
「イケボになりたい」は私のようなイケボでない人全員の願いではないだろうか。音響信号処理と呼ばれる技術を駆使することで私たちの声をイケボに変換する方法を、音の基礎から順を追って説明していきたい。
この記事でやること
- 音響信号(音声など)に対して、音程や速度を変化させるといった基本的な処理を実現するための方法と、その問題点を提示。
- 音響波形を周波数領域で捉えるためのSTFT(短時間フーリエ変換)について説明し、音程や速度を変化させる方法を紹介。
コンピュータ上での音響信号の概観
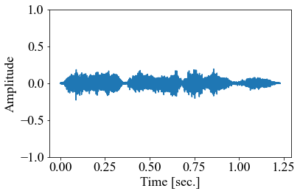
「音は波である」とよく言うように、音のデータはコンピュータ上では時間に対してジグザグした波のような形になっている。例えば、以下のような音声の中身を可視化すると、グラフのようになる(音声は 効果音ラボ のフリー素材から借用)。
※ 自分の声を使おうか少しだけ悩みましたが、思いとどまりました。
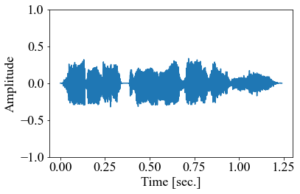 音声データの中身
音声データの中身上のデータでは波であることがわかりづらいが、最初の0.1秒間だけ拡大すると下図のようになり、複雑なジグザグした形がわかる。
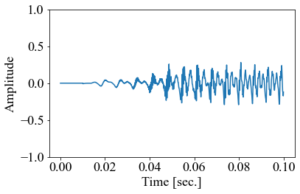 音声データの最初0.1秒部分
音声データの最初0.1秒部分特に人の声は多くの波が重ね合わせてあり複雑だが、基本の成分としては周波数 100~1000 Hz の音域となっている。これはすなわち、1秒間に100~1000回の振動を起こしていることを意味する。
音程と速度を変化させる
イケボと呼ばれるものはたいてい低音ボイスである。羨ましい。
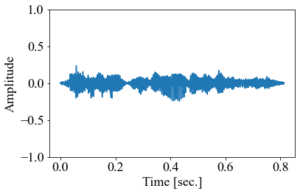
低音ということは音域の周波数が小さいということである。すなわちコンピュータで得られた信号のジグザグの行き来をゆっくりにすれば音が低くなる。先ほどのフリー素材は既にイケボではあるが、ジグザグを引き伸ばしてみよう。
グラフと音声はこのようになる。
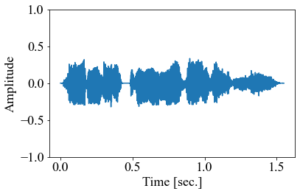 音声データの音を低くしたもの
音声データの音を低くしたもの更なるイケボ(?)になった気がするが、音程を変化させた結果としてほんの少しだけ再生速度も落ちてしまっている。グラフの横軸を見ると分かりやすい(全体の時間が1.25秒程度から1.5秒以上になった)。
スロー再生などで感覚的に理解している人も多いと思うが、このようなシンプルな処理では音程と速度の両方が変化してしまう。確かにゆっくり話した方がイケボ感があるとも言えるが、音程だけを変化させたい時に速度も変わってしまうのはさまざまな面で不便だ。逆に言えば、速度だけゆっくりにさせたい時も必然的に音程が低くなってしまう。
また、音程を上げようとして間隔を狭めると速度が上がる(こちらの方が耳で聴いて速度変化がわかりやすいかもしれない)。
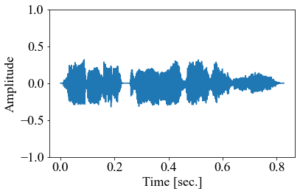 音声データの音を高くしたもの
音声データの音を高くしたもの
STFT による音声信号の変換
今挙げたような課題を解決する手段として、STFT(短時間フーリエ変換)という処理がある。これは下図のように、先ほどの「波の形」の音響信号を、各時間どのような周波数が含まれているかという形式に変換したものである。
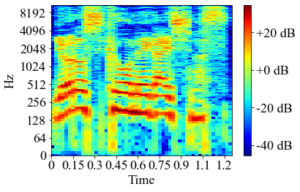 STFTにより変換された音声データ
STFTにより変換された音声データ横軸の各時間において、赤い部分の周波数成分が強く存在するということを示している。感覚としてはカラオケの時に出てくる音程のガイドに近く、赤い部分が上に行っていれば音程が上がっている。
STFT の変換後では、時間と周波数(音程)が別々の軸になっていることがわかる。すなわち、この状態であれば時間がズレることなく周波数だけを変換することが可能だ。具体的には、上図のデータを少しだけ下方向にシフトさせれば良い。上図とほとんど違いはないが、下方向にシフトさせた結果が下図となる。
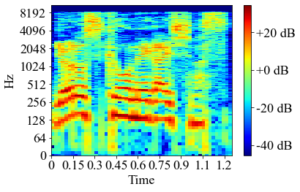 STFT データの周波数シフト後
STFT データの周波数シフト後また、STFT は可逆な変換であり、上図の形式から元の波形の形に戻すこともできるため、シフトさせた後のデータから音程だけが低くなった音声を得ることができる。
 STFTにより音程を低くした音声
STFTにより音程を低くした音声波形から元の音声との違いを見出すことは難しいが、このような処理をすることで速度を変えずにちょっとイケボな音声に変換できることがわかった。
ちなみに、横方向に圧縮/膨張させることで音程を変えずに速度を変えることもできる。圧縮して早口にした結果は以下の通り。
 STFTにより早口にした音声
STFTにより早口にした音声













