
はじめに
国勢調査のシェープファイルは全都道府県合わせると数GBととても容量の大きいファイルとなってしまいます。
これにより、表示の際に時間がかかってしまったり、表示できなかったりします(実際、データポータルは頂点数100万までしか表示できない仕様でした)。
そこでシェープファイルを軽量化し、レンダリングを高速にする手法について紹介します。
軽量化手法
geopandas
頂点の始点と終点を結び、ほかの座標から許容距離外のものを除外する手法です。
位置は保持され、頂点の数が減ります。
topojson
トポロジーの概念を用いて頂点の数を減らす手法です。
具体的には各ポリゴン間の共有されている座標を認識し、接続関係を考慮しながら除外します。
実験
各手法で神奈川県の郵便番号界ポリゴンを軽量化したものは以下の通りとなりました。
| パラメータ(許容距離) | geopandas | topojson |
|---|---|---|
| 元データ |
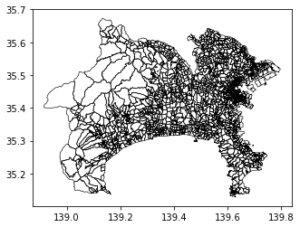 |
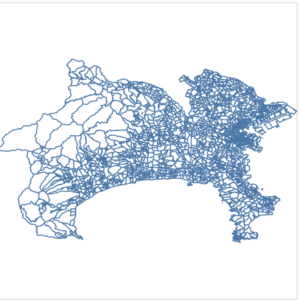 |
| 0.001 | 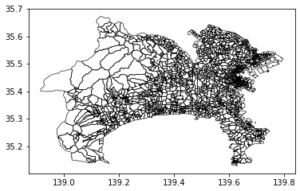 |
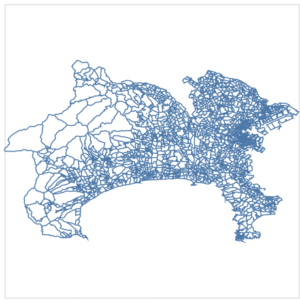 |
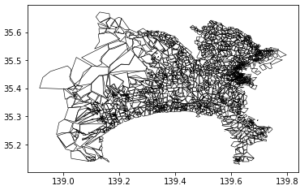
| 0.01 |
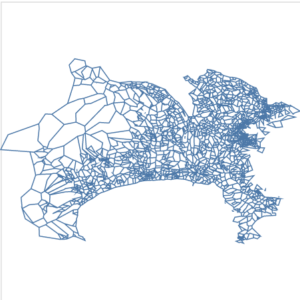
 |
 |
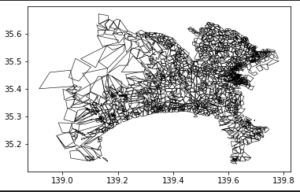
| 0.1 |
 |
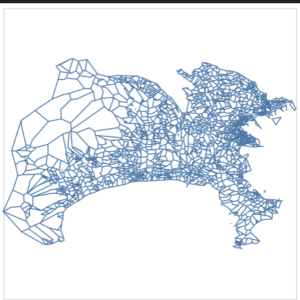 |
それぞれ簡略化はできていますが、geopandasを用いた場合、独立して簡略化され、topojsonの場合、元の位置からずれるポリゴンもできています。
topojsonでパラメータ0.01の場合、全都道府県でおよそ1~6%程度の頂点数まで削減することができ、レンダリングも高速になります。
ちなみに
神奈川県では比較的ポリゴンも大きいですが、北海道札幌市や京都府など、粒度がとても細かい地域の場合、大きな差が生じています。
また、それぞれ相互に変換が可能なので比較的使いやすい印象です。
geopandas

topojson
















