
機械学習というと、膨大なリソースと大量のデータを用いた分析、というイメージが強いかもしれません。事実、弊社の自動機械学習ツール ForecastFlow も、クラウド上の豊富なリソースによって内部で複雑なモデルを構築しています。
しかし、分析の初期段階では軽量でシンプルなモデルを試してみることも必要です。「Python お手軽機械学習」では、そのような手法のいくつかを紹介していきます。
※[Python お手軽機械学習 1] の続編です。
この記事でやること
- 分類問題を解く機械学習手法であるSVMおよびカーネルSVMについて説明し、前回暑かったロジスティック回帰との比較を行います。
- Python 上での実装方法を説明します。
SVM/カーネルSVMとは
SVM(サポートベクターマシン)は、ロジスティック回帰と同様に分類問題(各データがどのグループに属するか)を解くための機械学習モデルです。カーネルSVMは後述しますが、カーネルを用いることでSVMよりも高度な分類ができます。できることおよび手順はロジスティック回帰と同じなので[こちらの記事]を参考にしてください。今回も簡単のため、2値分類(ターゲットのグループが2つの場合)を考えます。
ロジスティック回帰との違い
SVMを図示したものが以下です。訓練データとして青の点と緑の点があったときに、その境界として最も適切な位置に直線を引いてくれるようなイメージです。
SVMでは直線しか引くことができないため曲線で分割したい問題では精度が落ちてしまいます。そのような問題に対してはカーネルSVMを用いることで次元を増やし、実質的に曲線で分割するような処理が可能となります。これにより多くの問題ではロジスティック回帰よりも高い精度が得られるようになります。
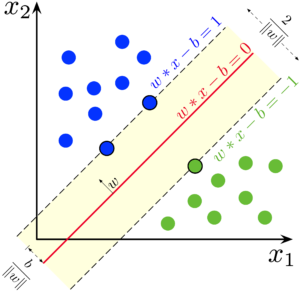 SVM の説明図(Wikipediaより引用)
SVM の説明図(Wikipediaより引用)Larhmam, CC 表示-継承 4.0, リンクによる
Python 上での実装
カーネルSVMをPython上で実行するコード例は以下です(参考: sklearn.svm.SVC)。RBF(Radial Basis Function: 放射基底関数)と呼ばれるカーネルを用いて曲線的な分離を行なっています。
学習対象はロジスティック回帰の時と同じBreast Cancerデータセットです。実は前回のロジスティック回帰との違いは2行しかありません。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
## Breast Cancerデータセットの取得
data = load_breast_cancer()
## 特徴量をDataframeに読み込み
df = pd.DataFrame(data['data'], columns=data['feature_names'])
## ターゲットの読み込み(既に0と1に変換されている)
df['TARGET'] = data['target']
## 訓練データと予測データへの分割
train_df, pred_df = train_test_split(df, train_size=0.7, random_state=111, stratify=df['TARGET'])
## 学習に必要なインスタンスの読み込み
sc = StandardScaler()
model = SVC(kernel='rbf')
## 学習
model.fit(sc.fit_transform(train_df[data['feature_names']]), train_df['TARGET'])
## 予測
output = model.predict(sc.fit_transform(pred_df[data['feature_names']]))
pred_df.loc[:, 'PRED_TARGET'] = output
## 正解率(予測が合っていた割合)を算出
accuracy = len(pred_df.query('TARGET == PRED_TARGET'))/len(pred_df)
print(f'Accuracy: {accuracy}')
# Accuracy: 0.9824561403508771最後の結果から、予測データにおいて 98% 程度の正解率で当てられることがわかり、96% だったロジスティック回帰よりも高い精度が得られていることがわかります。
















