
TL;DR
- Streamlitはモックの作成に必要な最低限の機能を速攻つくれるPythonパッケージ
- Webアプリで頻出の選択ボックスやキャッシュ機能をかんたんに実装可能
- Streamlitで訓練済みモデルをうまくキャッシュする場合には、`allow_output_mutation`オプションを有効化しないといけなかった
Streamlit とは?
Streamlitは、分析結果などをインタラクティブに可視化するWebアプリをモック開発する場合に便利なPythonパッケージです。Webサーバーなどの知識が不要なので、開発者はコア機能のプロトタイピングに集中できます。
StreamlitでつくれるWebアプリのサンプルは公式サイトのギャラリーから見ることができます。例えば、地図データの可視化や波形の時系列プロットなど様々なシーンに活用可能なことにすぐに気づくと思います。
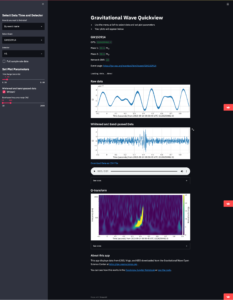
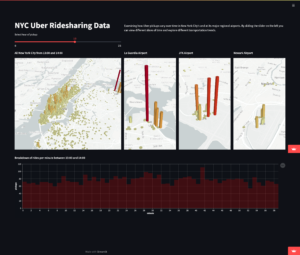
現状では、本番サービスとしてローンチするにはやや物足りないものの、その代わり、サービスのコンセプト実証実験やモック開発を手早くに達成できるので、使い所が分かっている開発者にとっては非常に強力なパッケージです。
Streamlitの便利機能の紹介
Streamlitでは、Webアプリだったらこういう機能が普通欲しいでしょ?というものを予めコンポーネントとして多数用意してくれているので、開発者はそれらコンポーネントに流し込むデータを定義し、レイアウトしていくだけでそれなりのWebアプリが作成できます。コンポーネントの例をいくつか挙げると、
- 配列リストから単一/複数の候補を選択するセレクトボックス
- ある機能をOn/Offするためのスイッチボタン
- Pandasデータフレームの表示機能
- matplotlibやseabornなどのグラフの表示機能
- 一度読み込んだデータをキャッシュしてリロードを高速化する機能
などがあります。
データの可視化でよく使うStreamlitの典型例
データの可視化でStreamlitを使う場合には、
- データを読み込み、キャッシュする
- データをフィルタ
- データを可視化
というのが良くあるパターンになります。
例えば、ダミーデータを生成してそれをテーブル形式で表示するアプリを作成してみましょう。具体的なソースコードは以下のようになります。
from datetime import datetime
import streamlit as st
import pandas as pd
from sklearn.datasets import make_classification
@st.cache
def make_dummy_data(n_samples: int = 10_000,
random_state: int = 42) -> pd.DataFrame:
x, y = make_classification(n_samples=n_samples,
random_state=random_state)
return pd.concat([pd.DataFrame(x), pd.DataFrame(y, columns=['target'])],
axis=1)
if __name__ == '__main__':
st.title('サンプルアプリ')
n_samples = st.number_input(label='生成データの行数', value=1000)
t0 = datetime.now()
df = make_dummy_data(n_samples)
t1 = datetime.now()
t_elapsed = (t1 - t0).total_seconds()
st.write(f'データ生成にかかった時間: {t_elapsed}秒')
cols = list(df.columns)
selected = st.multiselect('選択中のカラム', options=cols, default=cols)
st.write(df[selected].head(100))
この30行に満たないコードから、以下のようなWebアプリ画面ができあがります。
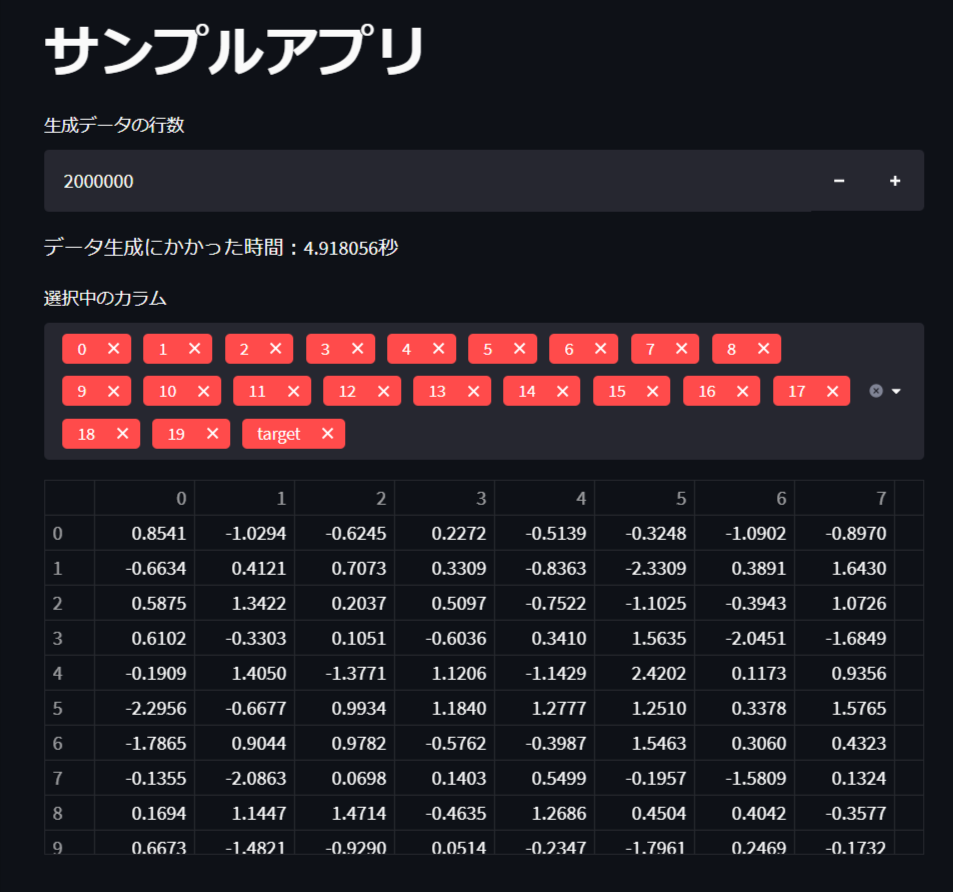
Streamlitを始める際に一番理解しておきたい標準仕様として、「アプリ中の一部コンポーネントの入出力に変更があった場合、すべての処理を頭から再度実行する」というものがあります。つまり、今回のアプリの例では、データの表示するカラムを変更すると、データの生成も含めて全て再実行されるということです。もちろん、これは冗長すぎるので、Streamlitのキャッシュ機能を適宜利用することで、ユーザーの待機時間を低減することが重要になります。
ソースコードの8行目に、st.cache というデコレータがあることに注目してください。Streamlitでは、たった1行を関数の直前に記述するだけで、キャッシュ機能を利用することが可能になります。とても便利ですね!
訓練済みの機械学習モデルをStreamlitでデプロイする場合の典型例
この記事の主題である、訓練済みの機械学習モデルに推論させるためのWebアプリをStreamlitでデプロイする場合について説明します。当該シナリオの場合には、
- 訓練済みモデルを読み込み、キャッシュする
- 推論用の特徴量データを入力
- 推論結果を表示
という流れが一般的です。ソースコードのテンプレートとしては、以下のようになります。
import pickle
import streamlit as st
import pandas as pd
from sklearn.datasets import make_classification
@st.cache(allow_output_mutation=True)
def load_model():
with open('model.pkl', 'rb') as f:
return pickle.load(f)
@st.cache
def make_dummy_data(n_samples: int = 10_000,
random_state: int = 42) -> pd.DataFrame:
x, _ = make_classification(n_samples=n_samples,
random_state=random_state)
return pd.DataFrame(x)
if __name__ == '__main__':
st.title('訓練済みモデルのデプロイ')
model = load_model()
n_samples = st.number_input(label='生成データの行数', value=1000)
x_pred = make_dummy_data(n_samples)
y_pred = model.predict_proba(x_pred)
st.write('推論結果')
st.write(y_pred)
このソースコードの8行目に注目してください。Streamlitで機械学習モデルをロードしキャッシュを効かせるためには、allow_output_mutationというオプションをTrueにする必要がありました。Streamlitではキャッシュするデータオブジェクトは原則immutable(変更不可/しない)なデータとして扱われますが、推論結果を出力するプロセスでモデルオブジェクトがどこかで変更されてしまい、Streamlit上では正常にキャッシュされないという事象が発生するようです。(scikit-learnのランダムフォレストでも当事象は確認されましたが、具体的にどのソースコード部分で変更されるかまでは特定できませんでした。)
最後に
データサイエンティストにとって、自分の仕事の成果や価値を最大限にプレゼンすることは超重要です。今回紹介したStreamlitを利用することで、パワーポイントよりもインタラクティブなプレゼンが可能になります。どんどんモックをつくって、いち早くクライアントや市場から良質なフィードバックをゲットしちゃいましょう。
今回の記事で利用したパッケージのバージョン
pandas==1.3.5
scikit-learn==1.0.1
streamlit==1.3.0















