優れるA3Cという深層強化学習のアルゴリズムについて書いています。
【5分講義・深層強化学習#4】A3Cの手法の中身と性能を理解