音声認識の基本プロセス
「音声認識」とは、音声をデジタルデータに変換して、それをコンピュータに認識させることです。人間の話し声などの「音声」などは 物理現象であり、波動として空気(物質)を通して伝播しています。空気振動の特徴やパターンをコンピュータに読み込み、表現されている単語列の意味を認識させます。
聴覚情報は視覚情報と並んで、人と機械の間を取り持つインターフェイスとして広範囲での応用が実現されています。代表例はApple社の「Siri」、Amazon社の「Alexa」などの「スマートスピーカー」です。自然言語処理と音声処理の両分野の技術を組み合わせることで、大まかに以下の流れでサービスを提供しています。
ユーザー質問の音声を認識してテキスト化する(音声認識、自然言語処理)
↓
適切な応答を判断し、それに対応するテキストを生成する(自然言語処理)
↓
応答の音声を合成する(音声生成)
他にも、点字を音声に起こすような視覚障害者援助システム、家電のハンズフリー操作など、数多くの音声認識技術の応用例が挙げられます。
音声認識の手順は、一般的に以下のとおりです。
- 音声をデジタル情報に変換する
- 音声波形から周波数や時間変化などの特徴を抽出する
- 言葉の最小単位である音素を特定する
- 辞書と照合することで音素列を単語に変換する
- 単語間のつながりを解析して、文章を生成する
音声をデジタルデータに変換
音声は空気や物体を通して伝わる「波動」であり、時間に対し連続的に変化するアナログデータですので、まずはコンピュータで処理可能な離散的な数値データに変換する必要があります。この変換をA-D変換(Analog to Digital Conversion)と呼びます。
音声のA-D変換の流れはこの記事「【DS検定頻出・画像データ処理#1 】標本化・量子化・符号化」で学んだ画像のA-D変換と同じ流れとなっています。
【標本化、量子化、符号化の流れで音声信号を準備】
- 標本化:連続的な音波を一定の時間間隔ごとに切り出す
- 量子化:波の強さを離散的な値に近似する
- 符号化:量子化された値をビット列で表現する
音声のA-D変換によく用いられるのは、パルス符号変調(Pulse Code Modulation; PCM)という手法です。具体的に、アナログ信号の強度を一定間隔で標本化(サンプリング)し、整数値として量子化し、最後にビット列で表現します。
以下では、これらのプロセスを詳細にみていきましょう。
■音声の標本化
標本化(サンプリング)とは、連続なアナログ信号を一定の時間間隔で切り出して測定し、その都度観測された離散的な数値(標本値)を記録することを指しています。図1にある丸い点がサンプリングされた離散値を表します。
「1秒間に音波の情報を数値に変換する回数」をサンプリングレート(サンプリング周波数)と呼びます。これは、動画のフレームレートと同じ考え方です。このレート(周波数)が大きいほど、元のアナログの音声をより正確に再現できます。ただし、その分、音波の情報を大量に蓄積するのでデータ量が大きくなります。逆にサンプリングレートを低くすると粗い波形になります。
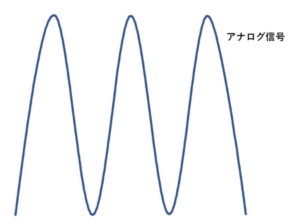

図1:左:「アナログ」の音の波形 (右)「デジタル」の音の波形。記録する回数が多ければ多いほど、画像の点が多くなり、より元の波形に忠実なデータとなる。
CDの音声を例に考えましょう。CDは多くの回数にわたって音波の「デジタルの信号」を記録している媒体です。
CDの音声は、サンプリング周波数44.1kHzで記録されることが規定されています。これは、「1秒あたり44100回信号を測定し記録する」ことを意味しています。図1の右側の画像において、横軸の1秒間の区間の中に、データ点が44100個ある、ということです。
CDを再生する際にそれらのデジタル信号を「物理的な音」に復元します(音の復元の過程はA-D変換の逆の過程であり「D-A変換」と呼ばれます)。CDは44.1Hzで音声信号を記録しているのに対して、実は再生する装置(スピーカー、ヘッドホンなど)は同じ周波数で再生していません。
なぜなら、そこまで高い周波数で再生しなくてもよくて、半分あたりのHzまでさえ再生すれば聴く音が損なわれないからです。
この不思議な現象には、サンプリング定理(標本化定理、ナイキストの定理)というもので説明されます。「どのぐらいの間隔でサンプリングすれば元の波形を忠実に再現できるか」を示す定理です。
サンプリング定理は以下を言っています。
A-D変換でデジタル信号に正確に変換するためには、再現したい信号に含まれる最も高い周波数の2倍を超えるサンプリング周波数で標本化を行う必要があります。
これを満たせば、デジタル化された後のデータから元のアナログ信号の波形を正確に再現できます。
上記を言い換えると、サンプリング周波数の半分の周波数までの信号は再現可能です。この限界をナイキスト周波数と呼びます。そもそも人間の音声に対する可聴上限が20kHz程度です。そのため、CDなどにおいてサンプリング周波数が40kHzを超えれば、録音データから十分に自然な音が再生できると考えられます。実際、よく使われるサンプリングレートは44.1kHzと48kHzです。
まとめると、人間は20kHzくらいの帯域よりも高い周波数の音をそもそも聴こえないので、音の再生装置は20kHz程度の音を「再現」すればいいのです。そうするとサンプリング定理により、CDは20kHz×2 = 40kHz をちょっと超える周波数で音の標本化を行えばいいという意味です。
逆に、サンプリング定理に違反すると、さまざまな音が混ざりあったような不明瞭な音を再生してしまいます。例えば、ある音楽が5kHzであるとし、それを2倍を下回る8kHzで標本化した場合、サンプリング周波数の半分の4kHzあたりを境目にして、3kHzの信号と5kHzの信号が混ざりあって区別ができなくなります。この現象をエイリアシング(折り返し雑音)と言います。
■音声の量子化と符号化
特定のサンプリングレートで切り出された音声を離散的なデジタルデータの列として記録するために量子化(Quantization)を実施します。
音声信号を量子化するレベル(段階)、つまり「信号を何段階の数値で表現するか」は量子化ビット数で表されます。量子化ビット数が大きいほど、細かく音波の情報を数値に変換できて、元の音を忠実に再現できますが、その分データ量が増大します。
- 2ビット:2^2 = 4 段階
- 3ビット:2^3 = 8 段階
- 16ビット: 2^16 = 65536段階
最後に、音声の符号化では、量子化された値をビット列で表現し、さらに音声の性質に基づいてデータ圧縮を行いデジタルデータに変換します。このとき、なるべく少ない情報量で音声の情報を表現する技術が使われます。
■音声のデータ量
A-D変換後のデータ量は、データ量は、{サンプリングレート、量子化ビット数、音声の長さ}、この3つの数量を掛け合わせたもので決まります。その単位としてバイトがよく使われます。
アナログの音をデジタル信号に変換するときに、ある程度の誤差は必ず生じます。この誤差をなるべく小さく抑えるためには、サンプリングレートを高く、かつ量子ビット数を高くすることが望ましいです。
CDの音声は、サンプリング周波数44.1kHz、量子化ビット数は16ビットで記録されることが規定されています。これは、1秒あたり44100回信号を測定し、その一回で得られた信号強度を216、つまり65536段階で表していることを意味します。これがDVDの場合の24ビットになると224、すなわち1677万段階の数で表現されます。
【計算例】
サンプリングレート50 kHz、量子化ビット数:16ビットで用意した音声が30秒間保存されているデータがあります。この音声データのデータ量は以下のように計算されます。
50,000 Hz x 16 ビット x 30 s = 24,000,000 bit = 3 Mバイト
ここで、Hz の単位は s(秒)の逆数です。
また、bit(ビット)と byte(バイト) は両方ともデータ量を表すための単位で、これらの関係は 1 byte = 8 bit、あるいは 1 bit = 0.125 byte です。
また、データ量を「1秒あたりのデータ量」として表現することもあります。こちらは、サンプリング周波数と量子化ビット数を掛け合わせた量で決まります。
上記のCDの例では、1秒間あたり44,100回のサンプリングを行い、各回16ビット(2バイト)のデータを記録すするため、「1秒あたりのデータ量」は、705.6 kbps(キロビット毎秒)または 88.1 KB/s (キロバイト毎秒)となります。
データ量と音声の質はトレードオフ関係にあります。高音質の音声はサンプリングレートやビット数が高いため、データ量は必然的に大きくなります。
音声データの保存フォーマット
音波をデジタル信号に変換した後に1つのファイルに保存します。代表的な音声データの保存フォーマットとしてWAV形式とMP3形式があります。
WAV(Waveform Audio File Format)は最も単純で、取得した音声デジタルデータを全てそのままの形で保存する非圧縮のフォーマットです。そのため、高音質であると同時にデータ量が大きいです。
それに対して、MP3(MPEG Audio layer3)は、人間の可聴領域に合わせて音声データを圧縮した上で保存するフォーマットです。人間が聞こえる音の高さには上限と下限があります。MP3は人間が聞こえない領域のデータを捨てることで、普段使いの上では違いに気づかない状態を保ちながら、少ないデータ量で保存することを可能にします。この圧縮は非可逆圧縮です。
しかし、「人間が聴く以外の目的」あるいは「人間には聴こえないが機械には検知できる音」で使用する場合、例えば、機械の故障検知または故障予測などでは、WAVを使用した方がいいでしょう。
上記の他に、FLAC(Free Lossless Audio Codec)もデータを圧縮します。その名称にあるコーデックとは、音声や動画の圧縮と復元をする技術の1つです。FLACは圧縮した音声データを元に戻せるため可逆圧縮であるのに対し、MP3は非可逆圧縮です。
執筆担当:ヤン ジャクリン (GRI データ分析官・講師)