リアルタイム基盤となると、最初に思い浮かぶのはPub/SubやKafka(AWSだとMSK)などメッセージパッシングの基盤になると思ふ。NetflixでもエッジデバイスでMQTT、Kafkaを使用しているし、Uberのインフラにも使われている様子(Real-time Data Infrastructure at Uber)。
データもIFも大量にあればKafkaを採用するメリットは十分にあると思うがスケールするか分からない初期時の導入は躊躇してしまうところ
今回はメッセージベースでなくても、GCPのサービスを活用し、比較的簡単にリアルタイム基盤を構築できたことを共有します
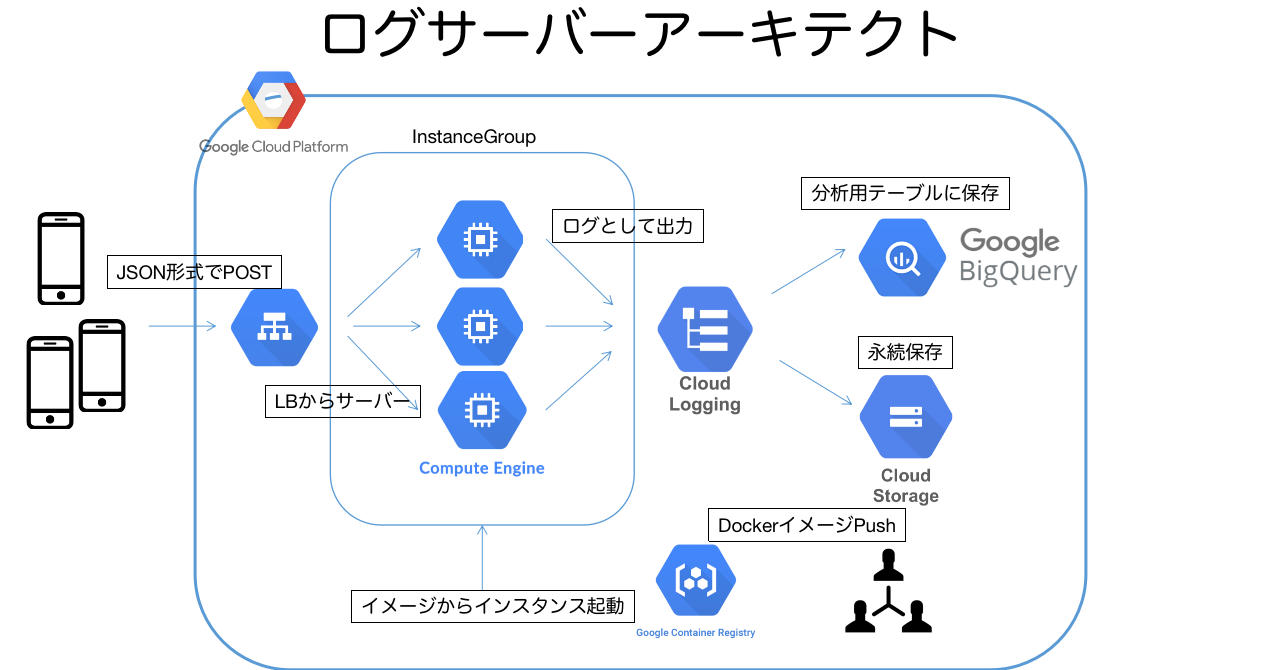
アーキテクト
※ぼやけてすみません。TOP画像と同じものです
構築
詳細の構成など書くと長くなるので割愛させていただきます
手順は以下のように行った
- APIサーバーの構築。エッジの負担を極力減らいたいため、簡単なログ出力だけに留めたのと言語はGoを使用し(弊社はpython勢がマジョリティ)、Dockerでコンテナ化した
- GCPのbuildでコンテナイメージをデプロイ
- イメージを選択した
instance templateをinstance groupでAuto Scaling、Health Checkの設定すればVMが立ち上がる - サーバーログの出力は、Cloud Loggingでみることができる(Cloud Loggingの保持期間はデフォルト7日間)。LoggingのLogs RouterのSink機能を使い、ログの永続としてGCSへ保存。もう1つは分析用としてBigQueryに保存。BigQueryには必要なデータだけを保存するようクエリ(logs query)でフィルタする(Sinkで設定)
注意点
- BigQueryに溜まデータはjson形式でネストされた状態。そのためきちんと構造化されたテーブルを定義し、データ整形処理するクエリをCloud Schedulerで定期実行するなどでETLをする必要はある
- Cloud Loggingの1エントリーのデータサイズは最大256KB。それ以上のデータをログに出す場合、分割してログを吐き出すなどサーバー側で処理が別途必要になります
結果
- LoggingのSink機能を使えばログ出力からBigQueryにリアルタイムで反映されるため、即時データを使った機械学習モデルなどを組むことが可能になった
- ただの出力サーバなのでインスタンスタイプを小さくすることでトータルでも安価な運用になっている(現状月数千円)
参照
- GCP Logging. Quotas and limits
- Netflix. Towards a Reliable Device Management Platform
- Uber. Real-time Data Infrastructure at Uber
kunimitsu higashi















