
以前の記事では、AIの定義とAIのレベルについて論じました。
gri-blog.hatenablog.com
続いて、AIと深く関連する概念を整理しましょう。
- AIと機械学習の関係性
- 機械学習とディープラーニングの関係
これらの本質を正しく理解することが、人工知能の歴史や技術動向を把握する上で極めて重要です。この記事では、まず、1.のAIと機械学習の関係性について議論したいと思います。将来の記事では2.のディープラーニングの位置付けについて書きます。
機械学習の定義と特徴
最初に機械学習を定義づけたのは、学習型プログラムを初めて開発したアメリカの計算機科学者のアーサー・サミュエル(Author Samuel)です。サミュエル氏による機械学習の定義は以下です。
“明示的にプログラムしなくても学習する能力をコンピュータに与える研究分野”
上記で、「明示的にプログラムしなくても」の部分が一番重要です。これはどういうことだと思いますか?
先ほどの「人工知能と機械学習はどのような関係にあるのか」に対する答えは、図1にあります。端的に答えると、機械学習は人工知能の中の一つの手法です。つまり、機械学習は人工知能の部分集合として考えることができます。
人工知能は、ルールベースの手法と機械学習の手法に分けることができます。
■ルールベース
人間があらかじめ設定した動作ルールに従って行動する仕組みのことです。ある条件Aの下で、Bという入力データが入ってきたら、Cという出力を出しなさい、のような一連の命令が事前に決められており、AIはそれに忠実に従って出力を出すだけです。
■機械学習
大量な学習データをもとに、汎用的なルールやパターンを、学習というプロセスを介して導き出す手法です。ここでは「学習データを用いていること」と「学習のプロセスが絡むこと」が大事な要素です。「汎用的」というのは、学習済みモデルを、新しい未知のデータに対する予測に使用し、その精度がある程度担保されているということです。

図1:人工知能と機械学習の関係性
機械学習は人工知能の中で、効率的かつ効果的にコンピュータが学習を行うことを可能にした技術であり、今では様々な分野で応用されています。
コンピュータがより「人間らしい」認識能力・判断能力を持たせるためには、振る舞いの基準を定める必要があります。例えば、年収によってクレジットカードの審査が通るかどうかを判定するコンピュータプログラムでは、「年収」もしくは「年収の最低値」がその基準にあたります。ルールベース手法では、基準やその閾値を人間が指定する必要があるが、機械学習では、最も的確な振る舞いをする基準を自動的に見出すことができます。その基準のことを計算機科学では「パラメータ」と呼ぶことがあります。パラメータの最適値を見出すことがまさに機械学習における「学習」です。
2000年に入ってから、インターネットの普及により、データが流通・収集・蓄積しやすくなりました。いわゆるビッグデータの時代となりました。膨大な量のデータ(=ビッグデータ)を学習に使用できるようになると、今まで以上に汎用的なパターン・法則を見つけることができ、未知のデータに対しても答えを出すことが可能になりました。
(注)一般的に予測対象の新しいデータは学習データと同種類のデータあるいは似たような分布に従っていることが前提です。
(注)ビッグデータの現代においても、必ずしも全ての機械学習がビッグデータを必要とするとは限りません。
学習と予測
機械学習における「学習」と「予測」とはどういうことなのかをもっと具体的に見ていきましょう。機械学習では、①コンピュータが入力データを受け取り、モデルを学習(訓練)させます。その後、②学習済みモデルを使って計算結果を出力します。①「学習」と②「予測」の様子はそれぞれ図2と図3に現れています。
図2を、簡単のために機械学習の中の最も広く使われる「教師あり機械学習」を使って説明します。教師あり学習では、特徴量(学習データの特徴を表す変数、つまり予測の手掛かりの集合体)と正解データ(教師ラベルとも呼ぶ)の2点セットをコンピュータに入力します。コンピュータの中では、特徴量と正解を関連づける法則を探ります。結果として「このような特徴の組み合わせを持つ時はこのような出力を出すのが正解のだ」のようなパターンを発見します。このパターンを習得してあるシステムが「モデル」と呼び、特に学習のプロセスを終えたモデルは「学習済みモデル」と呼びます。学習済みモデルでは、ある未知のデータが入力されると、獲得した法則に基づいて適切な意思決定を支援するための答えを出力できます。まさに人工の脳のイメージです。
一般的にはモデルを正式に社会やビジネスに実装する前に、テストデータなどを用いてモデルの精度を検証する必要があります。精度が不足している場合は、データ収集の方法、学習データの構成、モデルの種類や詳細設定などを修正する必要があります。試行錯誤を繰り返し行うことで、自信をもって「汎用的」言えるモデルに辿り着きます。
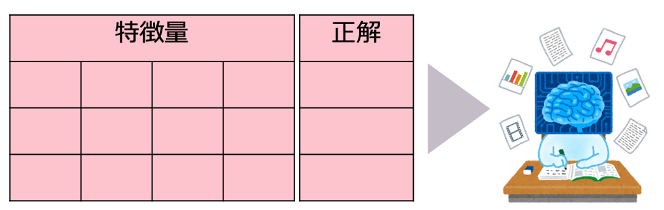
図2:教師あり機械学習における「学習」の概念図
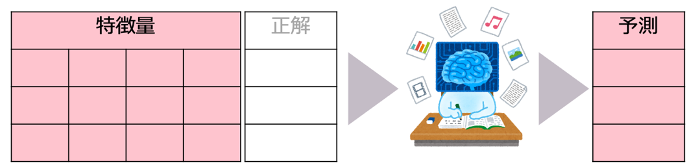
図3:教師あり機械学習における「予測」の概念図
来の記事では、以下の関連することについて論じる予定です。楽しみにしていただけたら幸いです。
- ディープラーニングと機械学習の関係
- 機械学習の手法の種類(教師あり、教師なし、半教師あり、強化学習)
- 機械学習における精度検証の仕組み
- 特徴量とは?
- 特徴量設計の大変さ
それでは、次回にまたお会いしましょう。
担当者:
分析官・講師
ヤン・ジャクリン














