
「連鎖則(Chain Rule)」は誤差逆伝播、つまりニューラルネットワークの学習を理解する上で、非常に重要な基礎概念です。
G検定に頻出の「連鎖則」という概念を聞くと、数学が好きではない方は「G検定では微分や偏微分まで習わないといけないの?」と不安に感じるかもしれません。
もちろん、微分・偏微分の最低限の理解をもっておくと、有利といえます。しかし、連鎖則の本質はそれほど難しいものではなく、ポイントを押さえれば直感的に理解することができます。必ずしも数学を本格的に学ぶ必要はありません。
本記事の以下の説明を通じて、理解できるかどうかをぜひ試してみてください。
G検定では、連鎖則に関して以下の2点を是非意識しておいてください。
- 連鎖則とは、合成関数(複数の関数が入れ子になった関数)の微分(※)を、個々の関数の微分の積(掛け合わせ)で表す法則である。
- 誤差逆伝播は連鎖則に基づいている
- 出力層から入力層に向かって、勾配(誤差の情報)は層をまたいで掛け算によって伝播し、その情報を基に各層の重みを更新している
(※注釈)厳密には偏微分または導関数
ニューラルネットワークと誤差逆伝播
ニューラルネットワークの学習は、次のような流れで行われます。
1)入力データから予測結果を一度出力する(順伝播)
2)予測出力と正解の誤差を計算する
3)出力側から入力側に向かって誤差情報を伝播する(逆伝播)
4)誤差に基づいて各層の重みを更新する
上記のプロセスのうち、連鎖律が関与するのは3)の誤差逆伝播の部分です。
ネットワーク最適化と誤差と微分の関係性
次は上記の4)の重みの更新の部分に着目することで、なぜ「微分」や「勾配の情報」が必要なのかを理解していきます。
「予測出力と正解の間の誤差」を定量的に表すために、損失関数(誤差関数)を使います。損失関数の値は、予測値と正解が近いほど小さくなります。したがって、損失関数を最小化するように、ネットワークのパラメータ(重み)を更新します。最も小さい誤差を実現させてくれるパラメータの組み合わせを最適解と呼びます。
誤差を縮ませるためには、重みを現在の設定値から大きくした方がよいのか、小さくした方がよいのか、これを判断するために、損失関数の「変化量」を調べる必要があります。一般的に関数の最小化問題には「微分」を使います。損失関数を微分し、現在のパラメータ設定値における接線の傾き(勾配)を求めます。そして、誤差が減る方向(損失関数の傾きが負の方向)に重みの値を更新していきます。
連鎖律の考え方
ニューラルネットワークは、数多くの隠れ層から構成されています。
ネットワーク全体を一度に最適化するのではなく、各層ごとに分解して重みを更新することで学習を進めています。つまり、最終的な誤差(損失関数)を小さくするために、途中にある隠れ層ごとに重みをどのように変更すればいいのかを決めなければいけません。
ネットワーク全体の誤差関数は「各層の関数が入れ子になった合成関数」とみなすことができます。上記の通り、誤差を最小化する問題は微分を使います。改めて、連鎖則とはこのような合成関数の微分を、それぞれの関数の微分の積(掛け算)で表す法則です(式1)。
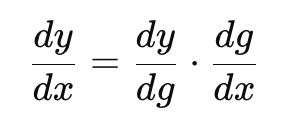
式1 連鎖則の公式。関数yが関数gと入れ子になっており、関数gは変数xに依存する場合、yのxによる微分はyのgによる微分とgのxによる微分の掛け合わせとなる。
誤差逆伝播法では、下流(出力層に近い層)から上流(入力層に近い層)へ、連鎖則に基づいて、各層の微分値(誤差関数の勾配)を順番に掛け合わせていきます。
このように、全体の誤差を各層の重みに対して効率的に求める手法として連鎖律が使われています。
ところで、連鎖則により勾配は層ごとに掛け合わされていくため、以下の問題が生じる原因となります。
- 勾配が小さい値の場合 → どんどん小さくなり、勾配消失が発生
- 勾配が大きい値の場合 → どんどん大きくなり、勾配爆発が発生














