
セマンティック・セグメンテーションでは、物体の局所的な特徴だけでなく、画像全体の部脈情報(グローバルコンテキスト)が利用可能であることも重要です。この課題に対して提案されたのがPSPNet(Pyramid Scene Parsing Network)です。
PSPNetの主要な特徴は、エンコーダとデコーダの間に Pyramid Pooling Module(空間ピラミッドプーリング)を追加することで、特徴マップの局所的な情報と大域的な情報を同時に取得していることです。
具体的に、エンコーダーのCNNによって抽出された特徴マップに対して、対象領域のサイズを1×1、2×2、3×3、6×6などのように変更しながら、異なるスケールのプーリングを実施しています。そしてそれぞれの結果をアップサンプリングして統合します。
これにより、局所的な特徴と画像全体にわたる大域的な文脈情報を異なる解像度で拾うことができます。例えば、特定の画素の近辺だけでは判別が難しい場合でも、画像全体を考慮した正確なセマンティック・セグメンテーションを実現することができます。
ところで、ここでいう「画像全体の文脈情報(コンテキスト)」とは、特定の画素単体ではなく、その周囲の情報や画像全体との関連性を手がかりにして予測を行う情報、と言い換え得ることができます。
通常のCNNは、小さな領域の局所特徴、境界線、テクスチャなどを捉えるのが得意です。しかし、局所的な画素だけ見ると区別が難しいことがあります。例えば、「花壇」、「花屋さん」、「花柄の洋服」の局所パターンが似ています。この問題を解決するために、Pyramid Pooling Moduleでは、より大きな領域や画像全体といった複数スケールの情報を集め、シーン全体の状況(グローバル情報)を利用できるようにしているわけです。
(補足)テキスチャとは、ある領域における画素の細かいパターンや質感の繰り返しを指しています。
図1に PSPNet の模式図を示します。エンコーダには ResNet101 の特徴抽出層を使用しています。Pyramid Pooling Module (図の(c))では、エンコーダで抽出された特徴マップに対して、複数の解像度で最大プーリングを施します。結果として複数のスケールで特徴マップを生成し、画像の大域的な情報から局所的な情報まで広範囲の情報を入手します。続いて、デコーダで特徴マップに対してアップサンプリングを行い、シーン分割の結果を出力します。
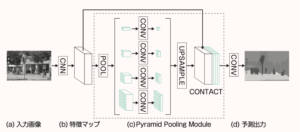
図:Pyramid Pooling Module を採用した PSPNet の模式図
出典:[Zhao et al., 2017]
出典 URL https://ar5iv.labs.arxiv.org/html/1612.01105
この仕組みにより、シーン全体の意味関係を考慮した分類が可能となり、複雑な背景を含むシーン画像においても複数物体の分離と検出を高い解像度で行う能力を示します。実際、PSPNet には、PASCAL VOC 2012 や Cityscapes といったシーン分割の代表的なデータセットで一位を勝ち取っています。
シーン画像については:https://gri.jp/media/entry/33751
PSPNetとDeepLabは、広範囲の情報を画像分類に利用するという目的が共通しているが、その実現方法に違いがあります。DeepLabがAtrous Convolutionによって広い受容野を確保するアプローチを取ったのに対し、PSPNetは異なるスケールのプーリングを利用して文脈情報を統合するアプローチを採用している点に特徴があります。













