もくもく会とは(初めての方のために)
GRIのデータサイエンスもくもく会とは、人工知能、機械学習、データ分析、Python、ディープラーニング、G検定、数学、統計学など、参加者全員で毎回異なるトピックについて一緒に学び、教養を身につける「オンライン勉強コミュニティ」です。GRIの分析官が講師を務め、皆さんが興味を持ちそうなトピックで講義しながら皆さんと質疑応答を行います。ライブ講義だけではなく、Slack上でもディスカッションを展開しています。
初回の紹介記事:https://gri.jp/media/entry/2409
過去のテーマと順次アップロードしている講義動画はこちらからアクセスできます。
↓↓↓
データサイエンスもくもく会のYoutube playlist
先日12/16(木)には、年内最終回の、第5回目のもくもく会を実施しました(次回年明けは1/13から)。その際に、実践に繋がるトピックであるだけに、数多くの質問をいただき、本記事ではその中からのものをQ&A形式にまとめていきます。参加者の復習にはもちろん、改めに読まれる方も勉強になれればと願っております。
第5回目のもくもく会を振り返る
第5回目のもくもく会のテーマは、[これでバッチリ理解!]シリーズの第3弾です。
『これでバッチリ理解!〜機械学習の活用には特徴量が肝心!特徴量エンジニアリングは何が大変?〜』
機械学習の理解と活用のために大変重要な概念の1つは「特徴量」(feature)です。一言で表すと、特徴量とは、分析対象データの中の、予測の手掛かりとなる変数のことです。また、「特徴量エンジニアリンググ」を通じて、予測変数として採用する列を選別し、データを予測に効果的な形に加工します。学習データの質を高めることが、機械学習モデルの精度と機械学習プロジェクトの成功を大きく左右します。
講義では、以下について説明しました。
・特徴量とは何か:具体例を通じて徹底的に理解しましょう!
・機械学習における特徴量の重要性
・予測精度を高める特徴量エンジニアリング(特徴量設計)
体系的に読みたい方はこちらの記事がとてもおすすめです!
また、第3回目で出題した統計学の面白い宿題について、皆さんからの発表のおかげで盛り上がりましたね。
受講者様と交わした質問・議論
Q1: 欠損値はどうやって処理するのか
講義中でも資料で解説いたしましたが、重要なことなのでここでは改めて…
【Answer】
欠損値とは、データの一部が空白(歯抜け)になっている状態を指します。欠損値の多いデータを機械学習モデルの学習に使っても良い精度が期待できないので、欠損値を適切な方法で処理すべきです。どのように処理すべきかは、欠損値の割合とデータ全体の状態など、ケースバイケースで判断します。
基本的には欠損値のあるデータを捨てるか、代替値で補填するかのどちらかです。1 つの列の欠損値の割合があまりにも大きい場合は、その列を特徴量として使わず、削除することを検討します。また、データ全体にわたって欠損値が多く、残っている非欠損の列だけでは予測の材料として不十分な場合、そのデータセットをそもそも使えないと 判断することもあり得ます。
一方で、欠損値の割合が許容可能で、かつそれらを現実的な方法で埋められそうな時は、欠損値の補填に注力します。
以下、では、特に興味深い、回帰補完で欠損値を補填する方法を紹介します。
●回帰補完のポイント:
- 欠損列と非欠損列の間に相関が強い場合に、回帰を利用して欠損値を埋める方法
- 非欠損データを利用して補充値を推測するモデルを作る
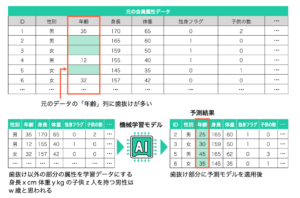
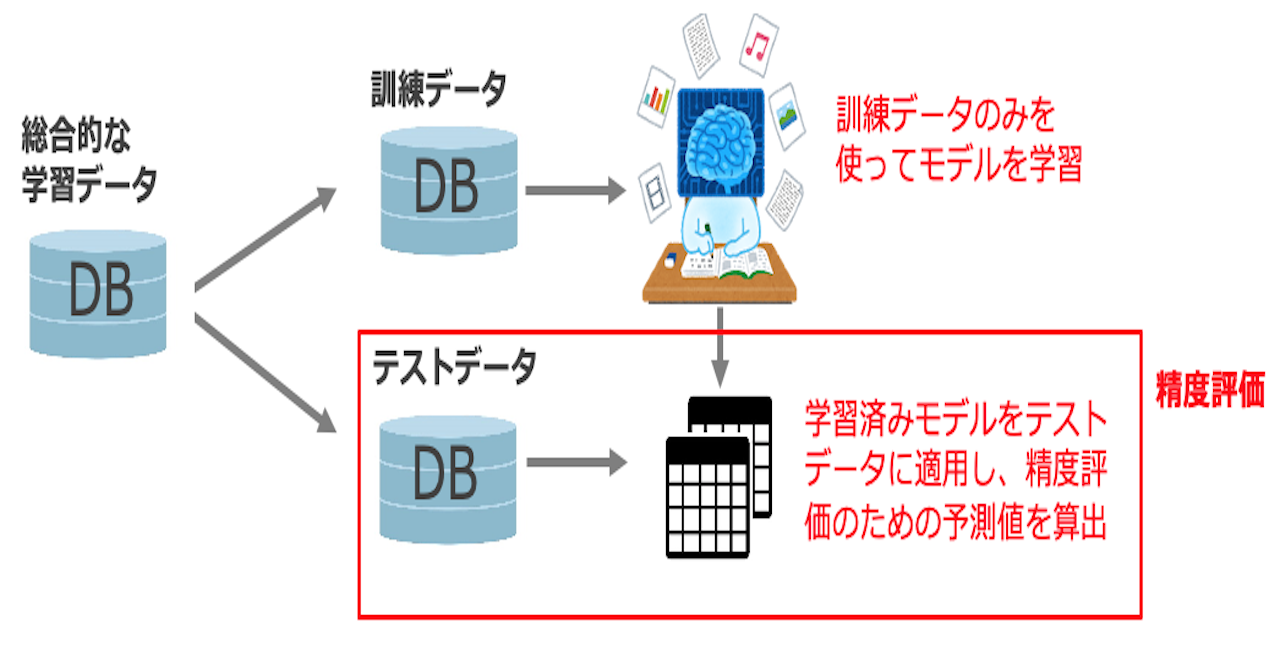
上の図は、回帰補完の具体例です。元の会員属性データの抜けを前処理するのに、 回帰補完を使用するのが適切だと判断したと仮定します。ここでは「年齢」の列に歯抜 けが生じており、他の列を学習データとして用いて、年齢の補填値を推測できる機械学 習モデルを作ります。具体的に、歯抜けなしの年齢が正解ラベルになり、他の列が特徴 量となります。「身長 x cm、体重 y kg の子供 z 人を持つ男性は w 歳と思われる」のような考え方です。
推定モデルの学習が完了したら、歯抜け部分に予測モデルを適用し、元は歯抜けだっ た部分を推定し補填します。最後に、補填後のデータと非欠損のデータを統合し、本題の予測モデルの学習に使います
次の質問も欠損値に関するものです。
Q2: 「会員データにおいて、年齢が20歳で子供が5人、など明らかに疑わしいデータの場合はどうすればいいのか」
【Answer】
もちろん、質問者が描写しているケースは全くありえないというわけではないですが、例えば予測モデルを学習させるのに使う学習データ(明日サービスの会員データとします)にこのケースが現れたら、入力ミスなど不正常を疑ってもいいでしょう。
もし私が分析官としてこのようなデータを観察した場合、以下のようにします。
- 本サービス(例:生命保険)の性質的にこのシナリオは「珍しすぎる」かどうかを直感的に判断
- 他に同様なレアなデータがないか、をデータ全体で確認する
- 発見した「疑わしい」「レア」なデータについて、依頼元のクライアントに確認をとる
- 上記で、「入力ミス」だと判明すれば、次にこの「暗示的欠損値」をどう補えばいいのかを検討する

Q3: 多重共線形(multicollinearity)はどのように避けられますか?
【Answer】
日本語名も英語名も口で言いにくいですね(笑)質問者の方から言われてはじめて知ったのですが、一般的に「マルチコ」と代替表現するのですね。
重回帰分析や決定木系のモデルは、しばしば比較的多数のカラムを持つ構造化データを入力とします。の場合、多重共線性(Multicollinearity)に注意する必要があります。 これは、相関が高い説明変数同士を特徴量として組み合わせた際に、予測精度が悪化する現象を指しています。ですので、機械学習の特徴量を選ぶには、特徴量間の相関の強さに注意しなければいけません。
変数同士の相関の強さの評価法ですが、様々あります。
1つは、「相関係数」を計算した結果、相関係数が 1 ま たは −1 に近い場合、相関が高いといえます。Pythonを使って、簡単に複数の特徴量の間の相関を算出できます。
参考:https://qiita.com/kenTee/items/03285eb311d16c1e08f3
VIF(Variation Inflation Factor)という指標も相関の調査に使います。
参考:https://ichi.pro/tajudomosensei-to-python-de-sore-o-kenshutsusuru-hoho-o-rikaisuru-51822815532764
もう1つは、特に解釈しやすい構造化データの場合、直感的に相関を疑っては、そこをピンポイントで調べることです。講義中に私が出した例は以下です。
お弁当の売り上げを予測するモデルにおいて、「メニュー」のデータがあります。このとき、「揚げ物かどうか」と「カロリーの値」、この2つは直感的に相関が高そうで邪魔し合っている可能性がありますよね。揚げ物は基本的にカロリーが高いので。もしモデルを訓練してみて、思ったほどの精度がでなければ、どちらか1つ(寄与の低い方)を省いてみるといいかもしれません。
Q4:モデルが複雑すぎることを評価するための、評価指標はどのようなものを使えばよいでしょうか。
【Answer】
この質問は、ある意味で、過学習の評価について聞いていることとなります。
講義中では以下を説明しました。
一般的に、モデルが複雑であればあるほど過学習しやすい傾向にある
過学習のよくある原因として以下が挙げられます。
①データ数が少ないのに、特徴量(説明変数)の数が多すぎる
②相関が強い特徴量が多く存在する
③モデルが複雑すぎる(形が複雑な高次元の関数)①に関して、データを増やすことが難しい場合、特徴量の数を減らす、あるいは、本当に「よく効く」特徴量にだけ絞るべき
コンピュータは「どの特徴量をどれだけ重視すればよいのか」がわからなくなるので、 「闇雲にあれもこれも特徴量にしてしまう」は厳禁!
関連性の高い特徴量を組み合わせた「濃厚」な学習データを使うべき
機械学習モデルを学習してみて、新しいデータでテストした際に、思いのほか精度が出なかった場合、上記で説明した「マルチコ」(多重共線形)が過学習を引き起こしている、と疑ってみて、特徴量の選択を見直すといいかもしれません。
厳密に過学習が起きているかどうかを評価するのはもう少し労力がかかります。モデルの古前を制御する「ハイパーパラメータ」を変更した 際に、訓練データに対する精度が良くなっていくのに対して、テストデータに対する精 度が横ばい、または低下する現象が見られれば、過学習を疑っても良いでしょう。
以下の図は、ニューラルネットワークのモデルに対するこの試行の様子です。
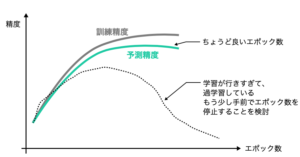
おまけとして、過学習と関係する概念として、バイアスとバリアンスを紹介します。バイア スは、推定値と実測値の差を表します。バリアンスは、推定値のばらつきを表します。 バイアスとバリアンスはトレードオフの関係にあります。どういうことかというと、本来除去不能なばらつきが存在するデータに複雑な モデルを当てはめると、バイアスは低くなりバリアンスが高くなってしまいます。一方 で、シンプルなモデルを当てはめてバリアンスを小さく抑えると、バイアスが高くなっ てしまいます。
過学習になりやすいのは、バイアスが低くてバリアンスが高い状態です。バイアスとバリアンスのバランスをうまく取りながらモデルをチューニングすることが重要です。
Q5:初期段階は、有効かわからない特徴量をすべて使って訓練して、その後にFilter MethodやWrapper Methodなどを使って特徴量を絞り込んでいくのは、良いやり方でしょうか?
【Answer】
そういった「特徴量選択」に特化した方法は確立されています。
一方で、これらは専門性の高い手法であるのもそうですが、せっかくシンプルなモデルを使ってわかりやすい構造化データを分析しているときは、より「すぐに実践し解釈しやすい」やり方を使ってもいいかもしれません。
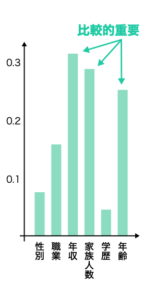
構造化データの分析の王道であるランダムフォレスト(決定木のアンサンブル学習器)を例にとると… Pythonのパッケージの中の関数を使って、特徴量の重要度を可視化することができます(下図)。 ここで特徴量の重要度とは「各変数がどれだけ予測に影響したのか」を示す量です。これが解明できると、特徴量を絞るのにも便利ですし、分析官が分析結果を顧客や上司にプレゼンしやすく、また分析結果をビジネス施策に利用しやすくなります。 例えば、下図ノヨウナわかりやすい可視化を通じて、会員の「年齢」が「サービス契約の有無」に大きく影響する特徴量(変数)であることを証明できれば、特定の年齢層の会員に集中的にアプローチするなど、営業戦略を立案できます。
他にも、特徴量の重要さを構造化データ、画像データについて解明する手法があります。
参考として、最強のテキスト(G検定の緑本)
の4.17節をご参照ください。
以上、講義時間内に答えきれなかったものや説明不足だったものを中心い、いただいた質問の中から、いくつかをピックアップして紹介させていただきました。
本記事の図と内容の一部は、以下の弊著の書籍から抽出しております。
Amazonより:ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[明瞭解説+良質問題]
















