
改めて、GRIデータサイエンスもくもく会とは、人工知能、機械学習、データ分析、Python、ディープラーニング、G検定、数学、統計学など、参加者全員で毎回異なるトピックについて一緒に学び、教養を身につける「オンライン勉強コミュニティ」です。GRIの分析官が講師を務め、皆さんが興味を持ちそうなトピックで講義しながら皆さんと質疑応答を行います。ライブ講義だけではなく、Slack上でもディスカッションを展開しています。
そして、皆さんの参加をより価値のあるものにすべく毎回課題を提供し、記事及び次のもくもく回(間隔は半月程度)で課題を解説します。
前回の記事はこちらです。https://gri.jp/media/entry/2409
第1回目のテーマ:これでバッチリ理解! 〜画像認識の王道〜畳み込みニューラルネットワーク(CNN)を解明〜
https://techplay.jp/event/832395
動画:https://youtu.be/afapha5BCXI
ここで出された課題を次回のもくもく会と共に、先駆けて、本記事ででも解説したいと思います。
第1回もくもく回の課題
第1回目は、考察系の課題を2つ、計算問題を1つ出しました。
考察する課題に関しては、たとえ既に研究が進んでいる概念でどこかのテキストに答えが載っているものだとしても、ご自身の言葉で相手に説明できるようになることが学習の過程の中で最も重要なベンチマークの1つだと信じているので、日頃こういう課題を出すのが好きです。
改めて、課題は以下です。
もくもく会の課題(考察編)

課題1の解説
課題1はデータ拡張(Data Augmentation)のことです。
画像分類の精度を達成するために学習データは大切のはいうまでもないです。学習データの量だけではなく、そのバリエーション(網羅性)や偏りがないことも重要です。ただし、あらゆる種類の画像をほぼ同量で撮影のは大変です。さらにいうと、撮影後に一つひとつの画像「ラベル付け」することはさらにコストが高いです。
↓
そこで活用されるテクニックは データ拡張です。擬似的・人工的に学習用画像データのバリエーションを増やすために使われます。具体的には、下図のように、画像を上下左右に平行移動、回転、拡大縮 小をランダムな量で行い、それぞれの変化を適用した後の画像が 1 つの新しい画像としてみなされます。
今私は、「みなされる」と書きましたね。「新しい画像が生成される」とは書いていません。あくまでも、「人工的に」しか、学習用画像データのバリエーションを増やしていません。これはどういうことなのか、さらに考えていきましょう。
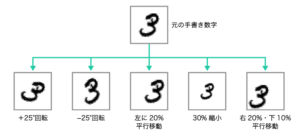
引用:ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[明瞭解説+良質問題]https://www.sbcr.jp/product/4815611675/
もし仮に、本当に平行移動や回転などの操作を1つ行うたびに本当の新しい画像を1つ増やしていたら、水増しされた画像の数がどんどん膨らんでいきます。元も画像から発生した何倍ものあずの画像を全てコンピュータ内部にそのままの形で保管しようとしていたら、計算機のメモリが天井をヒットしてしまいます。そのため、画像を「まとめて保管」して画像数を増やすようなことは決してしません。代わりにスマートな解決策として、学習中にミニバッチごとに都度拡張しそれを学習に使用した後にはもう棄却するような方法を用います。こうすることで、データの総量は変わらず、バリエーションのみ増やすことができます(下図)。
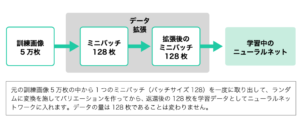
引用:ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[明瞭解説+良質問題]https://www.sbcr.jp/product/4815611675/
課題2の解説
課題2は、転移学習(transfer learning)のことを問っている問題です。
この2番目の課題は、データを確保する必要性というよりも、大量なデータを使って訓練するための計算リソース(計算機、GPUのパワーなど)やそれにかかるお金や時間に注目しています。
誰でもアクセス可能なオープンデータも含めて、データを大量に確保して使えても、数億程度のパラメータ数を持つ巨大なモデルを訓練するためのリソースはやはり必要です。これは個人はもちろん、企業でも、どの企業でも持っているわけではないです。持っていたとしても、毎回「パラメータを少し微調整してどうなるかを見てみたい」時に、その都度最初からネットワーク全体をもう一度訓練しなければいけないとなると、ものすごく時間がかかってしまいます。そうするとディープラーニングを用いたアプリケーションの開発がとてつもなく辛いものになりますね。
「毎回最初から訓練しなおす」のをしなくて済むようにしてくれるのは転移学習です。
転移学習とは
- あるタスクのために学習させたモデルを、他のタスクに適応する手法
- ゼロから学習を行うよりも、少ないデータ量で、効率的に高精度を出せることがメリット
転移学習に使われる学習済みモデルは、通常、大規模データセットを用いて学習したものです。大規模データセットで学習したモデルの隠れ層は、既に優秀な特徴抽出器になっており、それを少し違う別のデータに適用しても、それなりに汎用的なパラメータを提供できます。
学習済みモデルを新しいタスクに「使い回す」時に、新しいタスクに特化した専用の層を出力層に近い部分に追加します。上流の層はより「一般的な」特徴(領域の明暗や輪郭など)を抽出するので、画像認識モデル間で共通な要素が多いのに対して、CNN の出力層やそれに近い隠れ層は、特定のタスクに特化しています。そのため、転移学習 において、微調整や再訓練をするのは、主にネットワークの下流のパラメータになります。それなりに丁寧に下流のパラメータを調整する場合は、とくに、ファインチューニングと呼びます。
ディープラーニングを実装するのに使われるPythonのライブラリやフレームワーク、例えばKerasでは、「事前学習」された「学習済みモデル」がパッケージとして呼び出し可能になっており、開発者たちによって気楽に転移学習に使われています。
歴代ILSVRCでトップの成績を納め、ImageNet で学習したCNN(VGG16やResNetなど)もこのように学習済みモデルとして呼び出すことができます。これらのモデルのパラメータは、現在様々な画像認識課題に有効活用されています。
ちなみに、転移学習は画像の分野だけではなく、自然言語処理にも使われています。事前学習された優秀な言語モデルとしてBERTやGPT-2, GPT-3 などが挙げられます。
課題3の解説
G検定に出題される有名な計算問題、畳み込み演算です。
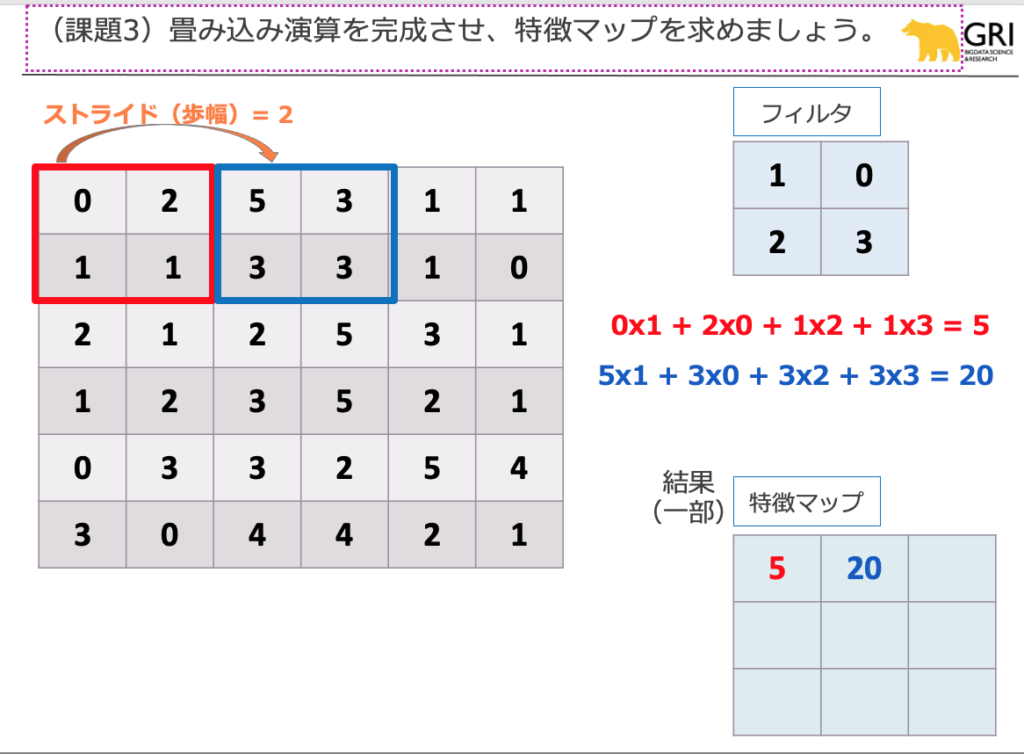
課題3の畳み込み演算は、非常にシンプルな計算ですが、非常に面倒な計算でもありますね。
課題の方では、既に計算の最初の方を示しています。フィルタと画像を被せた部分について(図では2×2の部分領域)、重なったセルの数字を掛け算し、部分領域全体でその掛け算の結果を足し合わせ、その結果を特徴マップ上の1つの数値として植え付けます。
図では赤い2×2の部分領域と青い2×2の部分領域についてデモストレーションしました。同じように青い領域の右側にある2×2領域について演算を行うと、
1×1 + 1×0 + 1×2 + 0x3 = 3
よって、特徴マップ上で1行目の20の右には3が入ります。
全く同様に他の全ての部分領域の計算を行うと、全体的な結果は以下です。
5 20 3
10 23 10
6 23 12
運よく0が多いと計算は楽になりますね(笑)。
以上課題1〜3は、第2回のもくもく会の冒頭で解説します!
【GRIデータサイエンスもくもく会#2】 これでバッチリ理解!
〜ニューラル機械翻訳の歴史と仕組みに迫る〜
2021/11/04(木)18:00~
https://techplay.jp/event/835775
記事担当:ヤン ジャクリン(分析官・講師)















