
この記事では、文章生成を含む様々な自然言語処理(NLP)タスクにおいて重大な役割を持つTransformerのアーキテクチャーを解説します。私自身が執筆しました書籍、2冊ともに、TransformerとAttentionを十分に明瞭に解説できていないことがずっと後ろめたく、今回はそう遠くはない第2版に向けて、よりわかりやすい記述を練っています。

Transformerの登場による言語処理精度の向上
従来のRNNを用いた言語モデルは下記のような課題が残されていました。
- 入力系列が長くなると、遠く離れた単語間の関係や文脈を正しく把握しなくなる
- 入力データを1時間ステップごとに処理する必要があり、並列処理ができない
2017年にGoogleの研究チームが開発したTransformer(トランスフォーマー)の登場により、上記の問題が改善され、長い文章の解析精度の飛躍的な向上をもたらしました。その背景にあるのはTransformerの内部構造に潜むAttention(注意機構)でという仕組みです。
Attentionは、各時刻における情報の重要度(重み)を計算し反映することで、重要度の高い情報に「注意」を向けて学習する手法です。人間が学習する時に重要な内容を優先するという感覚に近いです。これにより、文が長くても、つまり単語同士が離れていても、全ての単語の関係性を網羅的に把握し、それぞれの単語が果たしている役割を理解することができます。
(原論文)“Attention is All You Need” (RNNやLSTMはもはや時代遅れという意味) https://arxiv.org/pdf/1508.04025.pdf
Attentionを内蔵することによって、Transformerが自然言語処理において優れた性能を発揮することができています。その後、大規模自然言語モデル(LLM)の大部分はTransformerを使用して開発されており、機械翻訳、文章分類、文章生成など多様多種な言語タスクに応用されています。例えば、現在ChatGPTなどで注目の「文章生成」では、Transformerは先行する文章(あるいはプロンプト)中の単語の関係性を理解し広い文脈を考慮しながら、次に来るべき単語を予測し適切な文章を生成できるようになりました。
TransformerにおけるAttentionの役割
Attentionの役割に注目しながら、Transformerのアーキテクチャを体系的に理解していきましょう。
下の図1にあるような、Transformerを用いたニューラル機械翻訳モデルの模式図を用いて説明します。
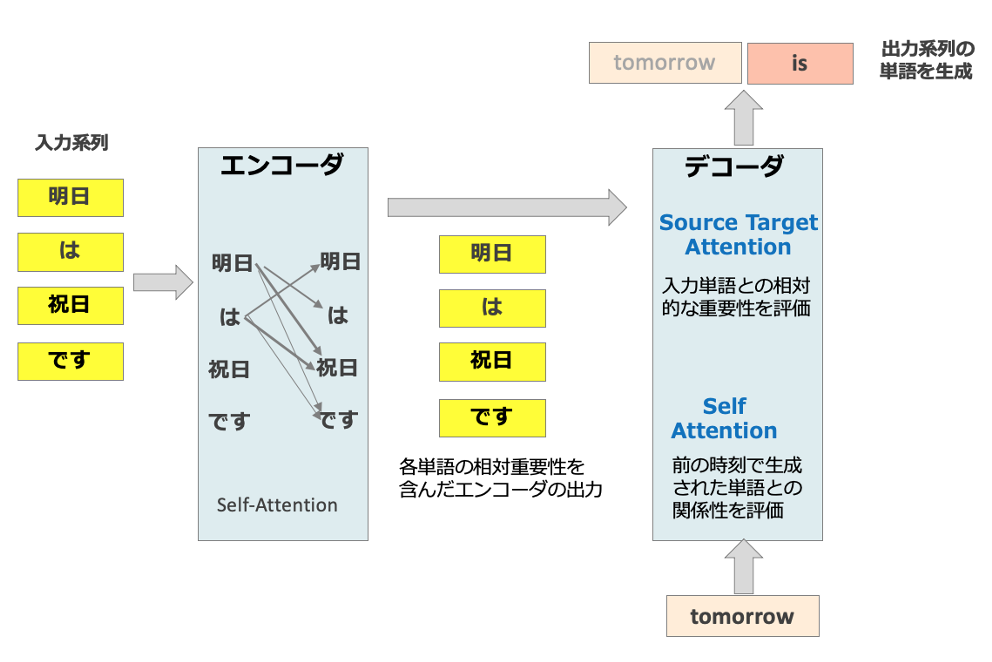 図1:Self-AttentionとSource-Target Attentionを内蔵したTransformerモデルの構造
図1:Self-AttentionとSource-Target Attentionを内蔵したTransformerモデルの構造
Transformerの主要な構成要素はエンコーダとデコーダです。エンコーダでは、入力文(翻訳前の文)を処理し、デコーダは、出力文(翻訳後の文)を一単語ずつ順番に生成します。例えば、”He is a teacher” という英文を和訳する翻訳タスクの場合を考えましょう。エンコーダへの入力は”He is a teacher”というSource文(翻訳前の文)、デコーダからの出力は「彼は先生です」というTarget文(翻訳後の文)です。
エンコーダーとデコーダーはそれぞれ、異なる目的で複数のSelf-Attentionの層を持っています。そして、デコーダにはSource-Target Attentionがあります(※これらの種類のAttentionについては別の記事で詳細に解説する予定です)。
まず、Self-Attentionの役割を考えます。
- (図1の左側)エンコーダで使われるSelf-Attention:入力文の各単語と他の単語の関連度を計算し、各時刻の単語の隠れ状態に対して、文脈に即した表現(エンコーディング)を生成し出力します。
- (図1の右側)デコーダで使われるSelf-Attention:デコーダーへ入力される「前の時刻で生成された出力単語」との関係を捉えることで、出力系列の生成において適切な次の単語が選ばれることに寄与します。これを特にMasked Self-Attentionと呼ばれます。通常のSelf-Attentionと同様の役割を果たすとともに、まだ生成されていない「未来」のトークンにはアクセスできないようにマスキングします。これにより、自己回帰的なモデル、つまり、各ステップでの出力がそれまでの出力にのみ依存するという性質を実現します。
次に、Source-Target Attentionは Transformerのエンコーダーとデコーダーを結びつける役割を果たしています。デコーダーにおいて、「エンコーダーが処理した各単語をデコーダーがどの程度重視するか」を評価し指示します。例えば、図1の例では、「明日」との関連が強い単語「祝日」がより重視されます。
上記のように、2種類のAttentionがそれぞれがTransformerモデルのパフォーマンスに重要な役割を果たし、これらが同時に作動することによって、ある時刻の単語を生成する際に、前の時刻の出力およびエンコーダに入力された系列の中から影響力の高い単語に注意を向けることができます。そして、Transformerは異なる言語間での単語の対応関係を学習し、従来に比べて文脈に基づいた正確な翻訳を提供することができます。
(図4.9.3に対する補足)
厳密にいうと、入力前に、単語を数値ベクトルに変換され、ベクトルの内積(図1の中の単語間を結ぶ線で代表)を計算することで単語間の類似性が求められます。そして、デコーダでは各単語の「確率分布」が出力されます。デコーダが実際に生成する単語系列は、この分布をもとに決定されます。
また、学習の時と予測の時はデコーダへの入力が異なります。学習の時は、「彼は先生です」という正解文がデコーダに与えられます。一方で、予測時は「彼は」というデコーダが出力した途中までに翻訳文がデコーダに入力されます。
【生成AIに関する記事を読みたい方はこちらから『ChatGPTビジネスレポート』に無料登録してください】
執筆担当:ヤン ジャクリン(GRI データ分析官、講師)















