
DS検定によくでる標本抽出法、ここでは、「多段抽出法」と「層化抽出法」の違いを明確にします。学生時代の私自身も、この2つの概念をよく混同していたものです。
なぜ両者は混同されやすいのでしょうか。以下のような要因があると思われます。
- 多段抽出法の「段階」を層化抽出法の「層」と解釈してしまう
- 両者を併用することがある。
前提とする無作為抽出
標本調査では、調査対象である母集団の一部を調べるだけで、母集団の情報がつかめようとします。無作為抽出(ランダムサンプリング)とは、母集団から標本(サンプル)を無作為に抽出することです。「無作為」とは、恣意性をなくし、確率的に標本を抽出することを指します。無作為抽出を用いることで調査結果から恣意的なバイアスを防ぎやすくなります。
標本の件数が不十分では、母集団を代表する情報を正しく得られず標準誤差が大きくなります。 一方で、母集団のサイズが大きくなるほど必要な標本量も増えるため、調査のコストが高くなります。そこで、必要以上のコストをかけないために、標本誤差の目標を決めてそこから逆算して必要とする数の標本を抽出することが可能です。
無作為抽出のうち最も基本的な方法は単純無作為抽出であり、乱数を使って調査に必要な数になるまで無作為に対象を抽出する方法のことです。
ところで、単純無作為抽出が必ずしもベストの方法とは限りません。実際、「サンプリングバイアス」が発生しやすいです。
データバイアスについて、特に母集団から標本抽出を行う段階で生じる統計的偏りは、サンプリング・バイアスと呼ばれます。サンプリング・バイアスに気づかずにいると、母集団を代表していない、偏ったサンプルから結論を導き出すことになります。偶然ではない誤差である故に、系統誤差とも呼ばれます。
例えば、ある地域の住民から一定数の世帯をサンプリングし、対象世帯に対して「給食費を無償にしてほしいですか?」という意思調査を行ったとします。その際に、意外にも「食事の充実度が少しでも下がる可能性があるなら、有償のままでいてほしい」という声が半数も占めました。後ほどわかったのは、その地域から抽出したサンプルは偏っており、サンプル70%が世帯年収800万を超える世帯でした。それに対し、地域全体の平均世帯年収は450万でした。結局「富裕層の給食無償化への意見」しか得られていないことになります。
このように、地域性、収入、ジェンダー、文化、職業、年齢など母集団の属性に起因するバイアスが珍しくありません。
サンプリングバイアスへの対策として以下が考えられます。
- 事前にデータの偏りの有無を確認してから分析に進む
- 層化サンプリングを用いて標本データを集める
- 偏りを調整する手段として、アップサンプリング(データ数の少ないクラスを水増し)やダウンサンプリング(データ数の多いクラスを間引く)があるが、さらなるバイアスを加えないように調整を適切に行うように注意が必要です。
無作為抽出にはいくつかのバリエーションがあります。この記事の主題として、無作為抽出方に含まれる「多段抽出法」と「層化抽出法」の違いを正しく理解することです。
層化抽出法とは
層別抽出法/層化サンプリング(stratified sampling)は、母集団をあらかじめ複数の層に分け、各層の中から事前に決めた「必要な数」だけ対象を無作為抽出する手法です。
下図にあるように、データをあらかじめAとBのそれぞれの層に分け、AとBのそれぞれから母集団にある対象の数などに応じた適切な数を抽出します。
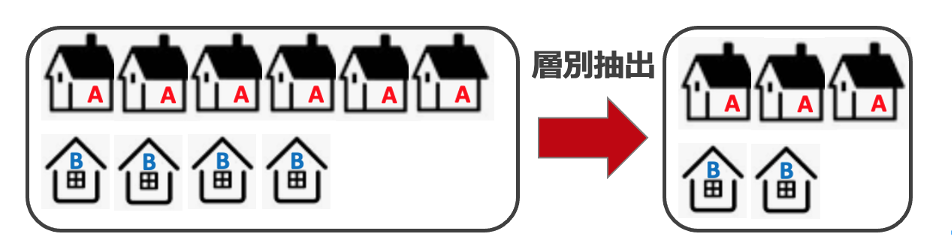
例えば、地区の企業の従業員を対象に行う調査で層化抽出法を採用するとします。企業を事前にいくつかの層に分けて、それぞれの層から従業員数に応じた数の対象者を無作為に抽出してアンケート調査を行います。
多段抽出法とは
多段抽出法とは、無作為抽出を複数の段階に分けて行う標本抽出法です。
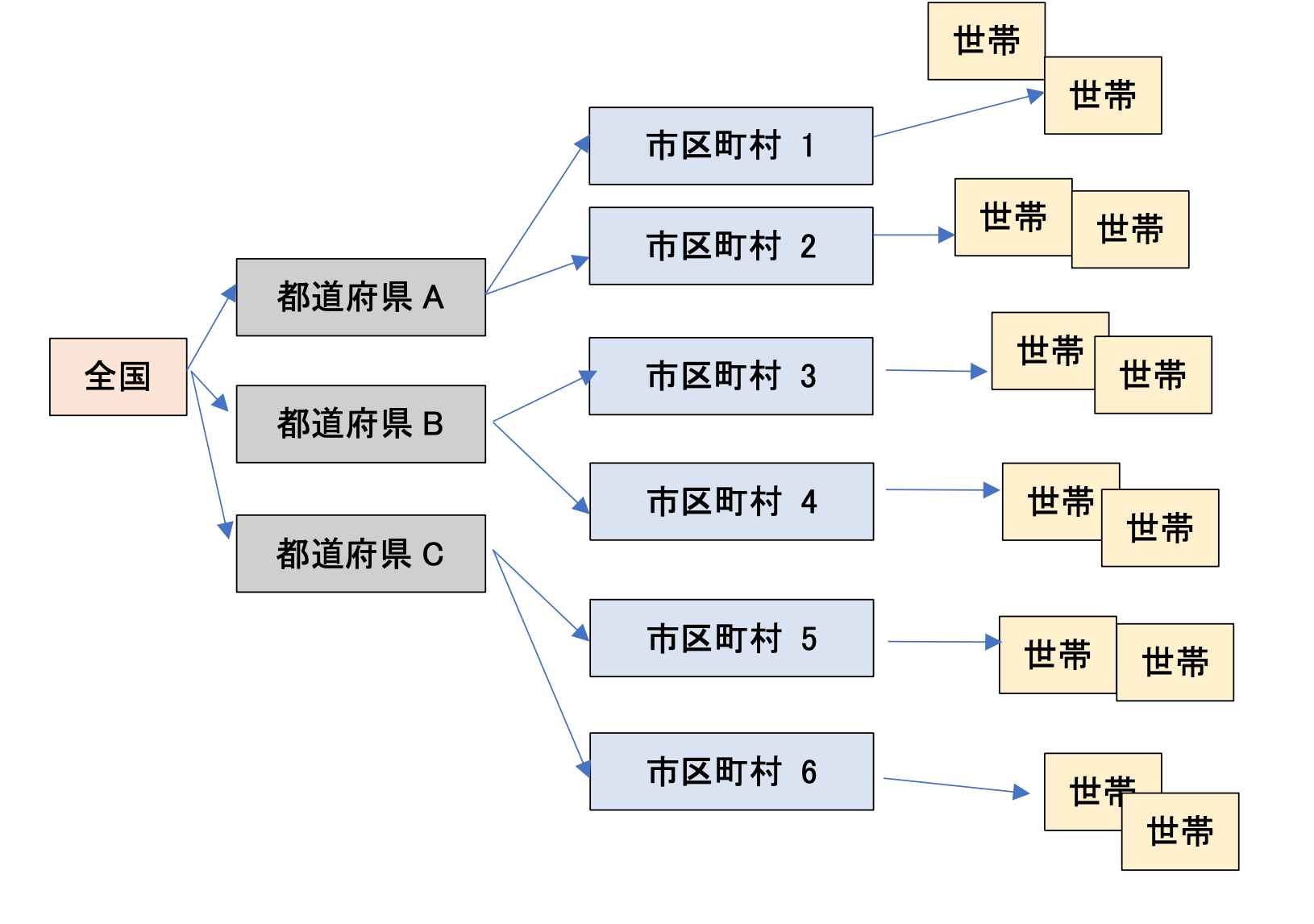
例えば、全都道府県の世帯をアンケート調査の対象とするには標本が大きすぎるとき、以下のような多段抽出法を実施することが考えられます。
第一段階で都道府県を10種類まで無作為で選び(第1段)、第二段階で各都道府県から市区町村を5種類無作為で選び(第2段)、最終的に各市区町村から100世帯を無作為で選び出して(第3段)、目的とするアンケート調査を実施する、というイメージです。この場合は三段抽出です。
上記が最もシンプルな多段抽出法ですが、より高度なオプションとしては、どこかの段では世帯数に応じた確率に比例して対象を無作為抽出する、比例配分法を取り入れることもあります。
多段抽出の段階数を多くすると、調査のコストを下げられるが、代わりに誤差が大きくなる傾向にあります。
層化抽出法と多段抽出法の違いと組み合わせ
上記で両者の性質を説明した上で、まずはっきりしたいのは、層化抽出法の「層」の部分は、「段階的に抽出する」の意味ではなく、抽出対象の属性ごとに、母集団に占める数の割合に合わせて、無作為抽出する数を決めることです、これが層化抽出法のポイントです。サンプリングバイアスを軽減することを目的とします。
これに対して、多段抽出法のポイントは、あくまでも、複数の段階で無作為抽出を行うことです。無作為サンプリングのコストを減らすことを目的とします。先に都道府県を無作為抽出してから、次に市区町村を無作為抽出し……というように。各段階で行う抽出が単純無作為抽出であってもよいですし、比例分配法を取り入れてもいいのです。
一方で、層化抽出法は、複数の段階で抽出を行う必要はありません。一段だけの抽出であっても、元の母集団のサイズを考慮した層ごとに行えば、層化抽出法です。
ただし、層化抽出法と多段抽出法を組みわせて標本抽出することがあります。これにより、単純な多段抽出法よりもサンプリングバイアスをやや抑える効果があります。
例えば、先程の例では、第一段階で都道府県を10つ無作為で選び(第1段)、第二段階で各都道府県の市区町村の全体数に応じた数だけ、市区町村を無作為で選び(第2段)、最終的に各市区町村から、世帯数に応じた数だけ、世帯を無作為で選び出す(第3段)、というふうにすると、多段層化抽出を行うことになります。
以上、本記事では、個人的にややこしいと感じた「多段抽出法」と「層化抽出法」の違いを説明しました。
執筆担当:ヤン ジャクリン (GRI分析官・講師)















