
以前の記事ではA3Cアルゴリズムを紹介しました。エージェントの非同期な学習を特徴とし、学習の高速化と安定化の効果があります。
今回この記事では、A3Cの学習法をさらに詳しく解説し、他の深層強化学習の手法と比べた性能をお伝えします。イメージとしてはA3Cの仕組みの全体像を把握し、原論文にも挑戦できるようになることです。
原論文:https://arxiv.org/pdf/1602.01783
A3Cの学習の仕組み
A3Cは分散型のActor-Criticネットワーク構造をしています。以下の2点を理解すればよいです。
* 一般的なActor-Criticでは、方策ネットワークと価値ネットワークを別々に定義し、別々のロス関数(方策勾配ロス/価値ロス)でネットワークを更新します。
* A3Cはパラメータ共有型のActor-Criticを持っています。1つの分岐型のネットワークが方策と価値の両方を出力し、たった1つの「トータルロス関数」でネットワークを更新します。
A3Cの学習に用いられるロス関数は3項目で表せます:アドバンテージ方策勾配、価値関数ロス、方策エントロピー
Total loss =− アドバンテージ方策勾配 +α・価値関数ロス −β・方策エントロピー
ここで、係数αとβはハイパーパラメータです。特に係数βは探索の度合いを調整するハイパーパラメータです。
一般的に、方策勾配法では、 θ をパラメータに持つ方策 πθ に従ったときの期待収益 ρθ が最大になるように、 θ を勾配法で最適化します。方策勾配定理により、パラメータの更新に用いられる勾配 ∇θ ρθ は、以下の式で表されます。

(式1)の中の Qπθ (s, a) − b(s) にアドバンテージ関数を設定します。A3Cの特徴としては、勾配を推定する際に、b(s)の推定には価値関数V πθ (s)、Q(s,a)の指定には、kステップ先読みした収益を用いることです(下式)。
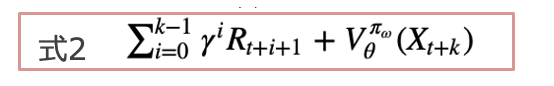
つまり、下記(式3)の期待値が(式1)の勾配と等価です。
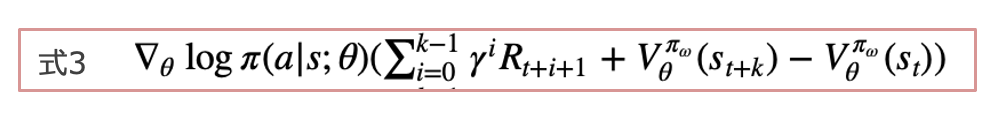
ちなみに、A3Cの方策エントロピー項からは、方策関数の正則化効果が期待できます。方策のランダム性の高い(=エントロピーが大きい)方策にボーナスを与えることで、方策の収束が早すぎて局所解に停滞する事態を防ぐ効果があることが知られています。
A3Cの性能
ここでは、A3Cの性能検証の結果を原論文から引用します。
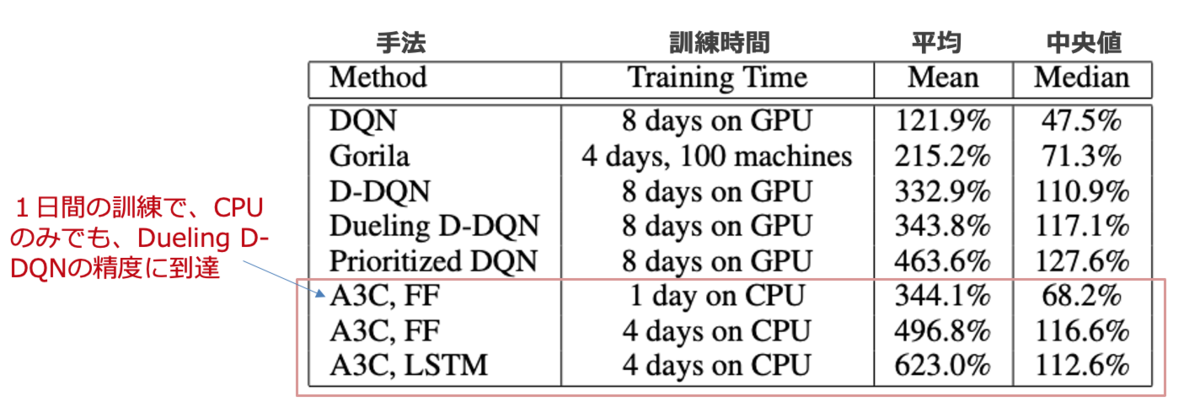
下図は、ゲームAtari 2600において、人間のスコアに対して規格化した深層強化学習モデルの結果です。A3Cは、16 CPUコアのみ使用、GPUを使用していないことに着目してください。また、訓練時間も1~4日間で、それまでの他の代表的なモデルより短いことが分かりますね。他のエージェントはNvidia K40 GPUを使用しており、ほとんどは8~10日間の訓練を要しています。結論をいうと、A3Cはより短い訓練時間でGPUを使わなくても、顕著に高いスコアを達成することができます。
A3Cの実装に挑戦したい方は、以下が参考になります(TensorFlow Blogより)。
https://blog.tensorflow.org/2018/07/deep-reinforcement-learning-keras-eager-execution.html
ここまで読んでいただきありがとうございました。それでは、次回またお会いしましょう。
記事担当:ヤン・ジャクリン(分析官・講師)















