
データ分析官の時間を溶かす魔の二大巨頭が存在します。そう、「日時データ型」と「NULL」です。彼らは常にその機会をうかがい、隙あらば我々の時間を刈り取りにきます。むしろ命を刈り取る形をしています。
そのうち今回は、特にBigQueryで前者の日時データ型を扱うときの注意点をまとめておきます。備忘録です。
なぜ日時データ型は沼にハマりやすいのか
振り返って考えるに、自分がハマるパターンは大きく以下の4パターンの組み合わせで生じている気がします。
(1)タイムゾーンの存在
(2)date型やdatetime型、timestamp型など型が複数存在
(3)文字列型からのキャスト
(4)加算・減算の意味が二つある
(1)場所によって時計が示す時間は異なるため、「どこの時計が示している時間なのか?」を明確にしなければなりません。タイムゾーンと呼ばれるものです。例えば、東京がお昼12時の時、ロンドンは夜中の3時です。
従って、今見ているデータの時間はどこの時計が差しているものなのか?をはっきりさせておかないと、スーパーのお弁当が最も売れている時間が午前3時なんておかしなことになりかねません(東京の購買情報がロンドンの時刻で記録されていた場合)。
これはわかりやすくハマりやすいパターンだと言えます。ゆえに原因の究明もクリアで比較的気付きやすい・抜け出しやすいパターンでしょう。
(2)今回のメインテーマです。僕は普段pythonとSQL(BigQuery)を使っているのですが、両者とも日時を表すために複数のデータ型が存在します。これが危険になるのは(1)や(3)と合わさった時です。例えば、(1)との組み合わせで言うと、複数存在する型の中には、タイムゾーンの情報を持つものと持たないものが存在するため、両者を行き来する時にタイムゾーンの情報が抜けてしまう、もしくは勝手に付与されてしまうことがあります。恐ろしいことに見かけ上は似ているので注意していないと見抜けません。
(3)初めから日時を表すカラムとして適切な型で入っていればまだいいのです……。しかし、結構な頻度で奴らは文字列型としてカラムに入ってきます。なんなら日次の情報と時間の情報が異なるカラムとして入ってくるパターンもあります。
後続処理で文字列そのままに扱っていいのであればそれでも問題はありません。ただ日時カラムは、時間差を計算したり可視化の横軸に使ったりなど、明示的に系列の情報として扱いたい場合が大半でしょう。その場合はキャスト(型変換)してあげる必要があります。
その時に(2)で書いたような型の種別をしっかり理解しておかないと、東京の時間を意味しているカラムなのに勝手にロンドン時間にキャストされたりします。危険です。
(4)2つの意味、と言っているのは「特定の時刻からn時間前/後を計算」と「特定の2つの時刻間の差を計算」のことです(後者は減算のみですが)。これが(2)で説明した型ごとに違ったりするので、こんがらがった結果、どれだっけ?とググる回数が増えます。そして「python 時間 引き算」などの曖昧なセンテンスでググると型の数x上記2パターンの組み合わせの情報があふれ出てきます。すると、「あれ?時刻間の引き算をやりたいだけなんだけど、どれを信じればいいんだっけ??」などとなったりします。ちゃんと理解してたら一瞬なのですが、僕のような自称一級ハマリストにとっては死活問題です。
BigQueryの日時データ型:DATETIMEとTIMESTAMP
さて、では実際にBigQueryを触りつつ日時データ型に関する注意点をまとめていきましょう。BigQueryにはDATETIME型とTIMESTAMP型の二種類が用意されています。
DATETIME型の操作関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/datetime_functions
TIMESTAMP型の操作関数
https://cloud.google.com/bigquery/docs/reference/standard-sql/timestamp_functions
数多くのブログでも触れられていますが(例. BigQuery DATETIMEとTIMESTAMPの違い)最大の違いはタイムゾーンを持つか否かです。TIMESTAMP型はタイムゾーンの情報を持つ一方で、DATETIME型はタイムゾーンの情報を持ちません。
確認してみましょう。
以下のクエリでテストテーブルを作ります。
create or replace table `{MY_PROJECT}.{MY_DATASET}.dt_test` as (
select
'2021-01-01 00:00:00' as STRING,
datetime('2021-01-01 00:00:00') as DATETIME,
timestamp('2021-01-01 00:00:00') as TIMESTAMP,
)
スキーマ
プレビュー

確かにDATETIME型はタイムゾーンの情報を持たず、TIMESTAMP型はタイムゾーン付きで格納されていることがわかります。
一点注意点として、タイムゾーンが強制的にUTCとなります。後続で何をどうするかにも依存しますが、この点は認識しておいた方がいいでしょう。
例えば、このようなテーブルを定義書もなくチームメンバーに共有した場合、何も知らないそのメンバーが「ふぅ、やれやれUTCで入ってるよ、JSTにしなきゃな」と必要のない変換をしてしまうかもしれません。そうすると当然正しい時間とは9時間ズレてしまいます。
文字列からのキャストに関して
先ほどはしれっと流してしまいましたが、キャストに関しても少し確認しておきましょう。
文字列からキャストするやり方は3パターンほどあります。
(1)datetime()/timestamp()関数
(2)cast()関数
(3)parse_datetime()/parse_timestamp()関数
cast関数やdatetime()関数もformatを指定できるので、この指定を変えればあらゆる入力に関して変換可能かと思います。この辺りは公式ドキュメント(https://cloud.google.com/bigquery/docs/reference/standard-sql/conversion_functions#formatting_syntax)を参考にしつつチューニングしてください。
それでは実際に確認しましょう。(今回はDATETIME型に絞ってやりますが、TIMESTAMP型でも同様です。)
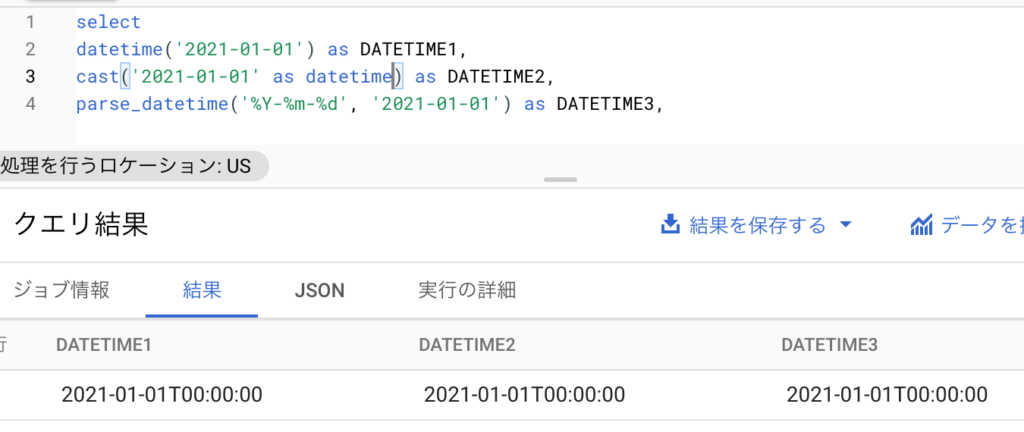
以下のようなクエリを叩くと
select
datetime('2021-01-01') as DATETIME1,
cast('2021-01-01' as datetime) as DATETIME2,
parse_datetime('%Y-%m-%d', '2021-01-01') as DATETIME3,
どれも適切にキャストできていることがわかります。
例外が入る可能性がある場合のキャストに関して
それなりのボリュームがあるデータに対して、上のような感じでキャストしてると、ほぼ間違いなくこけます。例外を処理できないからです。
例えばdatetime()関数だと以下のようにエラーを吐きます。
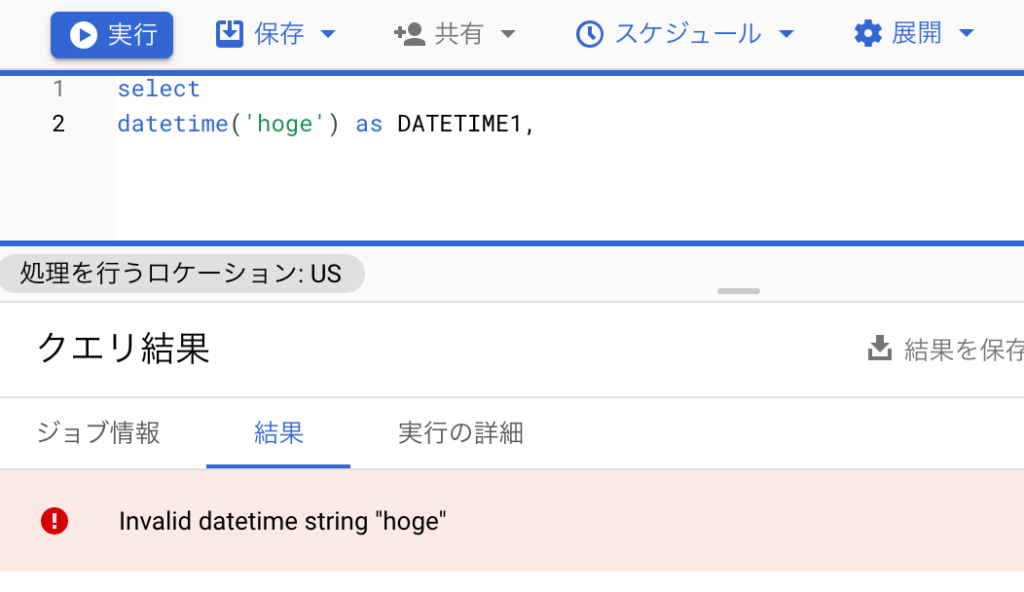
その場合以下の二つを使いましょう。というか初めからこちら推奨です。
(2)’ safe_cast()関数
(3)’ safe.parse_datetime()/safe.parse_timestamp()関数
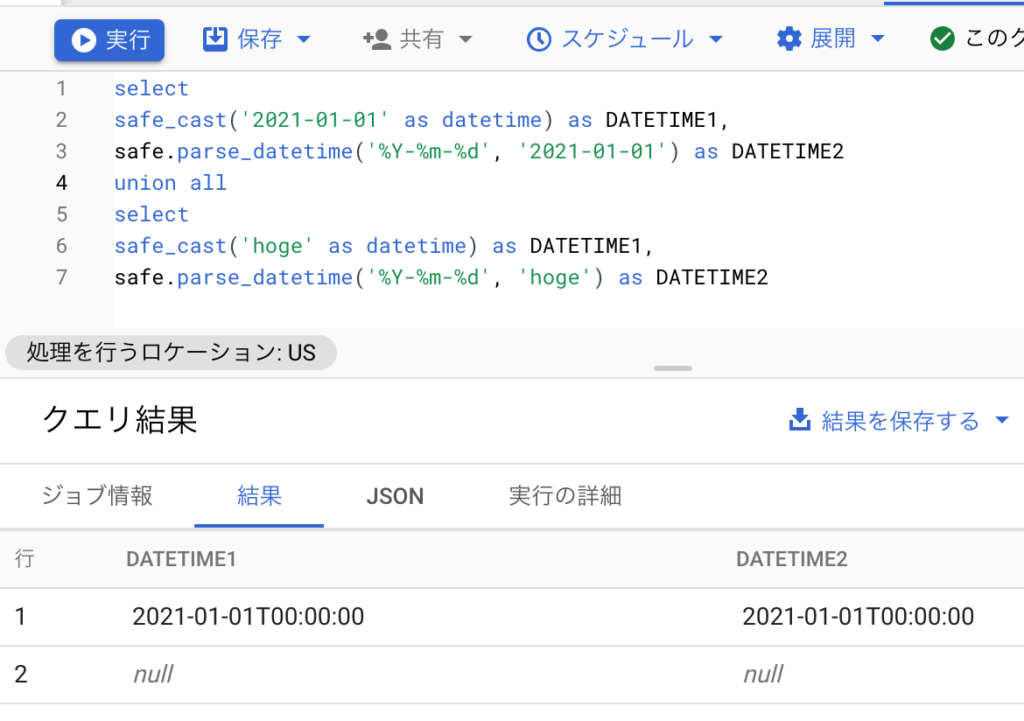
以下のようなクエリを叩くと
select
safe_cast('2021-01-01' as datetime) as DATETIME1,
safe.parse_datetime('%Y-%m-%d', '2021-01-01') as DATETIME2
union all
select
safe_cast('hoge' as datetime) as DATETIME1,
safe.parse_datetime('%Y-%m-%d', 'hoge') as DATETIME2
例外に関しては適切にnullになってることがわかります。
形式が揃っていない場合のキャスト
こんな感じのパターンですね。CASE文を書いて処理する感じになるでしょう……とデモを見せようかな〜と思ったのですが、やめました。これはもうデータ格納の時に揃えましょう。データを取り直せないなどの事情があるのであればしょうがないのですが(頑張ってください……)、こんな状態のままデータを持っていちゃダメです、ダメ絶対。
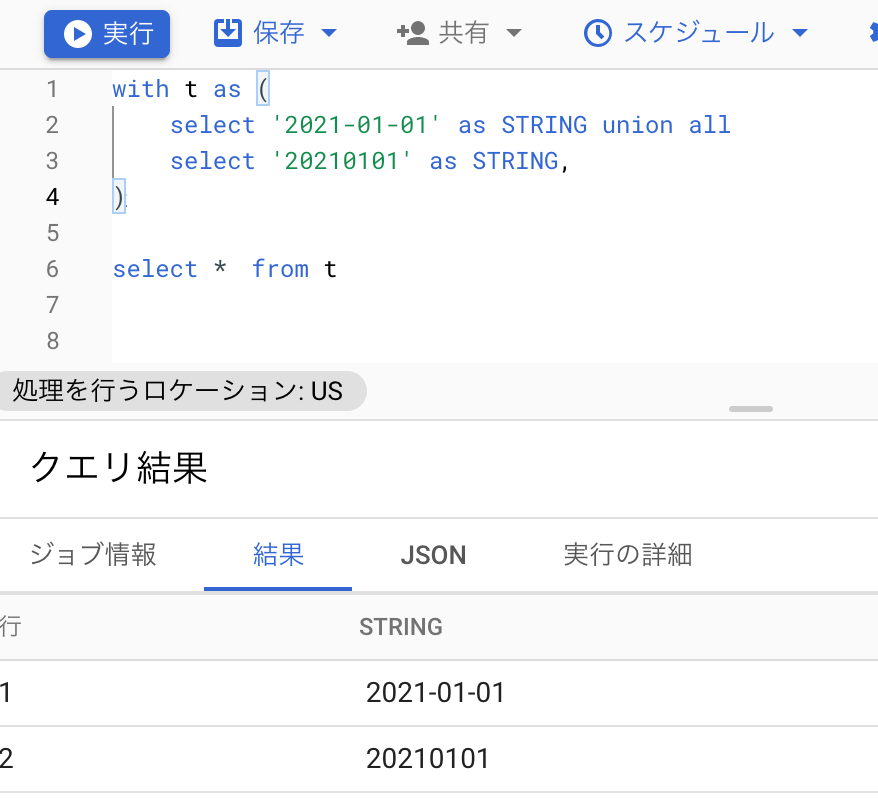
with t as (
select '2021-01-01' as STRING union all
select '20210101' as STRING,
)
select * from t
結論めいたこと
データ型というのは厄介なものです。人間が見る分には見た目は同じであるにも関わらず、適当にやっていると望んだ結果にならない。「所詮データ型でしょ?本質じゃないって」などと疎かにしていると、自分のような一級ハマリスト一直線です。この道は辿ってはいけない……(自分への戒め)
落ち着いて処理すれば確実にできることなので、落ち着きましょう。
例外があっても、データが大きくてスキャン量にビビっていても、落ち着きましょう。
また型はちゃんと意識しましょう。人間にとっては同じ見え方でも機械にとっては全く異なるものです。(自分への戒め)
そして、自分にとってはどんなに自明であっても定義書は残しましょう。タイムゾーンがどこなのか?型はなんなのか?分析しているとついつい疎かになりがちですが、長期的に見ると自分にとっても時間短縮につながります。なぜなら今の自分にとって自明であっても未来の自分は他人だからです。タイムゾーンなんだっけ?と確実に忘れます。(自分への戒め)
よりアドバンスな日時データ型のハマりポイント
個人的には
- 「25時」など日付を超えていても、(人間目線で)同一日付として扱う場合
がアドバンスかつよくあるかつハマりそうなポイントだなと思います。
気が向いたらこの辺のことも書きたいなと(書くとは言ってない)。
自分への戒めばかりであまり取り留めがないですが以上です。
どなたかの参考になれば。














