
こちらの記事の後続になります。

とはいえ、別に読んでないと分からない、というわけではなく、必要に応じて参照いただけたらといった感じです。そもそものやりたいことは本記事、その前準備として前回の記事がある、といった位置付けをイメージしていただければ。
目次としてはこんな感じです、さっさとやりかたを知りたい方は一番下の「どうやってやるか」をご覧ください。それでは参りましょう
何を(なぜ)やりたいか
ディメンションごとの全メジャーの平均を出したいということ、あると思います(伝われ)。例えばECサイトでいうと、性別や年代層といったユーザー属性ごとの、購買数・購買金額・etc.の平均を計算したいといったようなイメージです。
これだけであれば「別に普通にやれよ」といった感じなんですが、Matillionのフローに組み込む際には若干考えないといけないケースがあります。
どういったケースかというと、例えば、長めのフローの最初の方でこのメジャーの平均を計算、さらにその計算後のカラムを後のフローで明示的に操作しているようなケースです。
このようなケースで、「Webサイトでの行動情報も追加しよ」となった場合、後続フローのどこを書き換えていいのかぱっと見でわからず、一つ一つのコンポーネントをチェックしていく作業が発生してしまいます。このようなことをしていると、時間もかかる上にミスも起こりやすい。追加したメジャーの平均量が最終出力先テーブルに出力されてないじゃん、といったことがざらに起こり得ます。、、、非常につらいです(体験談)
上で述べたのは一例ではあるのですが、一般的にこのような追加・変更に対して、修正点がわかりやすいかつ最小で済む、いわゆる拡張性が高いことはあらゆるシステムにおいて超重要なポイントではないでしょうか。そうでないと、メンテナンス性能が劇的に下がるだけでなく、アドホックな分析をしている時でさえも、いちいち修正が鬼のように発生してミスも多いし全然進まないといったことがままあります。、、、非常につらいです(体験談2)
そこで今回は、その拡張性を高める一つのやり方として、上記のような「特定テーブルの全メジャーの平均を出したい」といったときに、Matillion上のpythonコンポーネントからクエリを発行する方法をご紹介いたします。
データセットの用意
まずは上述のケースを再現するための簡単なデータセットを準備していきましょう。
元データとしてBigQuery用のGoogleAnalyticsサンプルデータセットを利用し、こちらのヘルプページを参考にしつつ、日次でセッション・PV・トランザクションの合計数を計算していきます。
後ほど使うため、月を表すカラム(year_month)を追加しておきましょう。
出来上がったクエリはこちら↓
SELECT date, LEFT(date, 6) AS year_month, SUM(totals.visits) AS visits, SUM(totals.pageviews) AS pageviews, SUM(totals.transactions) AS transactions, --SUM(totals.transactionRevenue)/1000000 AS revenue FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20160801' AND '20170731' GROUP BY date ORDER BY date ASC
結果はこんな感じ↓
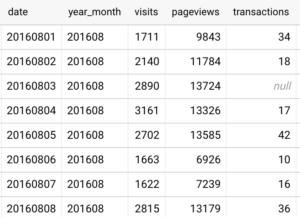
visitsがセッション数、pageviewsがPV数、transactionsがトランザクション数を表します。
このデータセットを使って、月ごとの全メジャーの平均量を計算するクエリを、pythonコンポーネントから実行していきます。
どうやってやるか
手っ取り早く、まずは実際のコードをお見せいたしましょう
pythonコンポーネントをセットして↓
中身はこんな感じ↓
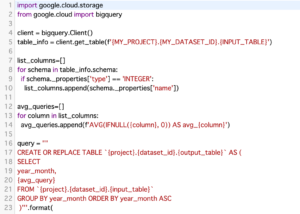
コードは以下の通りです↓
import google.cloud.storage
from google.cloud import bigquery
client = bigquery.Client()
table_info = client.get_table(f'{MY_PROJECT}.{MY_DATASET_ID}.{INPUT_TABLE}')
# 1. 集計対象となる数値型のカラムのみリストアップ
list_columns=[]
for schema in table_info.schema:
if schema._properties['type'] == 'INTEGER' or schema._properties['type'] == 'FLOAT':
list_columns.append(schema._properties['name'])
# 2. リストアップしたカラムについて平均を計算するクエリ文を作成
avg_queries=[]
for column in list_columns:
avg_queries.append(f'AVG(IFNULL({column}, 0)) AS avg_{column}')
# 3. 年月(year_month)ごとにメジャーの平均を計算して、別テーブルに格納するクエリの発行
query = '''
CREATE OR REPLACE TABLE `{project}.{dataset_id}.{output_table}` AS (
SELECT
year_month,
{avg_query}
FROM `{project}.{dataset_id}.{input_table}`
GROUP BY year_month ORDER BY year_month ASC
)'''.format(
project = MY_PROJECT,
dataset_id=MY_DATASET_ID,
input_table=INPUT_TABLE,
output_table=OUTPUT_TABLE,
avg_query=',\n'.join(avg_queries)
)
# 4. クエリの実行
query_job = client.query(query)
query_job.result()やっていることは単純で、以下のような流れです。
(1)こちらの記事でやったように、まずはテーブルから数値型のカラムだけリストアップ
(2)リストアップしたカラムに対してループを回し、平均を計算するクエリ文を作成、それをavg_queriesに順次追加していく
(3)年月(year_month)ごとにメジャーの平均を計算して、別テーブルに格納するクエリを発行。その中で(2)で用意したavg_queriesをavg_query=’,\n’.join(avg_queries)のようにバラして入れる
(4)クエリを実行
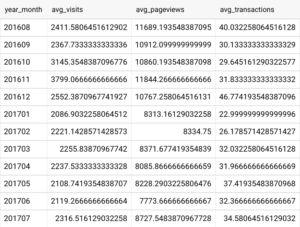
結果はこのような感じになります(1ヶ月当たりの平均〇〇が求まってます)↓
拡張性という観点を確認しておくと、例えばですが、「収益も見たいなあ」となったときを考えてみましょう。
データセットの準備でお見せしたクエリのコメントアウトを外し、収益(revenue)を追加します。クエリを実行し用意したテーブルに対して、先程のpythonコンポーネントを再度実行すると結果は以下のようになります↓
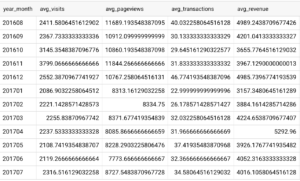
ちゃんと収益の平均も追加されていることがわかりますね〜
今回は一例として「全メジャーの平均を出す」やりかたをご紹介いたしました。
この例に限らず、python上でコーディングできる以上、「ループを回して様々な閾値に対してフラグ付けを行う」だったり「カラム名が〇〇から始まる列だけこの処理を施す」などかなり柔軟にクエリを発行することができます。はっきり言って飛べます。
あとは皆様のやりたいように書き換えていただけたら、拡張性の高いフローが出来上がるのではないでしょうか。
ぜひお試しを!















