G検定(公式名:ジェネラリスト検定)は、一般社団法人日本ディープラーニング協会(JDLA)が実施している、ディープラーニングを事業に活かすための知識を有しているかを確認するための試験です。年に3回実施されます。G検定の詳細は以下の記事をご覧になってください。
G検定(ジェネラリスト検定)とは?【データサイエンティストに関わる資格】 | データサイエンスコラム|アガルートアカデミー
こちらの記事では、新たに勉強を開始する方への参考となる指針を抽出すべく、Twitter上のG検定に関する投稿を分析し、最新のG検定の出題傾向を探ってみました。
Twitterのコメントから分析するG検定 – GRI Blog
この記事では、その中で最も頻繁に現れた専門用語について、解説していきたいと思います。G検定試験は、人工知能、機械学習、ディープラーニングに関する技術的な知識だけではなく、AI分野の法律や関連分野の規則についても出題されます。後者は受験者に軽視されがちである一方で、分析結果からでもわかるように、合否の決め手ともなり得ます。試験とは関係なく、これらの知識はAIに関わる仕事に携わる人々も、近未来社会を生きるすべての人々も知っておく事項が多いです。
<2020年3月の試験後、Twitterにおける最頻出用語>
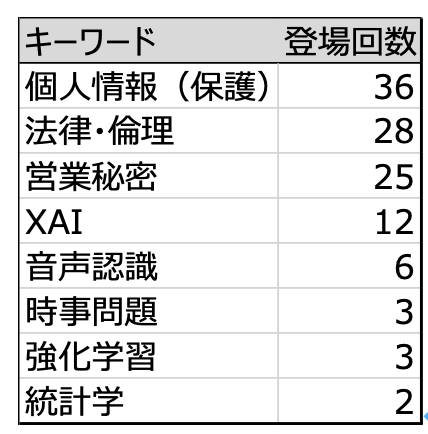
では、以下で解説していきます。
個人情報保護法
再頻出のキーワードとして、「個人情報」がありました。2020年6月に個人情報保護法の改正が行われました。デジタル化が進み、データ活用が進む中、個人情報は十分に注意を払って取り扱わないと、うっかり公開してしまったり、第三者に開示してしまったりすることで、トラブルになる危険性があります。一方で、データサイエンスはこのような膨大なデータをいかに有用に活用するかという技術ですから、個人の保護と社会への貢献のバランスがとれるようなルールが、その時代の技術レベルや社会動向に合わせて改正されています。
個人情報保護法では、民間事業者が個人情報を取得、利用、保管、提供する際のルールを定めています。例えば、利用目的を明確にし、安全に保管する、などの守るべき事項が定められています。2020年の改正では、データサイエンスの分野では重要となる「仮名加工情報」という概念が導入され、また、某就職情報サイトの事件に関係する「第三者提供」に関する法改正がなされましたので、どういう内容なのかを知っておきましょう。
データサイエンスの基礎知識として、この個人情報の取り扱いの注意事項は知っておく必要がある。そういう趣旨で個人情報保護法に関する多数の出題がなされたものと思います。
不正競争防止法
次に「営業秘密」というキーワードが目立ちました。これは、不正競争防止法の概念です。不正競争防止法も、個人情報保護法と同様に、データサイエンスに関わる人だけではなく、どのような仕事をする上でも守らなくてはならない重要なルールを規定していますから、しっかり理解しておくことが重要な法律です。
では、なぜこのタイミングで、G検定で出題されているのでしょうか。2019年の不正競争防止法の改正にあると思われます。この改正では、ビッグデータなどのデータ活用を促進する目的で、「限定提供データ」という概念が導入されました。これがデータサイエンス業界においては、非常に重要で、しっかり理解しておくことが不可欠なものなのです。
限定提供データとは、厳密な定義は条文を参照していただくとして、商業的な利用価値の高いビッグデータで、一定の条件の下で特定の者に提供するデータのことを指します。このようなデータは、取得、蓄積、管理にコストがかかっています。その有用性から不正に取得・利用されると、損害を受けてしまいます。このようなデータを法的に保護し、不正な利用を防止する目的から、不正競争防止法におけるルールとして加えられたのです。また、限定提供データの定義には、「営業秘密ではないこと」という要件が入っていることから、その理解には「営業秘密」とは何か、その取り扱いの注意事項を知っておく必要があります。
その他・法律/倫理
上で特に頻出したキーワードである「個人情報」と「営業秘密」について説明しました。そのほか、twitter上では、「知的財産」「特許」「著作」などのキーワードも登場しました。特許法や著作権法も、データを取り扱う上で重要な法律です。特に、開発したプログラムや機械学習アルゴリズムが知的財産としてどのような扱いを受けるのか、ぜひ理解しておきましょう。
また、twitter投稿から窺うと、ディープラーニングの技術的な進展の中、自動運転やドローンに関する出題もあるとのことです。特に、自動運転に関しては、その実用化に備えて、道路改正法の改正が行われています。法律上で「自動運行装置」が明確に定義され、いわゆる「レベル3」の自動運転車の公道走行が可能になりました。しかし、安全上の観点から、いくつか義務が明記されています。自動運行装置を使う運転者には守らなくてはならない義務があります。また、作動状態記録装置による記録・保存義務も定められています。
XAI(説明可能なAI)
ディープラーニングは他の機械学習手法と比べて、ブラックボックス度が高く、その推定結果の解釈性に劣るということが言われてきました。それは現時点でも同じであり、G検定でもよく出題されるポイントです。
一方、そのブラックボックスを少しでも見えるようにする試みがなされており、推定のプロセスを人間が理解できるようにする技術の開発が進められています。アメリカのDARPA(国防高等研究計画局)が「XAI (Explainable AI)」と命名し、広く概念が知られるようになりました。技術的には発展途上ですが、今後のデータサイエンスの発展のカギとなる重要な概念です。
その他の頻出概念
Twitterの投稿によると「音声認識」や「強化学習」が多数出題されたとのコメントがあります。音声認識、自然言語処理、強化学習は、研究が盛んにおこなわれている領域ですので、日々技術は進化しています。すべてを理解することは難しいかもしれませんが、AI白書などの最新情報から、どのような方法でどこまでできるようになったのかを知っておくことは重要でしょう。
また、最新の技術だけでなく、twitterによると、「統計学」の知識を問う問題も出題されました。特に、共分散や相関係数といった基礎的な概念から、自己回帰モデルなどのやや発展的な統計手法もキーワードとして出てきました。機械学習ではない、従来の統計学も、データサイエンスにおいては、重要なツールです。場合によっては、最新の技術を使うのではなく、古くから知られる伝統的な統計手法のほうが、解釈性に優れた結果を出すこともあります。機械学習と合わせて、統計学の勉強もお勧めします。
時事問題としては「ディープフェイク」がキーワードとして登場しました。最近では、本来ディープニューラルネットワークを使って正しく認識できるはずのデータに、何らかの人為的なノイズを加えることによって、その認識にエラーが発生してしまう、判断を誤ってしまうという現象が、「adversarial example」として知られています。これは、前に述べたディープラーニングのブラックボックス性もあり、問題となっています。XAIなどの技術進展とともに、このような誤認識を防ぐための技術開発にも期待が高まっています。
以上、twitterから見える、最近のG検定試験における興味の高い用語を解説しました。
弊社では、G検定試験対策講座を提供しております。本講座では、初めてデータサイエンスを学ぶ方でも充実して学べるように、初歩的な事項から入り、一歩一歩丁寧に知識をお伝えしていきます。ついていけるか不安のある初学者の方、基礎からG検定合格にリーチするレベルまで学習したい方に最適な講座です。是非覗いてみてください。
担当者:ヤン・ジャクリン(分析官・講師)
www.agaroot.jp