
本記事では元Facebook社(現Meta社)が開発した時系列予測パッケージであるProphetの使い方Tipsを共有いたします。時系列予測の基本的な考え方やProphetの使い方そのものに関しては、素晴らしい解説記事が巷に溢れかえっておりますのでそちらをご参照ください。ちなみにProphetに関しては本ブログでも度々ご紹介しております。

やりたいこと
さて、上の記事の最後で、さらに知りたいことの例の一つとして以下が挙げられています。
多種データの処理(一つのデータセットに多くの種類の予測対象があり、それらをループして予測。例えば、店舗ごとの予測値を出力し、それを全体で集約した全体予測値を算出)
これは実際に実務で使ってみると本当にあるあるです。
例えば、全国にチェーン展開する小売業のケースを考えてみましょう。この時、全国全店舗の売上を合計した時系列の予測をしても大したインサイトには繋がりません。
- エリアごとの売上予測
- 都道府県ごとの売上予測
- 店舗ごとの売上予測
- 利用客層で店舗をグルーピングしたときの売上予測
などと深掘りしていくことで初めて、「関東では売上伸びそうだけど関西では落ちそうだな」とか「ファミリー層が多い店舗ではこの商品群の売上がめちゃくちゃ伸びそう」とか分かるわけです。
ちなみにちょっと引っかかった方のために説明すると、僕が言ってるのは「売上の全国計を集計してから予測モデルを作ってもあまり意味ないよね」ということで、上の引用文のケースでは「店舗ごとに予測をしてそれを集約して全体予測値を算出」することを想定しています。当然この二つの操作は可換ではありませんので、出てくる結果は全く異なるものになり得ます。予測モデルに限らず分析の基本は、まずディメンションで分けることでしょう。
他にも例えば以下のようなケースで、「ディメンションごとに予測モデルを作成する」ことが求められそうです。
- エリアごとの視聴率予測
- デバイスごとのPV数予測
- 路線ごと区間ごとの乗車人数予測
ということでこの記事では、「デバイスごとのPV数予測」を例にして、PythonとProphetでディメンションごとに分割して複数の予測モデルを作るやり方について解説していきたいと思います。
BigQueryでデータセット準備
いつものGAデータ*からデバイスカテゴリごとの日次PV数を集計していきます。
*Googleアナリティクスヘルプ_BigQuery 用の Google アナリティクス サンプル データセット
SELECT device.deviceCategory, date, SUM(totals.pageviews) AS pageviews FROM`bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN'20160801'AND'20170731' GROUP BY 1,2 ORDER BY 1 DESC, 2 ASC
結果はこんな感じ↓(一番上にtabletの結果が来てますが、mobile、desktopと続きます。)
このような一枚表を用意したら、tablet、desktop、mobileそれぞれで予測モデルを作成していきます。また、期間は一年分しかありませんので、そこまで精度の良いモデルにはならないと思いますが、そこはご承知ください。あくまでhow toのデモだと捉えていただけたら。
PythonでProphetを使って予測モデルの作成
関連パッケージのインストール
この辺も詳細は他に譲ります。ここではコードだけ。
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
データ整形
上で用意したテーブルをcsvとして吐き出して、データフレームに読み込みます。読み込んだらProphetが扱えるようにデータを整形していきます。例えば、日付を表すカラムを日付型に変換したり、Prophteの命名規則に合わせたりといったところです。
# 日付を表すカラムを日付型に変換
def convert_to_datetime(df):
df['date'] = pd.to_datetime(df['date'], format='%Y%m%d')
return df
df = convert_to_datetime(df)
# Prophetは日付カラムを「ds」、予測対象カラムを「y」と命名する決まりがある
df = df.rename(columns={'date': 'ds', 'pv': 'y'})
デバイスごとのPV数の時系列推移を確認
予測する前に、まずはデバイスごとのPV数時系列をプロットしておきましょう。
grouper = df.groupby('deviceCategory')
for deviceCategory, _df in grouper:
_df.set_index('ds')['y'].plot(figsize=(20,5))
plt.title(deviceCategory)
plt.show()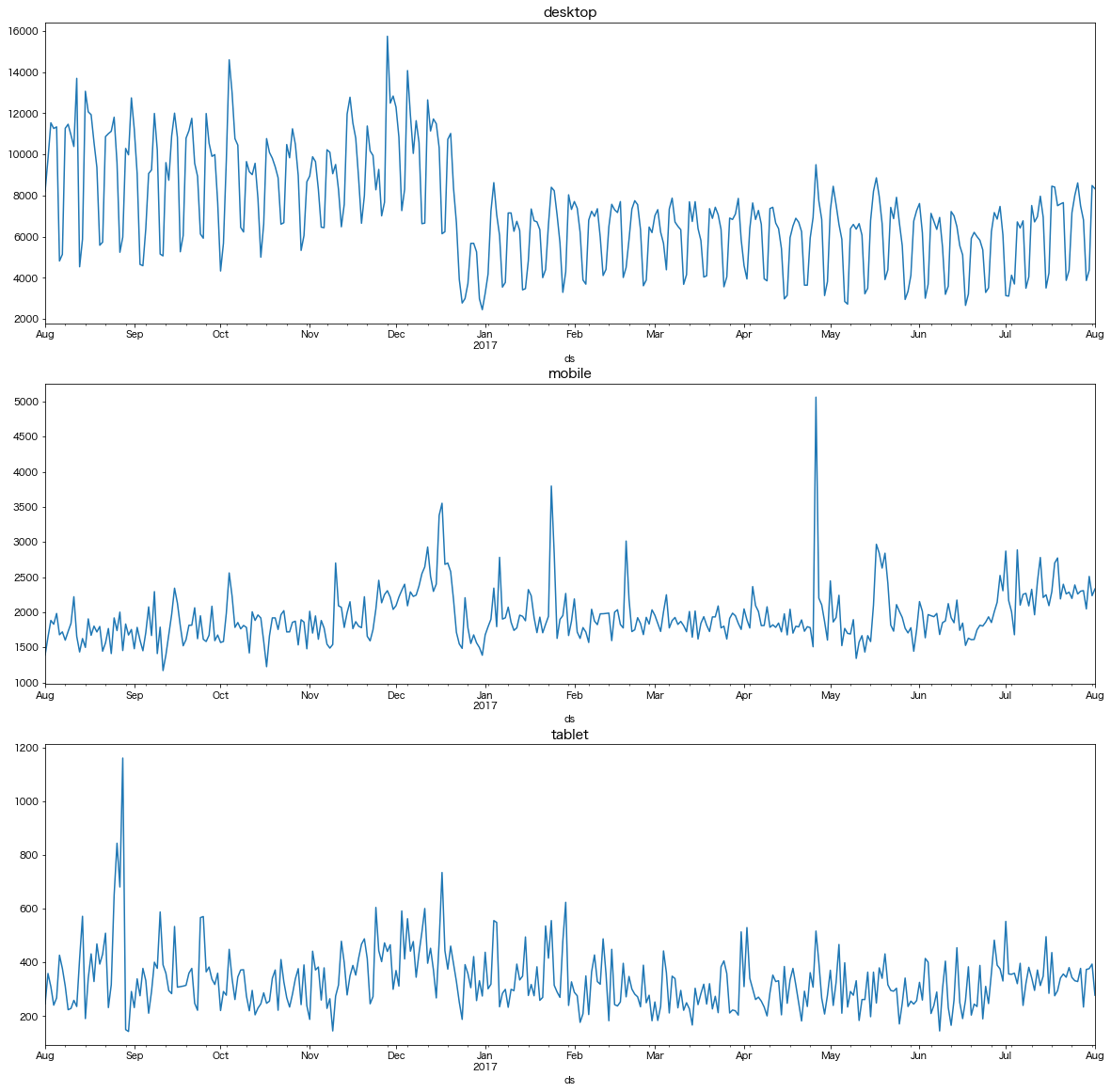
それぞれ特徴的な動きをしていることがわかりますね。
例えば、desktopでは2016年年末から2017年年始にかけて、PV数がぐっと落ち込んでいる期間が見て取れます。他のデバイスでは該当期間に特徴はないので、何かしらの変更がPCサイトにのみ悪影響を及ぼしてしまったのでしょうか。
また、tabletとmobileは同様に横ばい傾向ですが、たまにPV数が大きく跳ねることがあるようです。これは何かのキャンペーンがあったか、特定ヘビーユーザーの行動が影響しているかそんなところでしょう。
ちなみにProphetではこのような瞬間的に跳ねる「イベント」を明示的にモデリングすることが可能なのですが、今回は説明しません。
「Prophet holiday」とかでググれば色々出ると思います。
というわけで、デバイスごとに傾向の異なる時系列であることが確認できました。これらを合算した状態でPV数を予測しても示唆の浅い結果になることは明白ですので、デバイスごとに分割したモデルが作りたくなってくるわけです。
デバイスごとにPV数予測モデルを作成
本題です。以下のようなコードで行いました。
元のデータフレームをデバイスでgroup byしてから、ループを回します。ループ内ではデバイスごとに分割されたデータフレームを操作できるので、そこでそれぞれの予測モデルを作成し結果をプロット、という流れです。なお、今回はパラメータはいじらずデフォルトのものを採用します。(いじりたい方はこちらの記事参照)
# デバイスでgroup by
grouper = df.groupby('deviceCategory')
for deviceCategory, _df in grouper:
# 予測用インスタンス作成(パラメータはデフォルト)
m = Prophet()
# 予測モデルの作成
m.fit(_df)
# 予測用のデータフレーム準備
future = m.make_future_dataframe(periods=len(_df),freq='D')
future = future[future['ds']<pd.to_datetime('2018-01-01')]
# 予測実行
predict = m.predict(future)
# 予測結果プロット
fig1 = m.plot(predict)
plt.title(deviceCategory)
# 予測モデルの要素分解プロット
fig2 = m.plot_components(predict)
plt.show()
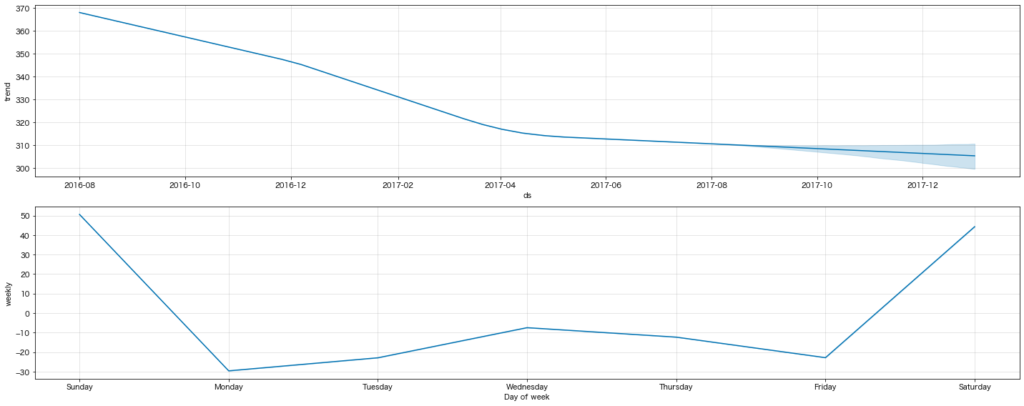
結果の確認:desktop
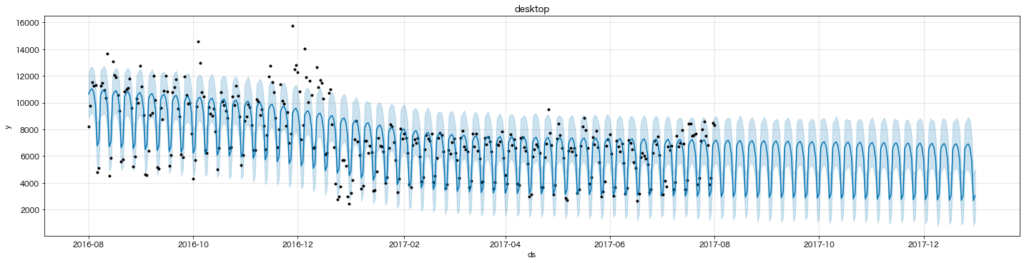
(上)予測モデルによって引かれたもの
黒点が元の時系列データ、青線が予測モデルによって引かれたものになります。薄い青で色付けされている領域は信頼区間のようなものだと思ってください。今回の予測モデルではこれくらいの幅ではブレるということです。
(中)予測モデルを要因分解した時のトレンド(傾向線)
(下)同じく要因分解した時の季節性(曜日)
結果を見ると2016年末に減少したPV数がこのままの水準で続いていくようです。また、曜日ごとのPV数を見ると、平日のアクセスが多い一方、土日のアクセスは少ないことも分かります。これは業務時間中にPCでアクセスしているユーザーが多いことが背景にあるということでしょうか。けしからんですね。
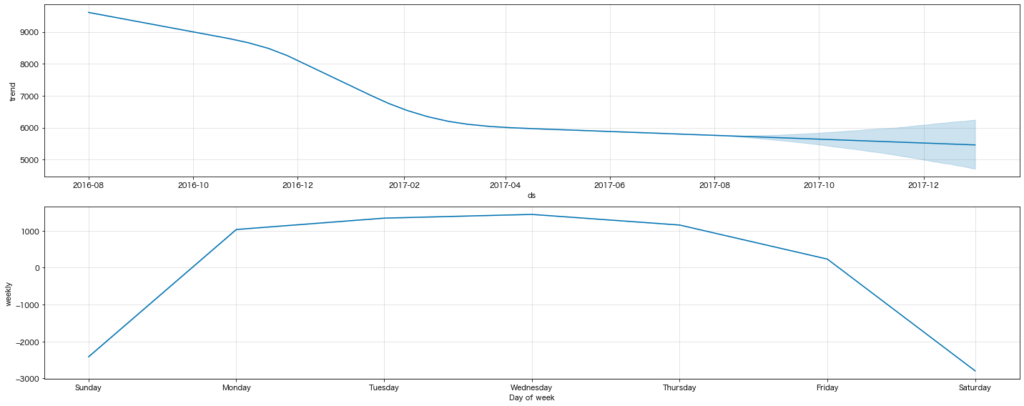
結果の確認:mobile
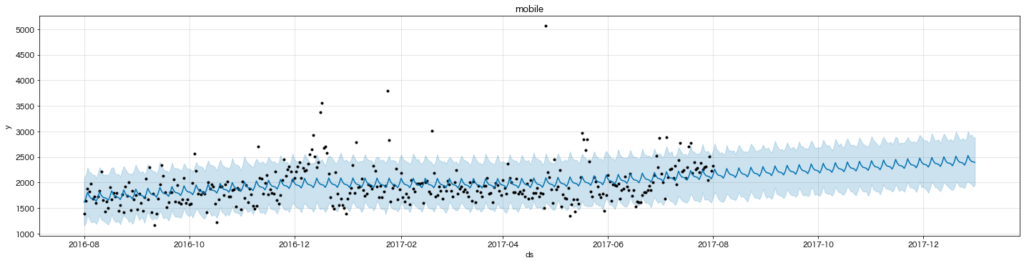
こちらはdesktopとは対照的にPV数が上昇傾向ですね。また曜日ごとで見ると水曜日のアクセスが最も多いことがわかります。実はこのデータは実在するeコマースストアのデータのようですので、週末のことを考えながらスマホで水曜日にお買い物するユーザーが多いということなのでしょうか。
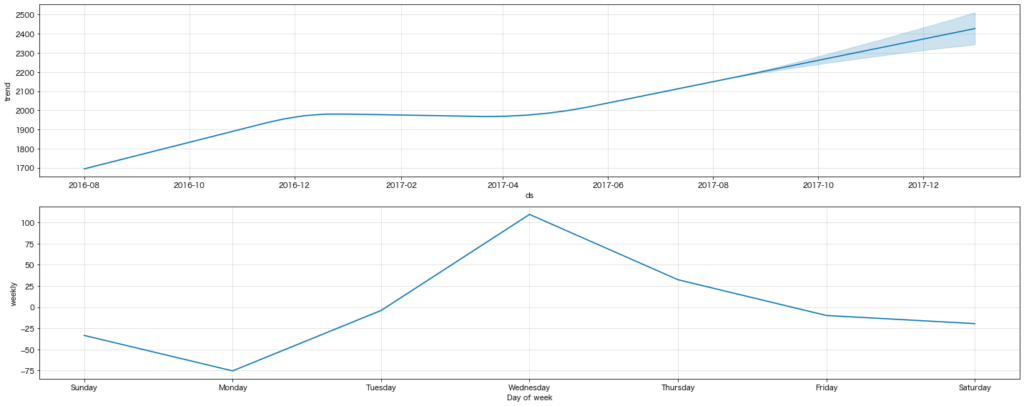
結果の確認:tablet
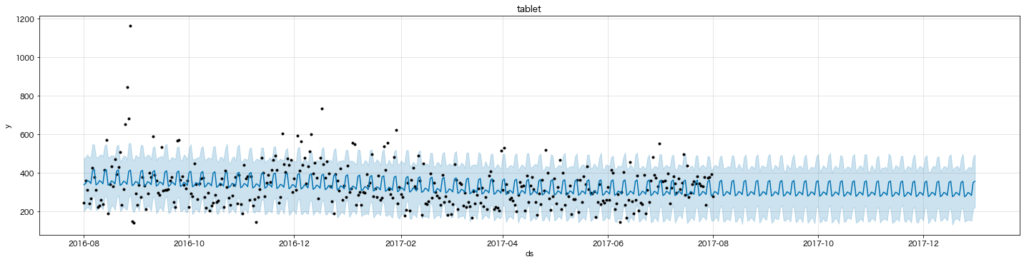
時系列プロットではmobile同様横ばいに見えたtabletですが、こうしてモデリングするとmobileとは異なりダウントレンドであることが読み取れます。また曜日ごとの傾向も異なり、tabletは土日のアクセスが最も多いようです。家でゴロゴロしながら、tabletでネットショッピングを楽しんでいる感じでしょうか。
まとめと次にやりたいこと
今回は時系列予測を実務で使う際に特にポイントとなる、ディメンションで分割したサブモデルの作成を説明しました。
結果を見てもわかる通り、全部ごちゃ混ぜにした坩堝のようなデータで予測モデルを作るよりも、細かく同質化してから予測モデルを作った方がその後のアクションにつながりやすいのではないかと思います。
次にやりたいこととしてはとりあえず以下の3点でしょうか。気分が乗ればまとめます。
- 分散処理による高速化(例えば予測モデルを100個作るとなった時に複数モデルを並列で作成する)
- 冒頭のブログで激推しされているExploratoryではGUI操作だけで同様のモデルが作れるのかどうかを確認
- 最近話題のsalesforce社開発の時系列予測パッケージ「Merlion」(github_salesforce/Merlion)で同様の処理が簡単にできそうか試す












