機械学習というと、膨大なリソースと大量のデータを用いた分析、というイメージが強いかもしれません。事実、弊社の自動機械学習ツール ForecastFlow も、クラウド上の豊富なリソースによって内部で複雑なモデルを構築しています。
しかし、分析の初期段階では軽量でシンプルなモデルを試してみることも必要です。「Python お手軽機械学習」では、そのような手法のいくつかを紹介していきます。
この記事でやること
- 分類問題を解く機械学習の中でも特にシンプルなロジスティック回帰について、機械学習の初心者向けに説明します。
- Python 上での実装方法を説明します。
ロジスティック回帰とは
ロジスティック回帰とは、分類問題(各データがどのグループに属するか)を解くための機械学習モデルです。以下では簡単のため、2値分類(ターゲットのグループが2つの場合)について説明します。
ロジスティック回帰でできること
ターゲットが既知の訓練データを学習させることで、ターゲットが未知の予測データでターゲットを予測することができます。ちなみに以下のデータは Breast Cancer と呼ばれる乳癌検診の結果になり、ターゲットの benign, malignant はそれぞれ良性、悪性を意味しているようです。
| ID | mean radius | mean texture | mean perimeter | mean area | mean smoothness | … | TARGET |
| 1 | 11.99 | 24.89 | 77.61 | 441.3 | 0.103 | … | benign |
| 2 | 19.4 | 18.18 | 127.2 | 1145 | 0.1037 | … | malignant |
| 3 | 13.66 | 15.15 | 88.27 | 580.6 | 0.08268 | … | benign |
| 4 | 23.21 | 26.97 | 153.5 | 1670 | 0.09509 | … | malignant |
| 5 | 19.21 | 18.57 | 125.5 | 1152 | 0.1053 | … | malignant |
↑訓練データ
| ID | mean radius | mean texture | mean perimeter | mean area | mean smoothness | … | TARGET |
| 101 | 12.3 | 15.9 | 78.83 | 463.7 | 0.0808 | … | ? |
| 102 | 14.45 | 20.22 | 94.49 | 642.7 | 0.09872 | … | ? |
| 103 | 11.71 | 16.67 | 74.72 | 423.6 | 0.1051 | … | ? |
| 104 | 12.72 | 17.67 | 80.98 | 501.3 | 0.07896 | … | ? |
| 105 | 19.55 | 23.21 | 128.9 | 1174 | 0.101 | … | ? |
↑予測データ
ロジスティック回帰の手順
ロジスティック回帰の手順としては、大きく学習→予測の2段階があります。
学習は、訓練データに合わせて以下のグラフで表されるロジスティック回帰モデルをフィットさせていきます。上記の表で言うと、TARGET 以外の列の情報(特徴量)の値に応じてTARGETのどちら側になりやすいかの傾向を見ているようなイメージです。ターゲットは2種類それぞれを 0, 1 の数値に変換し、0 のグループのデータでは 0、1 のグループのデータは 1 と出力するようにモデルを最適化していきます。
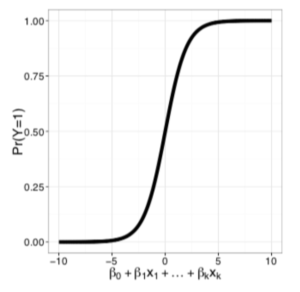 ロジスティック回帰で用いられるグラフ
ロジスティック回帰で用いられるグラフ
与えられたデータの特徴をもとにして計算を行い、0~1 の範囲の値を得ます。基本的にはどのデータも「ほぼ0」か「ほぼ1」の値となり、どちらのグループに属するかが分かる、というわけです。
Python 上での実装
ロジスティック回帰をPython上で実行するコード例は以下です。Scikit-learn と呼ばれるライブラリを用いることで、Breast Cancerデータセットの読み込みや、本来内部で複雑な計算が行われているロジスティック回帰を簡潔に記述できます。
(参考: sklearn.linear_model.LogisticRegression)
このコードでは、学習に際してデータセットのPandas DataFrameへの変換や特徴量の正規化などが使われていますが、その辺りの説明はまた別の機会とします。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
## Breast Cancerデータセットの取得
data = load_breast_cancer()
## 特徴量をDataframeに読み込み
df = pd.DataFrame(data['data'], columns=data['feature_names'])
## ターゲットの読み込み(既に0と1に変換されている)
df['TARGET'] = data['target']
## 訓練データと予測データへの分割
train_df, pred_df = train_test_split(df, train_size=0.7, random_state=111, stratify=df['TARGET'])
## 学習に必要なインスタンスの読み込み
sc = StandardScaler()
model = LogisticRegression(random_state=777, max_iter=5000)
## 学習
model.fit(sc.fit_transform(train_df[data['feature_names']]), train_df['TARGET'])
## 予測
output = model.predict(sc.fit_transform(pred_df[data['feature_names']]))
pred_df.loc[:, 'PRED_TARGET'] = output
## 正解率(予測が合っていた割合)を算出
accuracy = len(pred_df.query('TARGET == PRED_TARGET'))/len(pred_df)
print(f'Accuracy: {accuracy}')
# Accuracy: 0.9649122807017544最後の結果から、予測データにおいて大体 96% の正解率で当てられるモデルができたことがわかります。