前回は、「食べログ」のレビュー文に対して、Google Cloud Natural Language APIのエンティティ感情分析により抽出された重要語毎に感情スコアを計算したが、レビュー文内に存在しないワードが出現する謎現象が起き、ネガポジ判定の材料に活用することが難しそうであったため、少し違う切り口を探そうと思う!
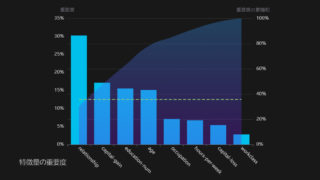
1. 今回の分析
Google Cloud Natural Languageにはコンテンツ分類のためのAPIも存在するみたい!
コンテンツ分類の結果が「食べログ」のレビューのネガポジ判定にどのように活用できるかは模索中だが面白い結果が出ると嬉しいな(笑)という思いで試そうと思う。
2. コンテンツ分類結果
レビュー別のコンテンツ分類結果を下の表に示す。
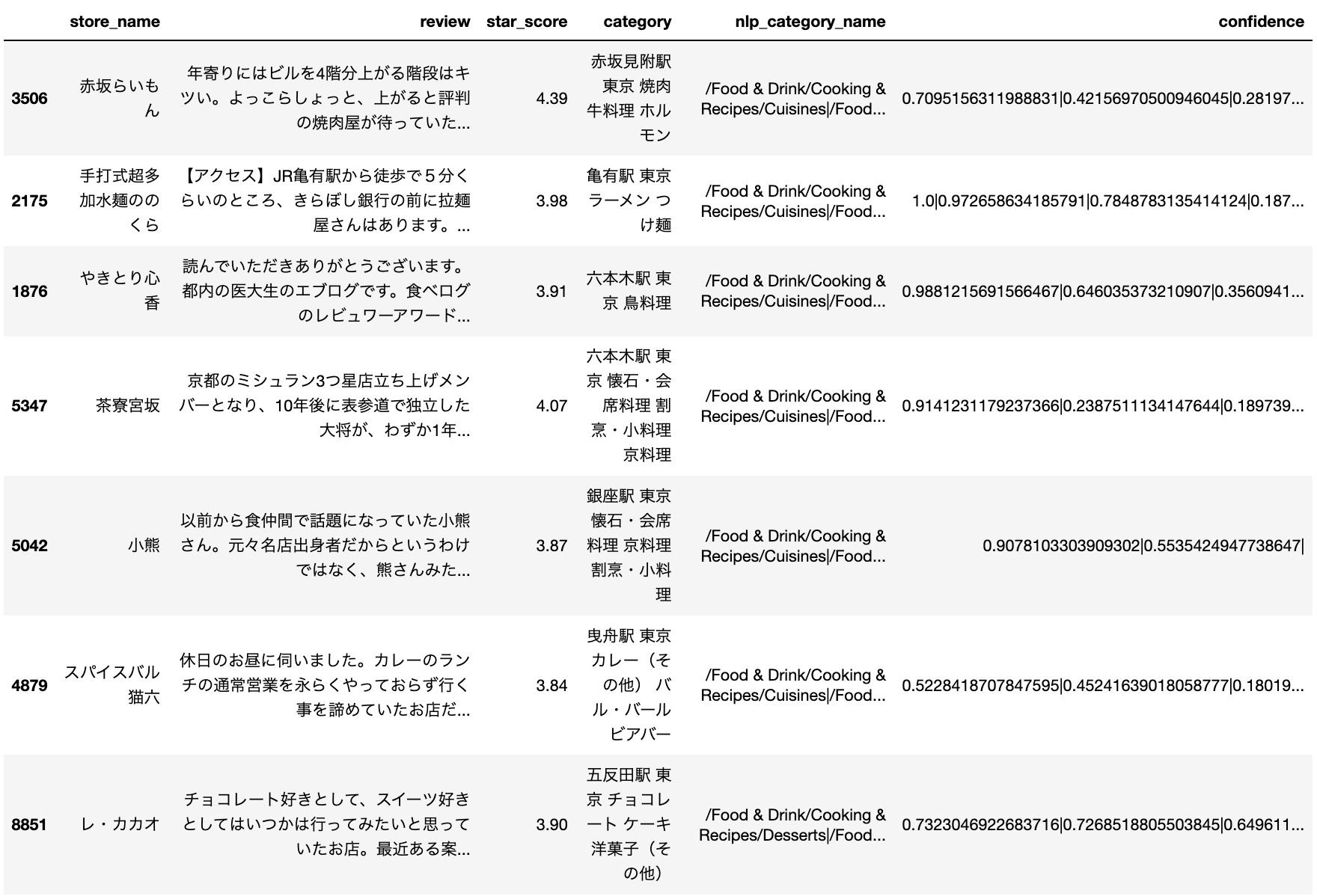
カラム「nlp_category_name」に該当コンテンツが格納されているがどうやらマルチカテゴリ分類されるみたい。また、カラム「confidence」に該当コンテンツごとの信頼度スコアが格納されている。パッと見だと、「Food & Drink」といったコンテンツがかなり付与されている様子。そこで、店舗ごとに付与されたコンテンツの種類と付与数を確認した。
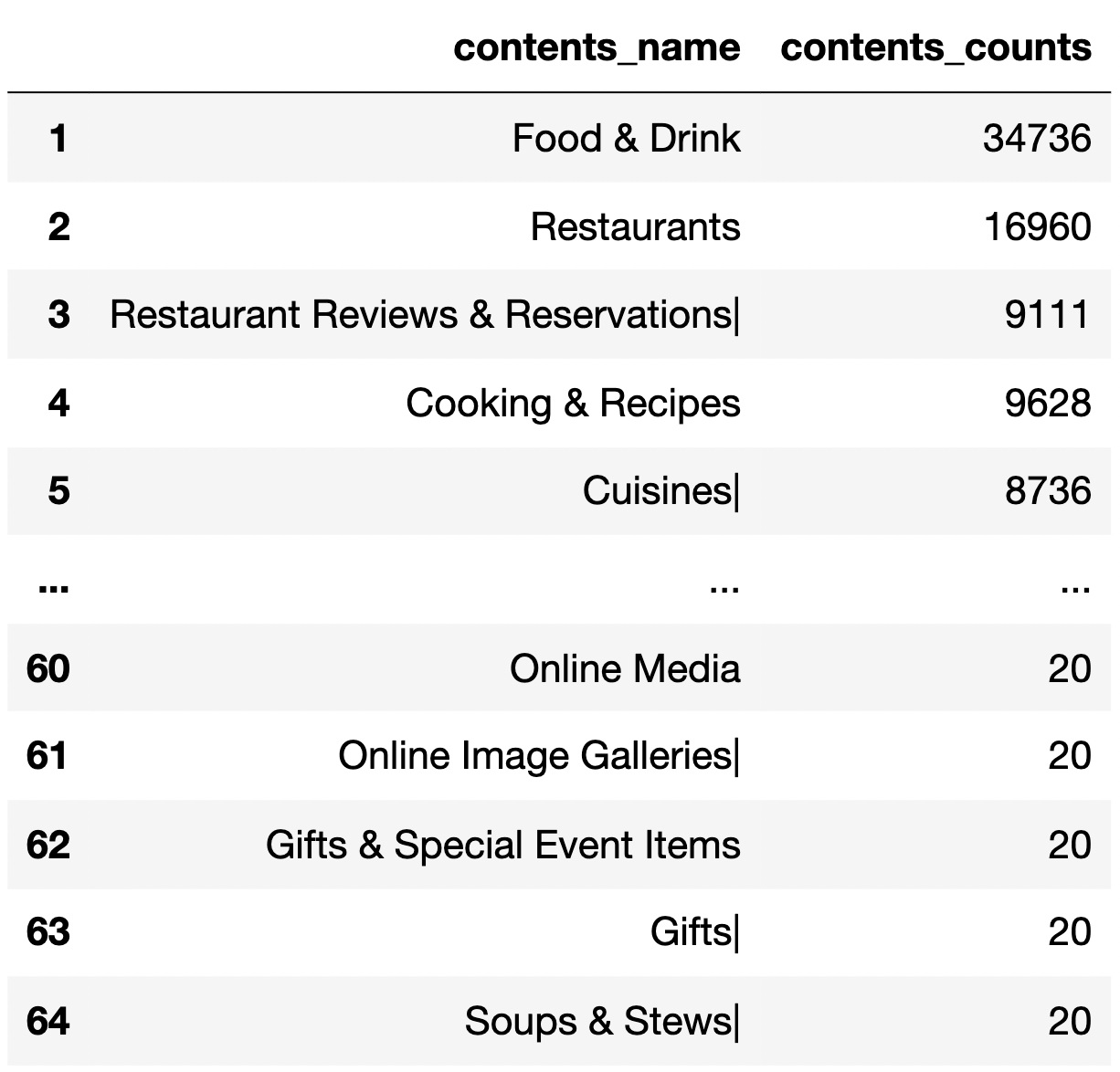
予想通り、コンテンツ「Food & Drink」は圧倒的に多い。少数ではあるが、「Online Media」や「Gifts」、「Soups & Stews」なども見受けられる。何かのメディアで取り上げられておりそういったワードがあったのかもしれない。また、「Soups & Stews」のように「Food & Drink」といった抽象的なコンテンツではなくもう一歩踏み込んだ詳細なコンテンツが付与されている場合もあり、料理に関する詳細コンテンツの粒度まで落とし込んだカテゴリは今後利用できるかもしれないといった印象がある。
3. おわりに
今記事では、「食べログ」のレビュー文のネガポジ判定の材料としてGoogle Cloud Natural Language APIのコンテンツ分類を用いてレビューごとにどのようなコンテンツが付与されるのか確認した。
次回はこれまでに行ってきた分析を取りまとめたネガポジ判定の分析を進めようと思う。