
どうも、最近家に帰ったら、弟がファンタジーアニメーションに出てくる魔法使いよろしく、鍋で丸太のような豚骨を煮込み自家製ラーメンを作っていた、分析官の岡部です。
(レシピはこちら)
本記事はMatillion for BigQueryのTipsです。
BigQueryユーザーの方以外はご容赦ください。
また、「先輩、Matillionってなんすか??」という方は以下の記事をご覧ください

それではいきましょう。
この記事の位置付け
実務でも頻出の、Google Analyticsデータを例にして説明していきます。
(他のデータでもノリは一緒かと思われます。)
そもそもですが、BigQueryのネストされたデータを扱うことに関する記事は、以下のように素晴らしいものがたくさんあります。
- BigQuery: Google Analytics 360のネストされたデータをフラット変換するSQL
- Google Analytics 360 + BigQueryでよく使うSQL例 6選
- Google Analytics 4 + BigQueryでよく使う基本的なSQL例
- GoogleAnalyticsのデータをBigQueryで分析する
ではこの記事はなんなのか?と聞かれますと、それはGUIでそれらunnestを実行することです。
そしてそれはMatillionで実現できます。(Appleのプレゼン風)
というのも、ただでさえ初見者ごろしのこのデータ構造。
ネストされたデータとか訳のわからないもの、できることなら触りたくないです。
理解したと思ってデータを触るもよく分からない、SQLで書くには時間がかかる……。
「あーもうやーめた」となること必須です。
とは言え、絶対にやめられない闘いがそこにはある。そんな時もあるでしょう。
そこでMatillionの出番です。いくつかの簡単なマウス操作だけで完結できます。
それでは実際に、Matillionでそれらunnestをどうやるのか見ていきましょう。
Matillionでunnestする
こちらの記事のようにGoogleAnalyticsのサンプルデータを使います。
- 自社のサービスサイトやコーポレートサイトの PVはどれくらいだろう?
- PVの増減に影響を与えている原因はなんだろう?
といったことが知りたくなること、あると思います。*1
というわけで、特定の日に絞ってサイトのPV数を算出していきましょう。
まずはデータを読み込みます。日ごとのPVなので、dateとhitsカラムだけを読み込みます。
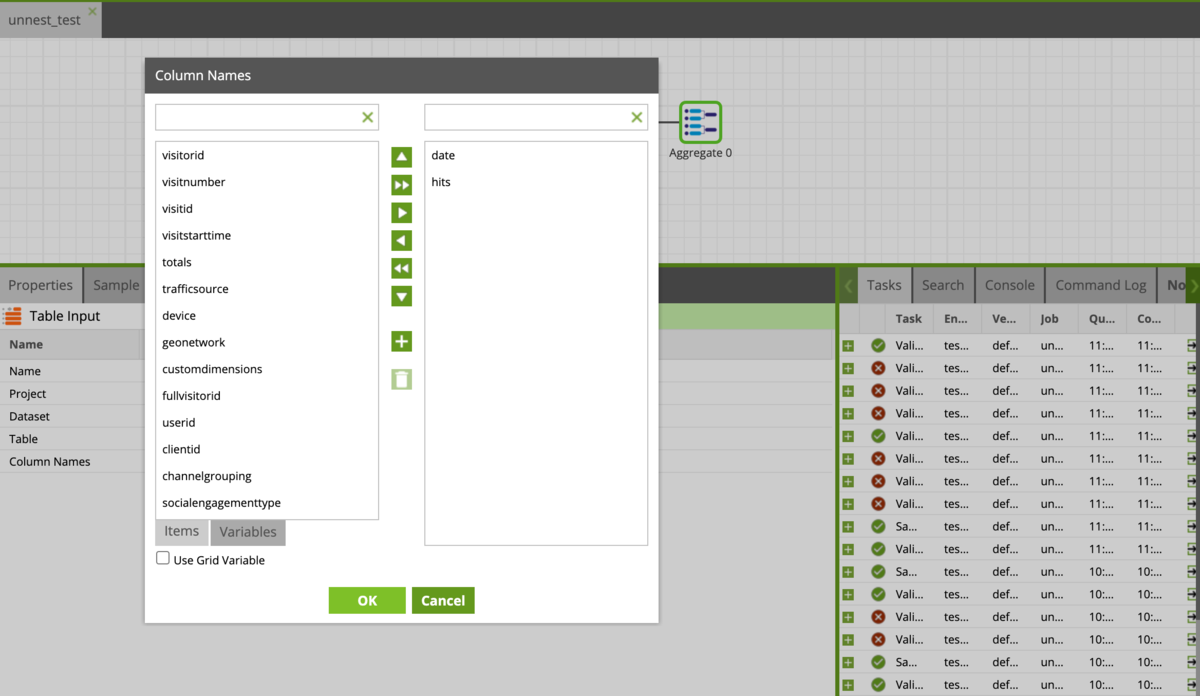
次に本題のunnestですが、
Semi-Structured DataのExtract Nested Dataコンポーネントを使います。
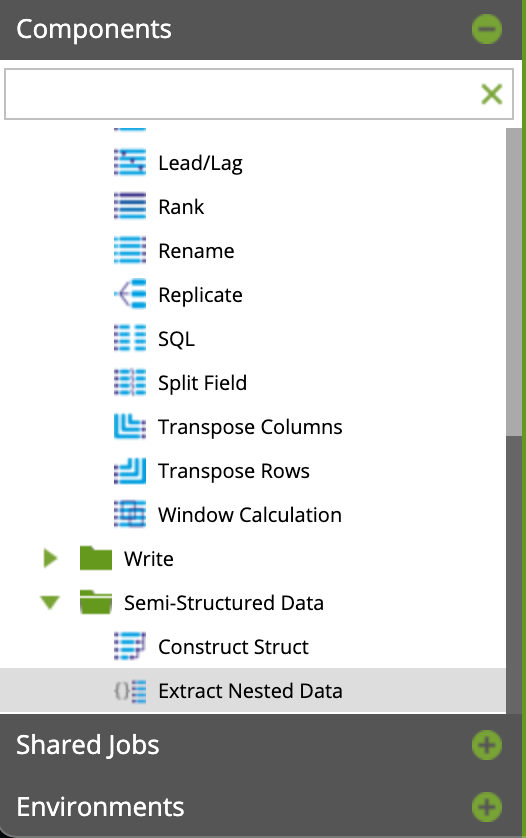
Input Tableコンポーネントに繋ぎ、Columnsを選択すると、
dateカラムとhits以下にネストされている大量のカラムがあることが確認できます。
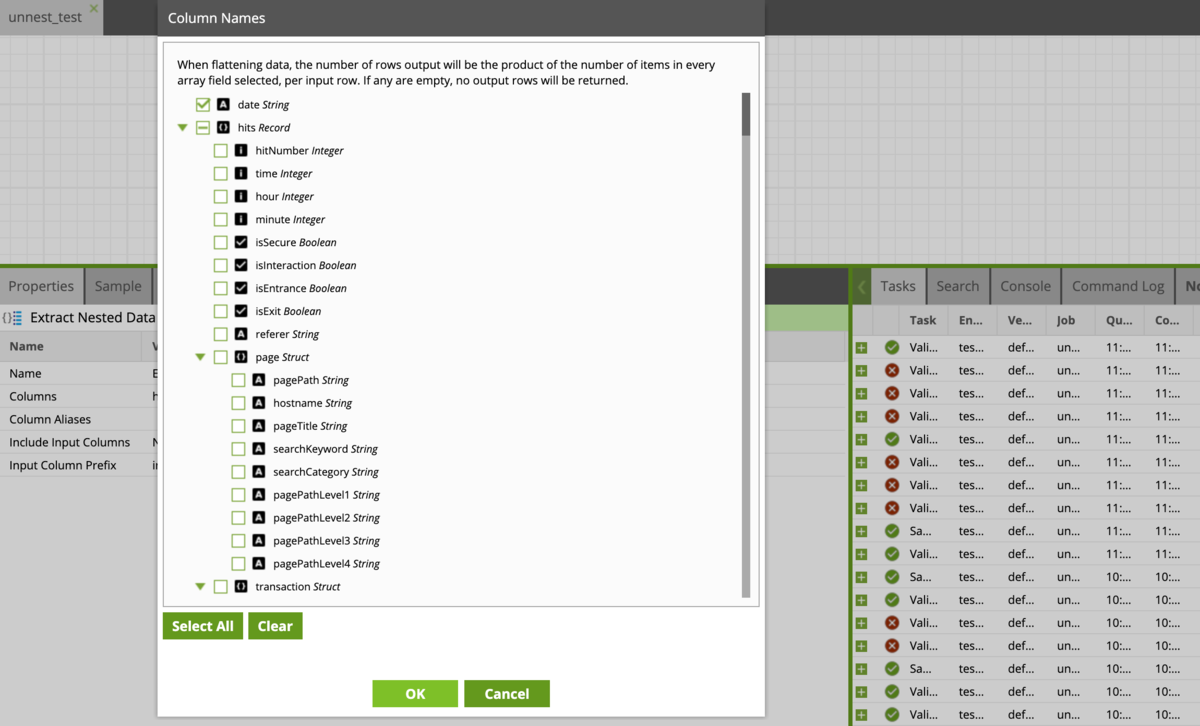
その中からdateとhits以下のtypeにチェックを入れてください(そこそこスクロールします)。
※詳細は割愛しますが、hits.typeはヒットの種類を表すものでして、
後ほどページビューに関するレコードのみを抽出する時に使用します。
データを見てみると、ちゃんとunnestされた形で格納されてます。
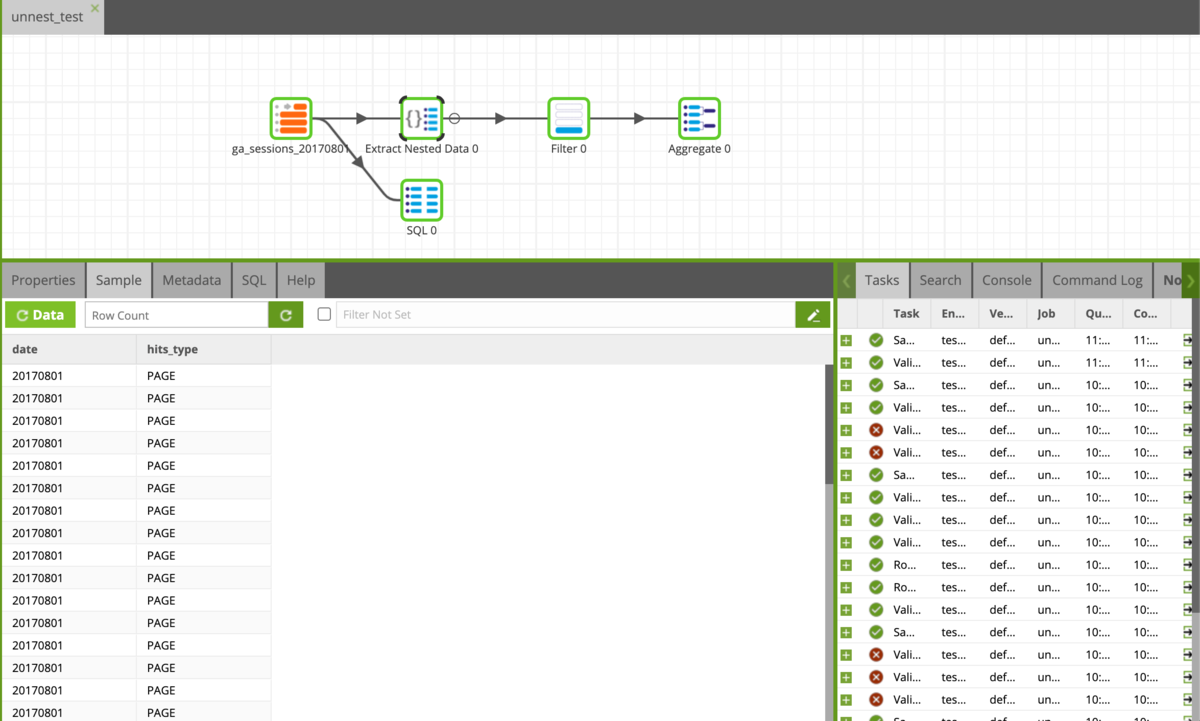
……unnest、これだけです。
もう本題終わりました。恐ろしく簡単ではないでしょうか?
あとはもう皆様のやりたいようにデータ整形していただければいいと思うのですが、
せっかくなので、最後までやっていきましょう。
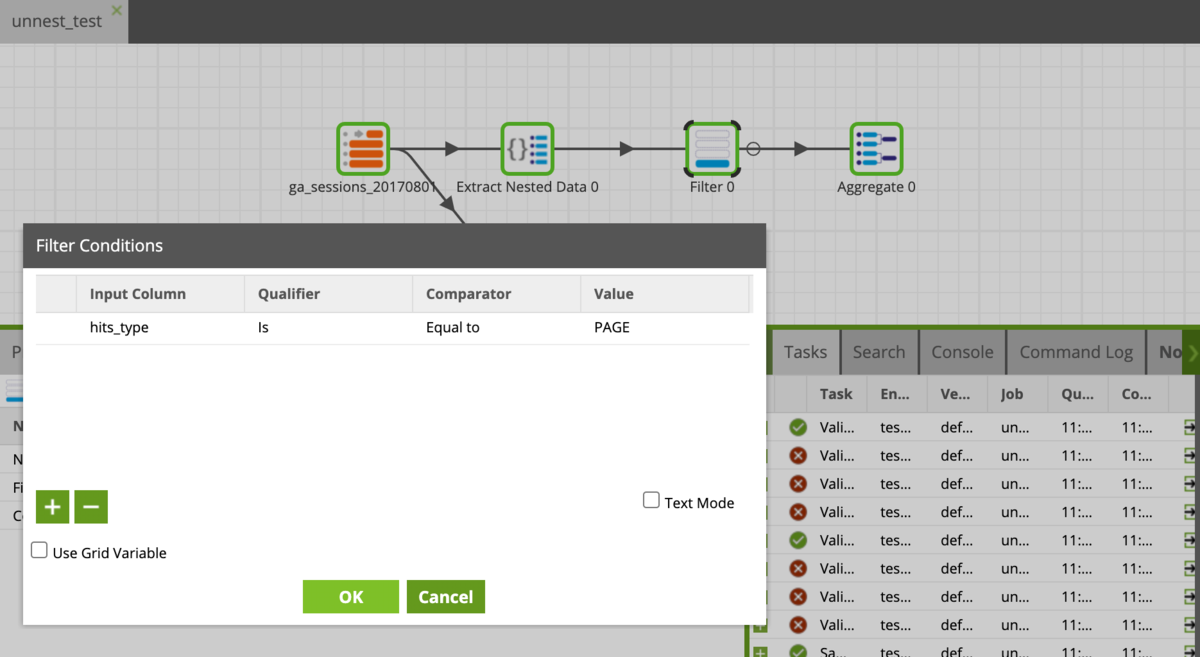
Filterコンポーネントでhits_typeがPAGEのものだけに絞ります。
これで1レコードが1PVに対応することになりました。
あとはこれを日ごと(とはいっても今は1日分のデータしか読んでないのですが……)に集計、レコードをカウントすれば、目的のPV数が算出できます。
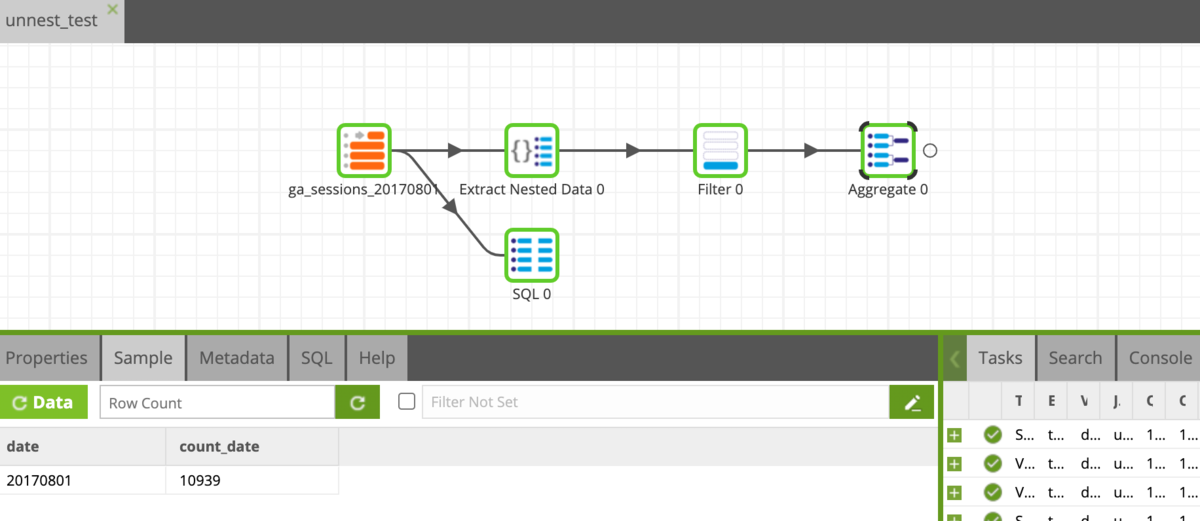
今の場合ですと
2017年8月1日は10,393PVがあったみたいですね〜
以上簡単ではありましたが、Matillionでunnsetをやるときの方法です。
今までネストされたデータになんとなく苦手意識を抱いていた方はぜひ試してみてください。
そしてプロSQLライター・Matillionマスターの方、怪しい部分がございましたら、ぜひそっとご指摘くださいませ。
それでは快適なMatillionライフを
おまけ:ネストデータを扱う上での注意点
BQは列指向ですので、列を増やすほどスキャン量は多くなります。
そして「とりあえずunnestしたカラム全部追加する」的なことをしていると、知らず知らずのうちにスキャン容量が多くなっていた、なんてことになりかねません。
厳密なチェックではありませんが、BQ上でスキャン量を簡単に確認してみましょう。
*で全ての列をスキャンした場合(15.9MB)

列をdateとhits_typeのみに絞った場合(104.7KB)
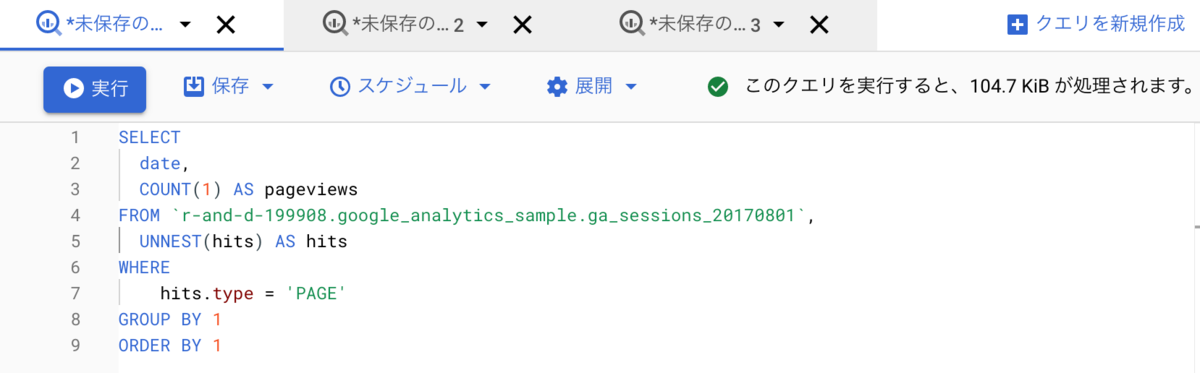
適切にカラムを選択することで、150倍以上もスキャン量を減らせていることがわかります。
今のサンプルデータ程度の量でしたら大丈夫かと思いますが、GB単位の大量のログデータを、しかも例えば100日分扱うとなると……いかに安価なBQといえど、そこそこの金額になることが予想されます。
余談ですが「もったいないからLIMIT 100にしとこう……」
これ実は全く意味がありません。
なぜなら、列ごとに全てのレコードを読み込んで一枚のテーブルにしたのち、それを100行だけ表示してるに過ぎないからです。
つまり、行方向のスキャンを減らすことはできないんですね〜

*1:「それくらいGAのレポート画面で見ればいいじゃん、BQにわざわざ入れる必要なくね?」という方、もっともでございます。ただ、そんな玄人の方であれば、GAのレポート画面で閲覧できる情報は、痒いところに手が届かなかったりすることもご存知でしょう。そんな時はやっぱり生データを自分で整形したくなることもあるかと思います。












