まずエレベータの運用ルールを振り返る
最近、機械学習の技術の発展を受けて、エレベーターを効率的に運行させるためにも機械学習を応用する試みがなされています。これを聞くと、「エレベーターの運行って、機械学習を使わなくてはならないほど複雑ではないのでは?」と思う方もいるかもしれません。
この記事は、「混雑緩和」のためにエレベータを増設しても「エレベータがなかなか来ない」という現象をシミュレーションで再現しながら議論していきます。
エレベーターの運行は、日ごろの経験からもわかるように、以下の簡単なルールで表すことができます。
- 誰も待っていなければ動かない
- 誰かが待っていると、その階に向かって移動する
- エレベーター内の行先ボタンに従って移動する
- 移動中に、同じ方向に向かいたい人が待っていたら、ついでに乗せる
- エレベーターの進行方向と逆の方向で待っている人は一旦無視する
上記のシンプルな仕組みであれば、機械学習を使わなくても、「ルールベース手法」で十分なわけです。
機械学習とルールベース手法の違いについては、こちらをご参照ください;
【超優しいデータサイエンス・シリーズ】人工知能と機械学習の関係 – GRI Blog
では、なぜ機械学習を用いた運行最適化が注目されているのでしょうか?
それは、利用者数が多く、それに対処するために複数のエレベーターを併設している場合に起こる、ある厄介な現象に原因があります。その現象とは、「複数あるエレベーターが、お互いに競うように近い階にあって、どれもなかなか来ない」というものです。
エレベータの最適化を数学的に理解
上記の現象を、数学的なイメージで簡単に説明することができます。
ここでは、エレベーターの数は2個と仮定しましょう。
- 最初は、2つのエレベーターは、離れた階に位置しています
- 一方のエレベーター(A)が、もう一方のエレベーター(B)よりも、確率的な現象として、やや多めの客を対応することになったとします
- Aは対応に時間を要し、先に進むのが遅れます。その分、Aが対応しなくてはならない(Aの先で待っている)客の数は増えていきます。
- Aの進行が遅れることで、BはAに接近していきます。これにより、Bが対応しなくてはならない客の数は、Aが対応した後の短い時間内に発生した分のみなので、Aよりも少なくなます。これにより、Bは早く先に進むことができ、Aにますます接近します。
- BがAを追い越してしまうと、この関係が逆転し、AがBに接近しやすくなります。
このように、2台のエレベーターはお互いに競い合ったように近い階に位置しやすくなります。
エレベータの挙動をシミュレーションで検証
今回は、この現象を、乱数を使ったシミュレーションにより検証してみました。シミュレーションにはnumPyパッケージを使用しました。
ルールベースで運用するエレベーターを再現すべく、以下のようなシミュレーションを組みました。
シナリオ1:エレベーターが1台の時の混雑状況
まずは、エレベーター1機の場合で、建物は1~9階の9階建てという設定にしました。
- 単位時間(例えば1秒)あたり、約1/4の確率で新たな待機者が現れます。(厳密には、4/15の確率となっています。アルゴリズムを組む手間の都合上で、深い意味はありません)
- 待機者の出発階と目的階は乱数で1~9の範囲で出力します(出発階≠目的階とする)。
- エレベーターの昇降速度は、単位時間当たり1階分、開閉時間は、昇降人数によらず5単位時間とする。
- エレベーターの乗客定員はないものとする(やや無理のある設定なので、今後アルゴリズム改善の余地あり)
エレベーターは以下のアルゴリズムに従って運行するとします。
(1) 機内に乗客がおらず、かつ誰も待っていなければ動かない
(2) 機内に乗客がおらず、誰かが待っていると、その階に向かって移動する
ここでは、現在地に対して、逆方向に複数人が待機している場合は、直前の移動方向を優先
また、目的階が逆方向となる複数の客が同一階に待機している場合も、直前の移動方向と一致する客を優先
(3) 機内に乗客がいる場合は、その乗客の目的階に向かって移動する
(4) 移動中に、同じ方向に向かう人が待っていたら、ついでに停止し扉が開いて乗せる
(5) 移動中に、逆の方向に向かう人が待っていても、無視して通過する
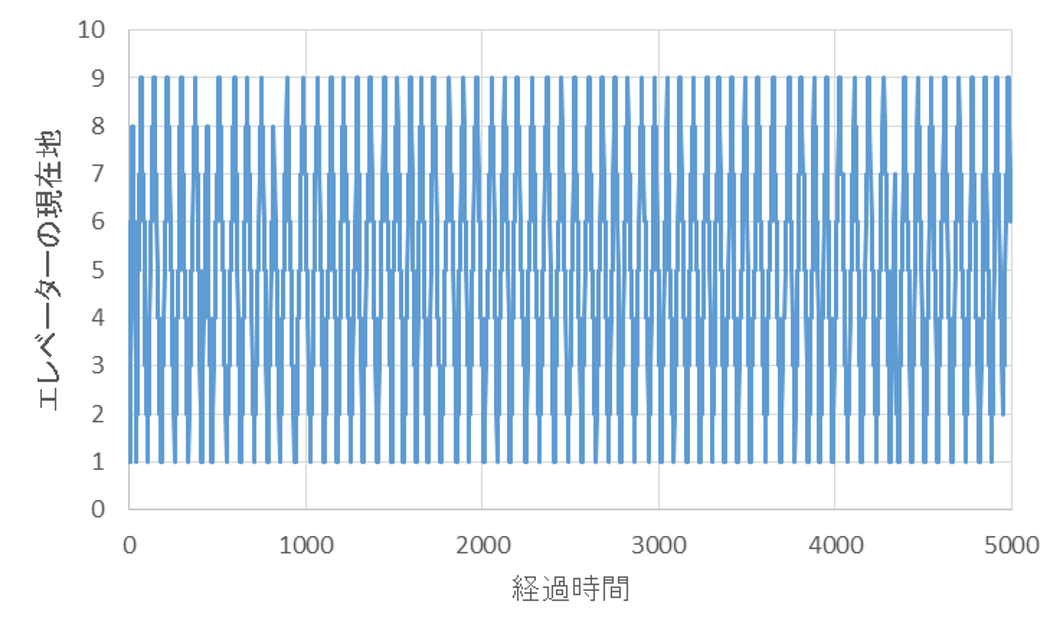
5000単位時間までの、シミュレーション結果は以下の通りとなります。1~9階を常に往復し続けています。
300単位時間までを拡大すると、下記のようになります。
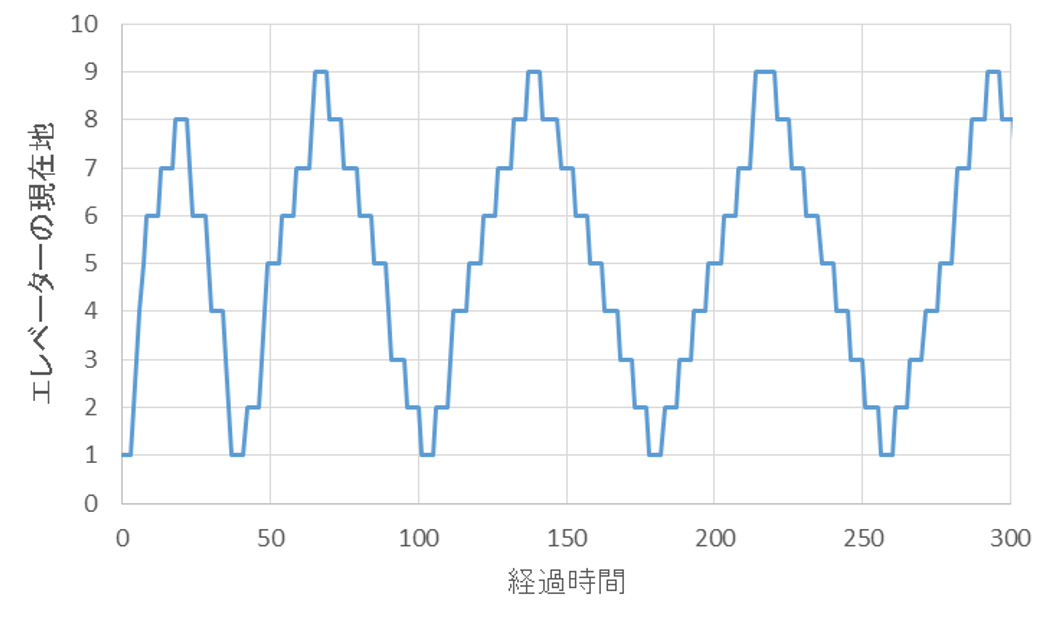
上記の図から、ほぼ各階で止まっていることが確認できます。すなわち、各階で、待機している人、もしくは、降りる人が存在している状況です。相当混雑している様子が伺えます。
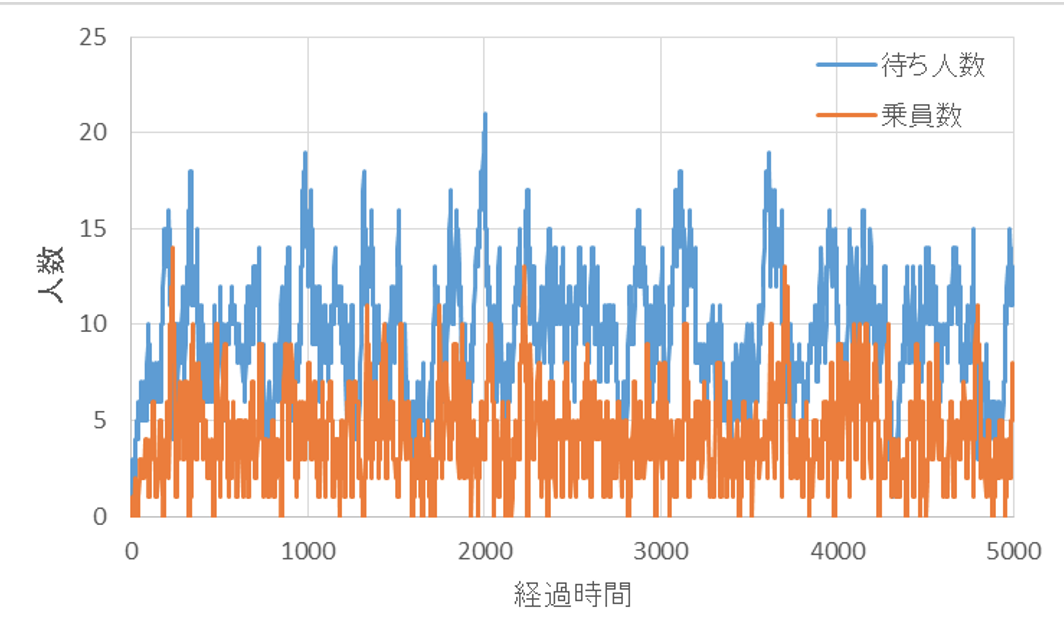
実際に、待っている人数と、エレベーター内の乗員数をプロットすると、下図のようになります。平均9.4人、最大21人が待機していて、エレベーター内には平均4.3人、最大14人が乗っている状況です。これでは快適なエレベーター環境とは言えませんね。

シナリオ2:エレベーター増設すると混雑が緩和される?新たな問題点は?
シナリオ1で作成したアルゴリズムを拡張し、エレベーターを2台に拡張しました。その際、以下のルールを追加しました。
- 2機とも乗客がおらずフリーの時は、1号機が優先し、2号機は動かない。
5000単位時間までの、シミュレーションの結果は以下の通りです。
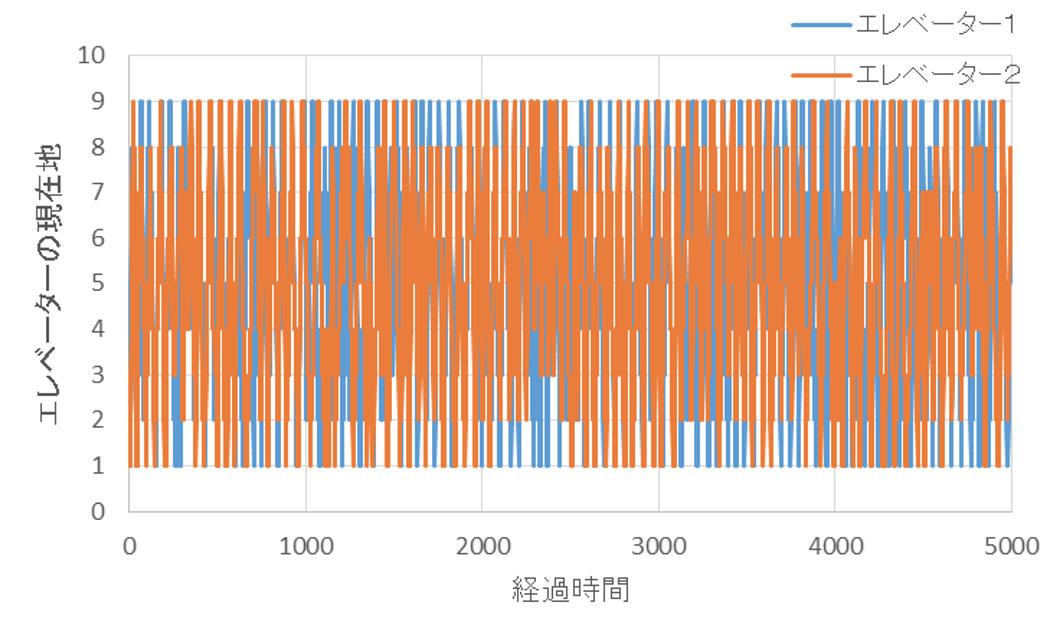
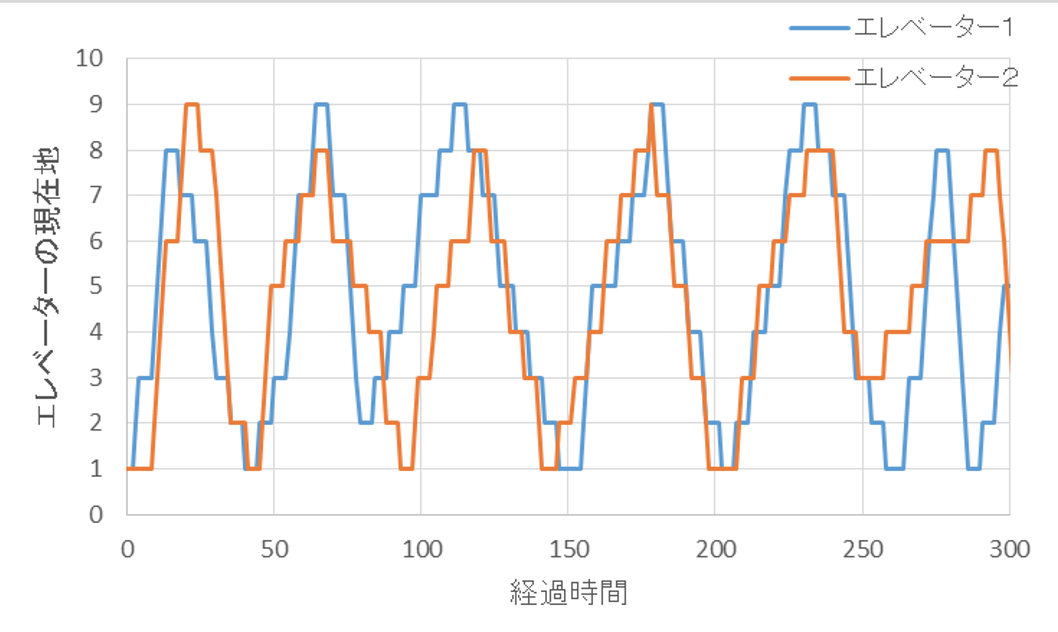
1~9階を常に往復し続けているようですが、この図だけではわかりにくいので、300単位時間までを拡大しました。確かに、最初は1号機から動き出し、2号機はその後に待ち始めた人を対応し始めるのですが、すぐに1号機に追いつき、1号機と2号機はほぼ同調して動いてしまいました。
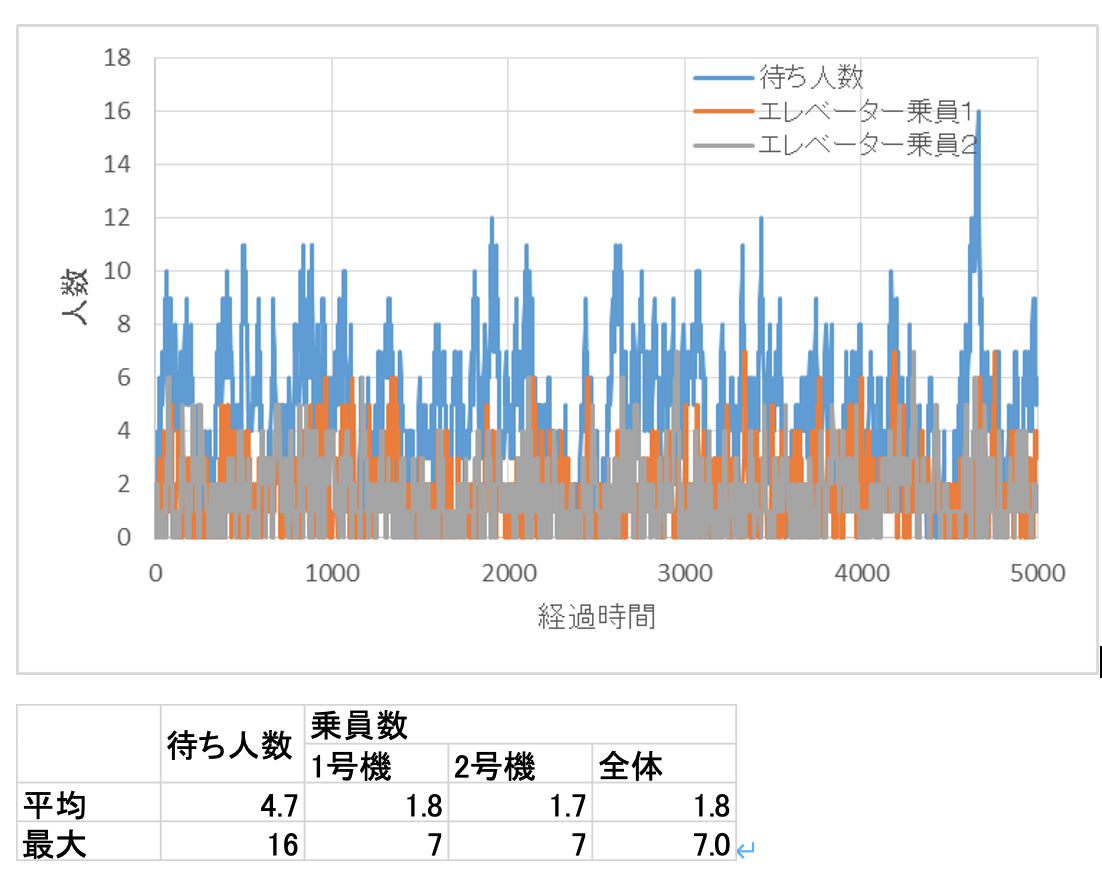
エレベーターの増設の目的は混雑と待ち人数の緩和でしたから、その効果を見てみましょう。
確かに、待機している人の平均は4.7人に減り、エレベーター内の乗員も平均1.8人、最大7人と、混雑が大幅に改善され、混雑緩和という目的は達成しているといえます。
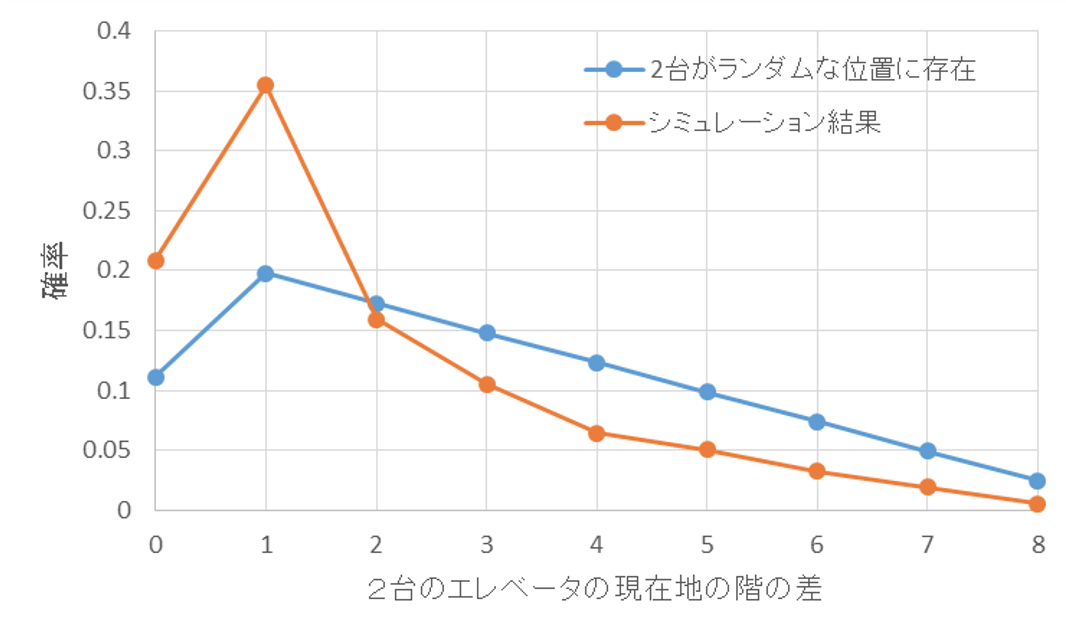
しかしながら、2台のエレベーターが近いところにあって、「なかなか来ない」問題は残っています。実際、この2台のエレベーターはお互いどれくらい近い位置に存在しているのでしょうか?
ここで2台のエレベーターが、それぞれ1~9階のいずれかにランダムな確率で存在するとします。その場合、2台のエレベーターの現在地の差は0~8のいずれかとなり、その確率は下図のようになります。期待値を計算すると、2.96となります。ところが、エレベーターの動作アルゴリズムに従ってシミュレーションを行うと、下図のように、現在地との差が0~1のいずれかである確率がランダムな場合よりも高くなり、期待値は1.87となりました。すなわち、エレベーターを増設すると、2台のエレベーターは近い位置で競い合ってしまう現象が再現できました。
まとめ
今回、簡単なシミュレーションにより、複数のエレベーターが互いに追いかけあう現象を観察してみました。
問題を簡単にするため、以下のような仮定を置き、必ずしも現実を再現できていない部分もあります。
- 乗員定員を定めない→現実には定員オーバーすると乗れない
- 開閉時間は、昇降人数によらず5単位時間→現実には昇降する人が多くなると開閉時間が長くなる
- 出発階と目的階をランダムに等確率で発生させている →現実には、出発階と目的階は1階(または出口のある階)に集中する
しかしながら、冒頭で述べたような「ルールベース」の運用法で発生してしまう「エレベーター同士の追いかけ合い」の本質を再現することには成功したと考えています。この現象は、「待たされている」「なかなか来ない」という不満感をもたらしてしまいます。この不満感を、混雑緩和という重要な目的を損なうことなく、いかに解決するか。その実現のため、機械学習の手法が用いられ、研究されていることを実感できます。
担当者:ヤン・ジャクリン(分析官・講師)