
最近のG検定にはCycleGANがよく出る
2022年第1回目のG検定(2022.3.5)では以下のように出題傾向をコメントしました。
・汎用的な知識や仕組みを問う「良問」が多いこと → 安堵感
・法律問題(知的財産権、個人情報)
・流行:Grad-CAM、CycleGAN、DCGAN、MLOps
・最先端:DeepLab、Pix2Pix、AdaBound、二重降下現象
今回の記事ではCycleGANで何ができるのか、従来の技術と何が違うのかをなるべく難しい概念を使わずに解説します。アルゴリズムの詳しい仕組みに関しては、論文をご参照ください。
原論文:https://arxiv.org/abs/1703.10593
CycleGANとは
CycleGANとは、一言でいうと、画像のスタイル変換を得意とするディープラーニングモデルです。CycleGANは画像生成の著名なモデル GAN(敵対的生成ネットワーク)の一種です。
GANで何ができるかについては、以下の記事で面白く読んでいただけるかと思います。

スタイル変換とは、データの外見的特徴を変換することです。「画像から画像への翻訳」(Image-to-Image Translation)とも呼ばれます。
有名な例として、ゴッホの絵画をモネの画風に変換する事例が挙げられます。
CycleGANの有名な画像変換の例は、馬の画像からシマウマの画像への変換、およびその逆方向への変換のデモです。

出典:原論文
ここでは、多数の馬とシマウマの画像を用意し、それぞれの動物の特徴を把握した上で、相互に変換することが可能になっています。必要な学習データは生成したい2種類の物体の画像です(例:馬とシマウマ)。しかし、画像の中身に1対1のペアである必要はないことが大きいです。
他の技術との違い
CycleGANの画期的なポイントは、上述のように「変換したもの同士の画像が形や輪郭などが揃っていなくても、データの量さえ十分であれば、うまく変換できるモデルを訓練できる」ところです。
CycleGANの前に主流であったスタイル変換の手法は “pix2pix” です。
pix2pix の原論文:https://arxiv.org/abs/1611.07004
pix2pixは教師あり学習を使います。訓練データとして、2つの画像の輪郭がぴったりペアになっているものを大量に用意する必要があります。変換前のスタイルと変換したいスタイルの形状や位置が綺麗に揃っていることが必須であるため、データを集めることが非常に大変であることが想像できますね。そもそも自然界にそのようなペアが多く存在しません。
これに対して、CycleGANでは教師なし学習を使います。CycleGANのデータセットは形状や位置がバラバラであっても問題がありません。このように、pix2pixよりもずっと柔軟性が高いです。
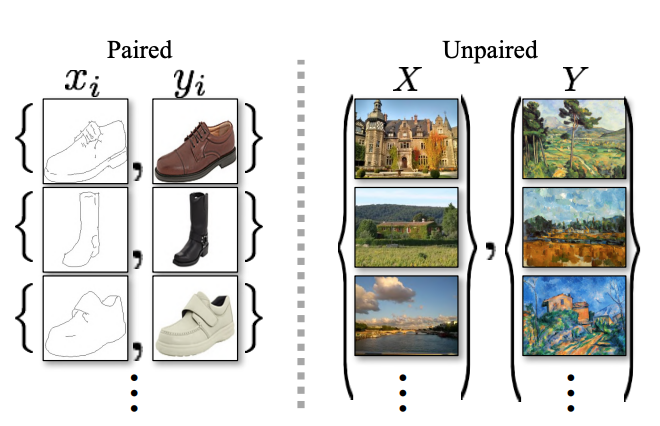
出典:原論文
左側がpix2pixで使われるデータ
右側がCycleGANで使われるデータ
CycleGANとpix2pixのもう1つの違いとしては、モデル訓練の効率です。
pix2pixでは「一方向」の生成ネットワークのみ訓練します。例えば、動物Aから動物Bへの変換のネットワークを訓練し、動物Bから動物Aへの逆変換を行うためには、新たなモデルを訓練しなければいけません。同じ膨大なデータセットを用いて訓練を二度もしなければいけないのは効率が良いとは言えませんね。
これに対して、CycleGANでは両方向の画像変換のために2つの生成ネットワークを同時に訓練することが可能です。
おすすめの参考図書
今回紹介したCycleGANは、敵対的生成ネットワーク(Generative Adversarial Networks; GAN)の一種です。
GANは本物と見分けられないような「偽物データ」を生成するモデルです。GANをはじめとする、ディープラーニングを用いた生成モデルについては以下の書籍で解説されています。
「ディープラーニングG検定(ジェネラリスト)最強の合格テキスト」(SBクリエイティブ)














